注意力机制——注意力评分函数(代码+详解)
目录
-
-
- 注意力分数
-
- 关于a函数的设计有两种思路
-
- 1.加性注意力(Additive Attention)
- 2.缩放点积注意力(Scaled Dot-Product Attention)
- 模块导入
- 遮蔽softmax操作
- 加性注意力代码:
-
- 补充知识:
-
- 1.torch.repeat_interleave(data, repeat= , dim=)
- 2.torch.nn.Linear(*in_features*, *out_features*, *bias=True*, *device=None*, dtype=None)
- 3.torch.nn.Dropout(p=0.5, inplace=False)
- 4.Tensor.repeat()
- 5.model. train()和model. eval()
- 缩放点积注意力代码
-
注意力分数
以高斯核为例,注意力分数为高斯核的指数部分,即:-1/2 * (x - xi)^2
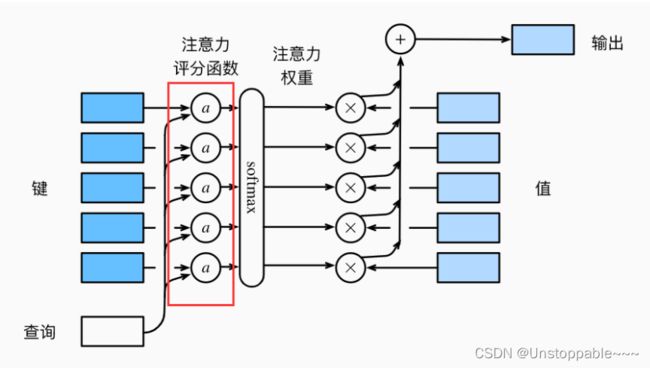

选择不同的注意力评分函数a会导致不同的注意力汇聚操作。 在本节中,我们将介绍两个流行的评分函数,稍后将用他们来实现更复杂的注意力机制。
关于a函数的设计有两种思路
1.加性注意力(Additive Attention)

2.缩放点积注意力(Scaled Dot-Product Attention)
使用点积可以得到计算效率更高的评分函数, 但是点积操作要求查询和键具有相同的长度dd。 假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为d。 为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 我们将点积除以根号d则缩放点积注意力(scaled dot-product attention)评分函数为:


总结:
- 注意力分数时query和key的相似度,注意力权重时softmax的结果
- 两种常见的分数计算
- 将query和key合并起来金瑞一个单输出单隐藏层的感知机
- 将query和key直接做内积
模块导入
import math
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
遮蔽softmax操作
softmax操作用于输出一个概率分布作为注意力权重。 但是在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。
例如,某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 我们可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。 通过这种方式,我们可以在下面的masked_softmax函数中 实现这样的掩蔽softmax操作(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
通俗来讲:给定一个长度为10的序列,我认为后六个数据没有参考价值,随后进行masked_softmax操作,只保留前四个作为有效值进行softmax操作,其余值默认为0.
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None: #不设置时,取全部值的softmax
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape #将shape保存下来,以便取用其中的行列的维度数,以及最终恢复原样
if valid_lens.dim() == 1: #当valid_lens为一维
#若x的维度为(2, 2, 4) 得到第二个维度的数值2,并将valid_lens复制2次,得到一个
valid_lens = torch.repeat_interleave(valid_lens, shape[1]) #经过这一步[2, 3]会变为[2, 2, 3, 3]
else:
valid_lens = valid_lens.reshape(-1) #直接将其变为一维
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
#X.reshape(-1, shape[-1])将X展开为n行4列,n在这里为2*2,形状为(4, 4) 再对每一行进行2, 2, 3, 3的掩码操作
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, value=-1e6) #得到的X是一个展开的二维张量
return nn.functional.softmax(X.reshape(shape), dim=-1)
a = masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
#输入:batch_size为2,每个batch为(2, 4) 遮蔽:第一个batch取前两个,第二个batch取前三个,其余值为0 再进行softmax
print(a)
b = masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
#遮蔽: [1, 3]表示第一个batch的第一个元素取第一列,第二个元素取前三列,[2, 4]表示第二个batch中第一个元素取前两列第二个元素取前四列,进行softmax
print(b)
#tensor([[[0.4500, 0.5500, 0.0000, 0.0000],
# [0.5731, 0.4269, 0.0000, 0.0000]],
# [[0.2377, 0.4788, 0.2835, 0.0000],
# [0.3471, 0.4405, 0.2124, 0.0000]]])
#tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
# [0.2046, 0.3279, 0.4676, 0.0000]],
# [[0.3510, 0.6490, 0.0000, 0.0000],
# [0.2069, 0.2177, 0.3270, 0.2485]]])
加性注意力代码:
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
#输入k维输出h维
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
#输入q维输出h维
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
#输入h维输出1维
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
# 以p=dropout的概率进行正则化
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
"""
:param valid_lens: 对每一个query 考虑前多少个key-value对
:return:
"""
#queries维度(bathc_size, q_num, h) keys维度(bathc_size, k_num, h)
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后, (在这里需要将每一个query和每一个key加在一起)
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
#得到的features维度为(bathc_size, q_num, k_num, h)相当于每个q和k都做了求和
features = torch.tanh(features) #激活
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1) #squeeze(-1)把(batch_size, q, k, 1) 最后有一个维度上的1去掉
self.attention_weights = masked_softmax(scores, valid_lens) #过滤掉不需要的k-v对
# bmm为批量矩阵乘法,其中第一个参数的形状为:(batch_size, q, k)
# values的形状:(batch_size, k, v) 二者进行批量矩阵乘积得到(b, q, v)
return torch.bmm(self.dropout(self.attention_weights), values)
#训练
#query的batch_size为2,1个query.query长度时20 key的batch_size为2,有10个key, key的长度是2
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# 有10个value,value的长度为2 进行一次复制变为(2, 10, 4)
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval() #开启评估模式
# a:(2, 1, 4) 即(b, q, v)
a = attention(queries, keys, values, valid_lens)
print(a)
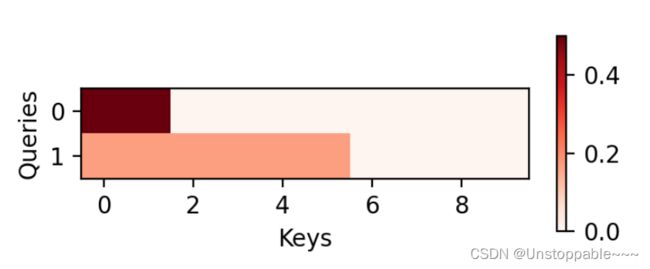
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
plt.show()
weights的热图(某个query对于k-v对的注意力大小/重视程度大小)如下所示:
第0个样本的权重给了前两个key(query0更加重视前两个键值对)
第1个样本的权重给了前六个key(query1更加重视前六个键值对)
由于本例子中每个键都是相同的, 所以注意力权重是均匀的,由指定的有效长度决定。
补充知识:
1.torch.repeat_interleave(data, repeat= , dim=)
功能:对data张量的dim维度复制repeat次
特例:
a = torch.Tensor([2, 3, 4])
b = torch.repeat_interleave(a, 4) #相当于对dim=0进行复制
print(b) #tensor([2., 2., 2., 2., 3., 3., 3., 3., 4., 4., 4., 4.])
2.torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
对传入的数据应用线性转换: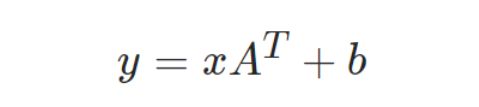
-
In_features -每个输入样本的大小
-
Out_features -每个输出示例的大小
-
bias -如果设置为False,该层将不会学习加性bias。默认值为False
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())
#torch.Size([128, 30])
通过训练集不断地训练,逐渐学习到参数A和b,并在输入测试集时得到较为正确的预测结果。
3.torch.nn.Dropout(p=0.5, inplace=False)
相当于加入正则项,用于解决过拟合问题
其作用是,在 training 模式下,基于伯努利分布抽样,以概率 p 对张量 input 的值随机置0;
training 模式中,对输出以 1/(1-p) 进行 scaling,而 evaluation 模式中,使用恒等函数;
参数:
-
p:默认 0.5,张量元素被置0的概率;
-
inplace:默认 False,是否原地执行;
torch.nn.Dropout(0.5)
这里的 0.5 是指该层(layer)的神经元在每次迭代训练时会随机有 50% 的可能性被丢弃(失活),不参与训练,一般多神经元的 layer 设置随机失活的可能性比神经元少的高。
4.Tensor.repeat()
可以对张量进行重复扩充。
import torch
a= torch.arange(30).reshape(5,6)
print(a)
print('b:',a.repeat(2,2))
print('c:',a.repeat(2,1,1))
当参数只有两个时:(列的重复倍数,行的重复倍数)。1表示不重复
当参数有三个时:(通道数的重复倍数,列的重复倍数,行的重复倍数)
5.model. train()和model. eval()
设置了训练或者测试模式,定义模型是否需要学习。对部分层有影响,如Dropout和BN。
具体影响如下:
-
Dropout: 训练过程中,为防止模型过拟合,增加其泛化性,会随机屏蔽掉一些神经元,相当于输入每次走过不同的“模型”。这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
比如,有1000个神经元,p=0.4,我们dropout比率选择0.4,在训练的时候,这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
而在测试时,应该用整个训练好的模型,因此不需要dropout。
-
BN:batch normalization,是对数据的规范化,使每层的数据输入都保持在相近的范围内。BN和核心计算公式:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E7jFV0Tp-1644210520659)(C:\Users\pc\AppData\Roaming\Typora\typora-user-images\image-20220207123613041.png)]
在训练时,由于是一个batch一个batch的给模型投喂数据,模型只能计算当前batch的均值和方差,当所有的batch都投喂完成,模型对每个batch上的均值和方差做指数平均,来得到整个样本上的均值和方差的近似值。
在预测时,一般不必要去计算的均值和方差,比如测试仅对单样本输入进行测试时,这时去计算单样本输入的均值和方差是完全没有意义的。因此会直接拿训练过程中对整个样本空间估算的均值和方差直接来用。
总结:model.eval() :不启用 BatchNormalization 和 Dropout,实际作用相当于self.train(False)
缩放点积注意力代码
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
#queries和keys的最后一维都为d
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度 (b, q, d) * (b, d, k) = (b, q, k)
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
#部分参数沿用加性注意力中的参数
b = attention(queries, keys, values, valid_lens)
print(b)
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
plt.show()
weights的热图如下所示:
