Blitz-SLAM:A semantic SLAM in dynamic environments
摘要:静态环境是大多数视觉同步定位和测绘系统的前提条件。如此强烈的假设限制了大多数现有SLAM系统的实际应用。当运动物体进入摄像机视场时,动态匹配点会直接中断摄像机定位,运动物体形成的噪声块会污染所构建的地图。本文提出了一种工作在室内动态环境中的语义SLAM系统——Blitz-SLAM。结合掩模(mask)、RGB和深度图像的语义和几何信息优势,去除局部点云中的噪声块。通过合并局部点云得到全局点云图。
我们在TUM RGB-D数据集和现实环境中对Blitz-SLAM进行了评估。实验结果表明,Blitz-SLAM算法能够在动态环境下稳健工作,同时生成干净、准确的全局点云图。
同步定位与测绘(SLAM)在无人驾驶系统的导航和人机交互中起着重要的作用。现有的视觉SLAM系统大多是基于静态环境的假设,这极大地限制了这些系统在现实世界中的应用,如在繁忙道路上的自动驾驶。当运动物体进入摄像机视场时,运动物体上的匹配点将直接干扰摄像机的姿态估计,运动物体的信息将保留在构造的图像中。SLAM系统在动态场景中正常工作的主要思想是定位环境中稳定的静态特征,以进行相机定位。RANSAC(Random Sample Consensus)方法是SLAM系统在静态或低动态场景中去除不匹配的最具代表性的方法。然而,RANSAC不能保证在高度动态的环境中消除这些不匹配。
近年来,在目标检测和分割方面取得了很大的突破。许多研究者试图将SLAM与深度学习相结合,构建适应动态环境的语义SLAM系统。将预先定义的运动对象的语义信息与空间几何信息相结合,可以去除运动对象的负面影响。预定义的移动对象通常是常规的,如人、汽车、动物等。事实上,目前的语义分割方法所提供的对象原始掩码是不完善的,不能完全覆盖移动的对象,特别是对象边界。边界信息会泄露到点云图中,形成大量的噪声块。
本文提出了一种适用于室内动态环境的新型人工SLAM系统——Blitz-SLAM。Blitz-SLAM采用基于特征点的最完整、最简单的SLAM系统之一ORB-SLAM2[2]作为全局SLAM方案。我们的移动物体移除方法与ORB-SLAM2前端集成在一起。在Blitz-SLAM中,BlitzNet[3]用于获取环境中对象的语义信息。
BlitzNet是一种实时深度神经网络,可以在一次正向传播中同时获取物体的边界框和掩码。利用运动物体的边界框将图像快速划分为环境区域和潜在动态区域。利用环境区域中匹配点构造的极域约束,可以定位潜在动态区域中的静态匹配点。利用深度图像的几何信息对原始掩模进行修正,使其能更完整地覆盖运动物体。改进后的掩模去除了局部点云中的噪声块。通过合并这些局部点云,可以得到一个干净的全局点云图。本文的主要贡献如下:
1、提出了一种将目标的原始掩模与深度信息相结合的方法来获取目标的修正掩模。
2、我们提出了一种消除点云图中运动物体形成的噪声块的方法。
3、针对移动对象在全局点云图中多次出现的问题,提出了一种解决方案。
1、Dynamic SLAM without prior-known moving-object information
寻找可靠的静态匹配特征是没有已知运动目标信息的动态SLAM系统的基本任务。
Sun等人[4]提出了一种基于RGB-D数据的运动去除方法作为过滤运动对象的预处理模块。该工作是动态SLAM领域的开创性工作之一。[4]的后续工作包括两个在线并行的过程:建立和更新前台模型的学习过程;面向前景像素分割的推理过程[5]。
DMS-SLAM[6]采用滑动窗口模型在两个不连续帧之间进行特征匹配,采用GMS [7](Grid-based Motion Statis- tics)过滤异常值。
Li[8]等人提出的RGB-D SLAM系统采用静态加权方法计算每个关键帧点作为静态环境一部分的相似度。局部保持匹配LPM(Locality Preserving Matching,LPM[9])能够保持真匹配的局部邻域结构。
LMR [10](learning for Mismatching Removal)将错配去除问题转化为一个两类分类问题,学习一个通用分类器来识别内值和异常值。
为了克服自然地标对快速运动、大视点变化和显著场景变化不鲁棒的缺点,Rafael等人提出了一种基于平面平方标记检测的离线SLAM系统[11]。SPM- SLAM[12]和UcoSLAM[13]是该系统的延续。SPM-SLAM是一个实时的系统,它解决了以前的系统遗留下来的许多问题,如映射初始化、从模糊观测中估计标记的位置、用标记检测环路闭合等。UcoSLAM融合关键点和平方基准标记,在重复的环境中实现长期的鲁棒跟踪。
2、Semantic SLAM in dynamic environments
语义分割网络得到的掩码可以标记出图像中运动物体的区域,为动态SLAM的构建提供先验信息。DynaSLAM[14]将多视图几何和掩码相结合的方法去除预定义的运动目标,提出了一种背景填充方法来填充被遮挡的背景。DynaSLAM II[15]可以同时估计出摄像机姿态、稀疏静态三维地图和多个运动物体的轨迹。并提出了一种新的束调整方法来联合优化静态场景的结构和动态对象的姿态。MaskFusion[16]采用几何分割产生精确的对象边界,克服了语义分割提供的不完美边界的缺点。MID-Fusion[17]可以提供环境中对象的几何、语义和运动属性。DS-SLAM[18]剔除图像中的人物区域,利用移动一致性消除动态匹配点。DP-SLAM[19]在贝叶斯概率估计框架下跟踪动态匹配点,克服几何约束偏差和语义分割。
一些研究人员利用潜在移动物体的边界框来去除这些物体,而不是使用掩码。DetectSLAM[20]采用传播四类关键点移动概率的策略,克服语义信息的延迟。Dynamic-SLAM[21]采用漏检补偿算法,解决现有SSD网络召回率低的问题。CubeSLAM[22]从基于消失点的2D边界框生成3D边界框,并通过物体表示和运动模型约束改进了相机姿态估计。
3、Object detection and semantic segmentation networks
Mask-RCNN[23]是目前语义SLAM系统中常用的实例分割方法之一,如DynaSLAM[14]、MaskFusion[16]、MID-Fusion[17]、DP-SLAM等。虽然Mask-RCNN令人印象深刻,可以提供良好的对象掩码,但算法不能实时运行。一些语义SLAM系统,如DS-SLAM[18],利用SegNet[24]获取对象的掩码,可以实时提供像素掩码。DynaSLAM II[15]基于很多人造物体都可以放入一个3D边界盒的假设,采用CNN 2D边界框对计算出的3D边界框进行优化,文献中提到使用YOLACT[25]可以实时提供高质量的实例分割。
YOLO [26](You Only Look Once)和SSD [27](Single Shot MultiBox Detector)是语义SLAM系统构建中比较流行的两种对象检测网络,因为这两种检测器在速度和精度之间取得了很好的平衡。CubeSLAM[22]采用YOLO检测器用于室内场景,DetectSLAM[20]和Dynamic-SLAM[21]采用不同的策略对现有SSD检测器进行改进,以满足特定的任务需求。
事实上,许多优秀的语义分割网络都可以与SLAM相结合。Unet[28]提出了从收缩路径到扩展路径的跳过连接的编码器-解码器架构。BiSeNet[29]将空间信息保存和接受场提供的功能解耦为空间路径和上下文路径。BiSeNet V2[30]提出了一种双路径体系结构,将低级细节和高级语义分开处理,并设计了一个引导聚合层来合并这两个特性。DeepLab v3[31]使用阿特鲁卷积(atrous convolution)和上采样滤波器来提取密集的特征映射和捕获长范围上下文。DeepLab v3+[32]扩展了DeepLab v3,添加了一个简单而有效的解码器模块来恢复对象边界。
随着SLAM传感器的发展,利用多模态图像构建语义分割网络是一种趋势。FuseNet[33]将深度信息作为外观信息的补充加入到语义分割框架中。深度感知CNN(Depth-aware CNN)[34]通过引入深度感知卷积和深度感知平均池化操作来处理几何信息。MFNet[35]利用多光谱图像实现了城市场景的语义分割,并发布了RGB-Thermal数据集作为该方法的基准。RTFNet[36]利用了不满足光照条件下热图像质量不会下降的优点,将RGB和热信息集成到一个深度神经网络中。
4、Differences from related works
与现有的大多数动态SLAM系统专注于提高相机定位精度不同,我们的工作专注于构建一个能够在动态环境中获得干净、准确的点云图的SLAM系统。实验中使用的深度图像存在一些深度缺失区域,不适合使用多模态网络对RGB-D图像进行语义分割。和上面提到的大多数语义SLAM系统一样,我们只对RGB图像进行语义分割,在平衡了性能和实时性之后,我们选择了BlitzNet[3]。其他语义分割网络得到的原始掩码也可以与我们的方法相结合,构建无噪声块的点云图
与Blitz-SLAM最相似的SLAM系统是[37]中提出的工作。据我们所知,这是第一个旨在消除运动物体形成的噪声块的动态SLAM系统。但是,该系统并没有解决环境点被对象语义信息污染的问题,因此系统无法构建出合适的语义图。它的另一个缺点是掩码的扩展被限制在运动对象的边界框内,这直接导致扩展的掩码不能有效的覆盖运动对象的区域。与[37]不同的是,Blitz-SLAM充分利用了原始掩码、RGB和深度图像的语义和几何信息,得到了深度掩码和修正掩码两种掩码。将深度掩码的语义信息映射到点云图上,生成语义图。改进后的掩码可以完全覆盖运动物体的区域。
(与Blitz-SLAM最相似的SLAM系统是[37]中提出的工作。据我们所知,这是第一个旨在消除运动物体形成的噪声块的动态SLAM系统。但是,该系统并没有解决环境点被对象语义信息污染的问题,因此系统无法构建出合适的语义图。它的另一个缺点是掩码的扩展被限制在运动对象的边界框内,这直接导致扩展的掩码不能有效覆盖运动对象的区域。与[37]不同的是,Blitz-SLAM充分利用了原始掩码、RGB和深度图像的语义和几何信息,得到了深度掩码和修正掩码两种掩码。将深度掩码的语义信息映射到点云图上,生成语义图。改进后的遮罩可以完全覆盖运动物体的区域。)
System description
5、Overview of blitz-SLAM
我们提出的语义SLAM系统的概述如图1所示。该系统首先将RGB图像输入BlitzNet,通过BlitzNet同时获取环境中物体的边界框和原始掩码。BlitzNet使用ResNet-50作为骨干网,因为它的高性能和良好的速度权衡。BlitzNet在PASCAL VOC (VOC2007, VOC2012)数据集[38]上进行了训练,共可以分割和检测出20个类。BlitzNet可以检测到普通室内场景中常见的东西,如人、家具等。
根据物体在环境中的状态,物体大致可以分为三类:
1. 移动的物体:如行走的人。这些物体不仅直接干扰了相机的姿态估计,而且在构建的环境图中留下了大量的污点。
2. 静态对象:如表、监视器等。这些对象通常位于环境中的相同位置,不会频繁移动。
3.可移动物体:如椅子、书等。这些对象可以是移动的,也可以是静态的。

图1所示,Blitz-SLAM概述。RGB图像经过BlitzNet,同时获得环境对象的原始掩码和边界框,如紫色箭头所示。橙色箭头表示获得无噪声块的局部点云的步骤。蓝色箭头表示匹配点的分类过程,静态匹配点用于摄像机定位。青色箭头表示在准确估计相机姿态后,将局部点云拼接得到全局点云图。
由于BlitzNet获得的原目标掩码不完善,利用目标区域的深度信息对原掩码进行改进,得到能够完全覆盖目标区域的修正掩码。去除运动物体引起的噪声块后,即可得到清晰的局部点云。在图1中,流用橙色箭头标出。
在摄像机定位过程中,利用运动物体的边界框可以快速将图像划分为环境区域和潜在动态区域。利用环境区域的匹配点构造极线约束,对潜在动态区域的静态匹配点和动态匹配点进行分类。然后利用静态匹配点进行摄像机定位。图1中用蓝色箭头标出了流。
图1中的青色箭头表示构建全局点云图的过程。构建全局点云图的实质是将每组关键帧对应的局部点云进行合并,具体如下:

其中Pi表示局部点云,PE表示全局点云图,旋转矩阵Ri和平移矩阵ti由相机相对于参考坐标系的姿态决定。通常选择第一组关键帧的摄像机坐标系作为参考坐标系。
全局点云图的质量与三个因素有关:摄像机定位精度、局部点云中噪声块的去除和被跟踪摄像机轨迹的完整性。
6、Depth region segmentation
由于深度相机的限制,深度图像中的某些区域会失去其深度值。而当物体表面非常光滑时,物体的深度值也会严重缺失。
基于场景中的物体,尤其是人造物体在很大程度上是凸起的假设,边缘点可以放置在深度图像中的不连续处[16]。我们的深度图像分割方法如下:
使用大小为2*2的滑块遍历深度图像,记录滑块内的深度值,如下所示:

其中(u, v)为滑块左上角像素对应的图像坐标。边缘点可由一下方式获得:
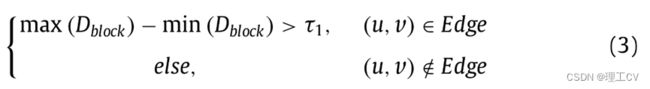
其中τ1为预先设定的阈值,在本文中τ1=500(0.1m), Edge表示边缘点集合。
7、Removal of depth unstable regions
深度相机的精度随着物体与相机之间距离的增加而降低。为了观察深度不稳定区域对点云的影响,我们从TUM数据集中选取一组RGB和深度图像,得到局部点云,如图2所示。从正面看,远处木板的点云比写字台木板的点云占据更大的区域。从俯视图看,远处木板的点云有严重的分层现象,而写字台木板的点云则比较紧凑。当多个局部点云合并时,远处平板的分层现象会更加严重,直接影响全局点云图的视觉效果。
为了保证得到的点云图的质量,需要去除深度不稳定区域。根据深度相机[39]的噪声模型和我们在实验中得到的经验值,当深度值大于30,000(6m)时,我们将深度图像中某一点的深度值设为0。
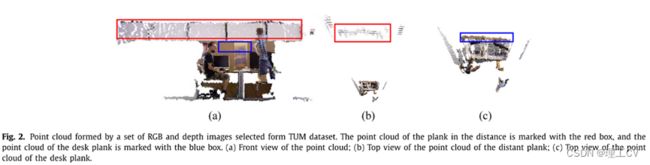
图2所示。点云由TUM数据集中选取的一组RGB和深度图像组成。远处木板的点云用红框标示,写字台木板的点云用蓝框标示。(a)点云的正面图;(b)远处木板上的点云俯视图;(c)桌面板点云俯视图。
8、Depth mask
BlitzNet获得的对象的原始掩码存在两个问题:一是原始掩码不能完全覆盖对象;二是原始掩码覆盖的区域还包含了环境和其他对象的一些信息。因此,由原始掩码直接构建的语义点云图具有以下两个特征:
1. 运动物体的信息会泄露到环境中,形成大量的噪声块;
2. 如果掩码超出静态对象的区域,则部分语义信息将被映射到其他环境点。
如图3所示,转椅的原始掩码覆盖了坐姿者的部分身体,而普通椅子的原始掩码只覆盖了椅子本身的部分。我们将两把椅子的原始面具提供的语义信息映射到当前的点云上,可以发现一些环境点也被染成了红色。

图3,椅子的原始掩码和语义映射后的点云三视图。椅子原始掩码覆盖区域的点被染成红色。一些环境点被语义信息污染,也被染成红色。
我们利用原始掩码Mo所覆盖区域的深度信息对掩码进行改进,得到深度掩码Md,如下所示:
首先,利用对象的原始掩码对图像中的对象进行标记,得到对象的标签,如{Obj1,…,Obj(k)}。
然后,对原始掩码Mobj(i)o中的深度值进行计数,去除0值和异常值,得到深度值集dobj(i)o。找到深度图像中与Obj(i)深度范围相同的像素,如下所示:
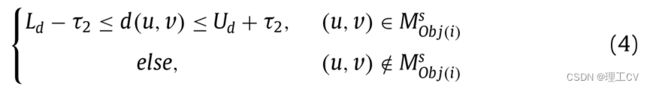
其中Ud和Ld分别为dobj(i)的最大值和最小值。d(u,v)表示(u,v)的深度值,Mobj(i)s表示与Obj(i)深度范围相同的区域。为了提高系统的鲁棒性,将Obj(i)的深度取值范围扩大2*τ2,文中τ2=500 (0.1m)。
由公式4得到的Mobj(i)s可由多个深度范围相同的图像块Mi组成,即:

最后,构造语义约束来保存属于深度掩码Mobj(i)d的图像块,如下所示:

其中PMiS为Mi中具有Obj(i)语义信息的像素数,PMi为Mi中的像素数,τ3为预先设定的阈值,本文τ3=0.25。深度掩码采集算法如算法1所示。

修正掩模Mobj(i)r为原掩模Mobj(i)o与深度掩模Mobj(i)d的并集,即:

如果确定Obj(i)为移动对象,则在消除Obj(i)的信息时,需要去除的是Mobj(i)r所覆盖的区域。如果Obj(i)为静态对象,则在构建语义点云图时,需要映射Mobj(i)d所覆盖区域的语义信息。
人体掩码的修改过程如图4所示。输入为两个人的原始掩码和对应的深度图像显示在橙色框中。坐着的人的标签是P(1),行走的人的标签是P(2)。得到的区域MP(1)S和MP(2)S如蓝框所示,其中MP(1)S由多个图像块组成。通过公式6剔除冗余块,得到深度掩码MP(1)d。最后,将深度掩模与原始掩模进行融合,得到修正掩模。
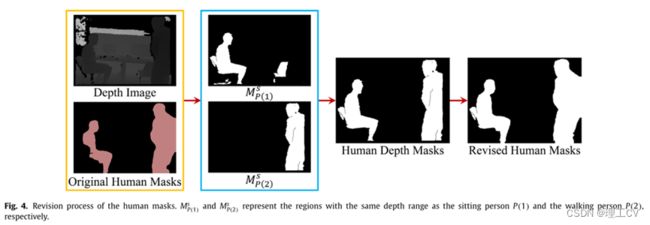
图4所示。人体掩码的修改过程。MsP(1)和MsP(2)分别表示与坐姿者P(1)和行走者P(2)深度范围相同的区域。
9、Judgment of interaction between moving people and movable object
当人的修正掩码与可移动物体的修正掩码相交时,认为两者相互作用,即:
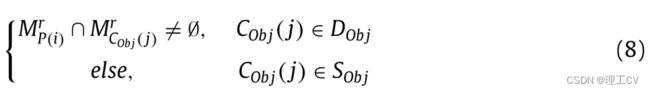
i= 1,……,n,n为图像中的人数,j=1,…,m,m为图像中预定义的可移动对象的个数,DObj为运动对象的集合,SObj为静态对象的集合。人与活动物体交互判断算法如算法2所示。

图5是判断人是否与椅子互动的示意图。修改后的两个人和两把椅子的掩码展示在红色的盒子里。转椅标签为C(1),普通椅标签为C(2),两人标签与图4一致。经过判断,P(1)与C(1)相互作用,即C(1)是一个运动的物体。
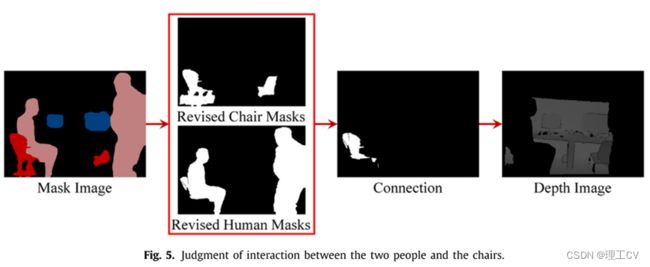
图5判断两个人和椅子之间的互动。
我们将深度图像中两人和转椅修改后的掩码所覆盖区域的深度值设为0,将普通椅子的语义信息映射到当前点云。如图6所示,运动物体被有效去除,普通椅子的语义信息不污染其他环境点。

图6所示。去除移动对象后的局部语义点云。普通椅子C(2)的深度掩模MdC(2)覆盖区域内的点被染成红色。
10、Removal of the residual information of moving objects
移除修正掩模覆盖的区域后,移动对象的部分边界信息可能会偶尔泄露到环境中。这些残差边界形成的噪声块形状长而窄。我们采用的去除边界信息的方法流程如图7所示。输入为去除运动物体修正掩模覆盖区域后的RGB图像和相应的深度图像,输出为去噪块的深度图像。(输入是RGB图像和去除运动对象的修改掩模覆盖的区域后的相应深度图像,输出是没有噪声块的深度图像)
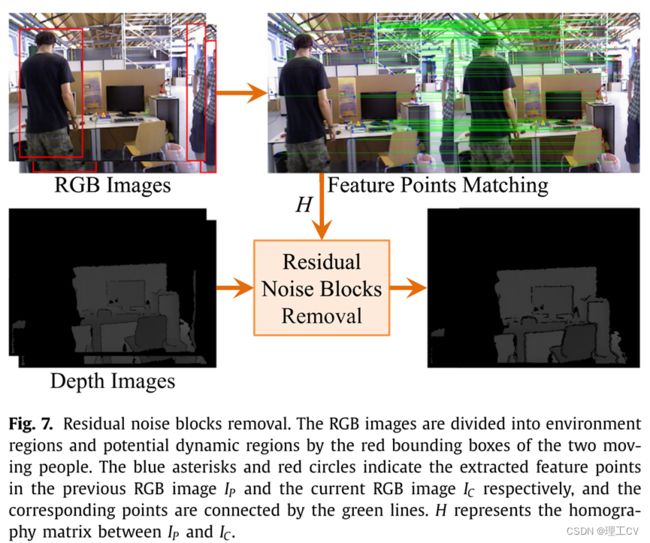
图7所示。去除残留噪声块。RGB图像通过两个移动人物的红色边界框划分为环境区域和潜在动态区域。蓝色星号和红色圆圈分别表示提取的前RGB图像IP和当前RGB图像IC中的特征点,对应的点用绿线连接。H表示IP与IC之间的单应矩阵。
首先,我们将前一帧IP的环境区域提取的特征点与当前帧IC的环境区域进行匹配。利用RANSAC和LM算法可以估计IP和IC之间的单应矩阵H。
设Pp=[uP,vP,1]T为IP上某点的坐标,则IC上该点对应的坐标pC=[uC,vC,1]T可由下式得到:
![]()
相邻帧的残差边界深度值往往相差很大。噪声块可通过以下公式去除:

其中dP和dC分别为IP和IC对应的深度图像。τ4为预先设定的阈值,在本文中τ4= 5000 (1m)。
最后,我们通过形态学运算去除深度图像中小于1000像素的孤立图像块,确保运动物体的信息被完全去除。运动目标残留信息去除算法如算法3所示。图8为去除噪声块前后得到的两个局域点云,噪声块用红色框标记。


图8所示,点云的比较。第一行:去除噪声块前的局部点云,噪声块用红色框标记。第二行:去除噪声块后的局部点云。
当人每次移动可移动物体时,它们的位置就会与移动前不同。如果不能处理好这种情况,这些可移动对象的及时冗余信息将多次出现在全局点云图中。我们所采取的方法是只保留这些物品的最新信息,在此期间它们与人没有任何互动。
图9为两张椅子状态变化的四个阶段,绿色框中为需要保留的两张椅子的信息。在初始阶段,椅子是静态对象,信息保存在全局地图中。在第二阶段,两个人进入相机的视野,并与椅子互动。椅子是动态物体,不参与地图的构建。在这个阶段,地图中的椅子信息是第一个红色虚线框中的椅子。在第三阶段,两人离开摄像机的视野,椅子变得静止。由于两个椅子的位置发生了变化,所以在全局映射中删除了第一阶段的椅子信息,保留了当前的椅子信息。在最后阶段,两人再次与椅子进行交互,就像在第二阶段一样,保存在全局地图中的椅子信息是绿色实框中的椅子。

图9所示,四个阶段的两个椅子的状态变化。在构建全局点云图时,需要删除红色虚线框中的椅子信息,保留绿色实框中的椅子信息。
11、Location of the static matching points
在上一帧IP和当前帧IC中得到两组静态匹配点Pp= {Pp1,Pp2,…, Ppn}和Pc={Pc1, Pc2,…, Pcn},通过求解以下最小二乘问题,可以估计出IP和IC之间的摄像机位姿:

首先,从IP和IC的环境区域中提取匹配点;利用RANSAC算法计算IP与IC之间的基本矩阵F。
然后,在IP和IC的潜在动态区域提取匹配点集PDP=[uDP,vDP,1],PDC=[uDC,vDC,1]。
然后, 我们通过以下公式计算从潜在的动态匹配点到对应的对极线的距离

式中,lx和ly的取值可由

潜在动态区域中第i个匹配点的状态可以用

式中,D为动态匹配点集合,S为静态匹配点集合。τ5为预先设定的阈值,本文取τ5=0.5。静态匹配点定位算法如算法4所示。

Experimental results
在本节中,我们将比较Blitz-SLAM与ORB-SLAM2[2]、Dyna-SLAM[14]和DS-SLAM[18]在TUM RGB-D数据集[40]上的性能。Dyna-SLAM和DS-SLAM都建立在ORB-SLAM2之上,是动态环境中基于视觉的语义SLAM的两种最佳解决方案。TUM数据集提供了几个精确的摄像机轨迹和参数的动态场景。在行走序列中,两个人来回走动,做手势,移动椅子等。在坐着的序列中,两个人只是坐在椅子上聊天,偶尔做个手势。在桌子序列中,一个人进入场景,坐在椅子上,在录制过程中移动桌子上的物体。在这些序列中,行走序列代表了高度动态的环境,而坐姿和桌子序列则描述了低动态的环境。我们选择了四组行走序列、三组低动态序列和一组静态序列作为实验材料。静态序列的场景是一个办公室,没有移动的物体。纯静态序列中评估的目的是验证所提出的前端是否对ORB-SLAM2有负面影响。
该摄像机有四种运动模式:半球面,即摄像机沿半球面轨迹运动;rpy,表示摄像机绕主轴旋转;静态,表示摄像机是手动固定的;还有xyz,这意味着摄像机沿着xyz轴移动。桌子上的序列是由一个行走的人用手持相机记录的。为了便于表达,我们用fr3/w/half、fr3/w/rpy、fr3/w/static、fr3/w/xyz、fr3/s/half、fr3/s/xyz、fr2/desk/p和fr2/xyz来表示八组图像序列,其中fr、s、w、p分别表示freiburg、sitting、walking、person。我们使用的计算机是Ubuntu 16.04系统,8G RAM, Core i5-6500处理器。
12、Evaluation of camera localization
在实验中,采用绝对轨迹误差(ATE)和相对位姿误差(RPE)对[40]进行了定量评价。让P1,…,Pn∈SE(3)表示估计的相机姿态序列,Q1,…,Qn∈SE(3)表示基础真理。ATE度量估计轨迹的全局一致性,时间步长i处的ATE Fi可计算为:

其中S为刚体变换,使估计轨迹与真实轨迹一致。RPE衡量的是在固定时间a(der ta)内估计轨迹的局部精度,时间步长i的RPE Ei定义为:

首先,我们对这四个系统的ATE和RPE进行了定量分析。四种SLAM系统的ATE和RPE的均方根误差(RMSE)和标准差(S.D.)的值见表1 -表3。RMSE度量的是观测值与真实值之间的偏差,它反映了系统的鲁棒性。标准差衡量一个群体作为一个整体的偏差程度,它反映了系统的稳定性。表中改进值计算如下:

其中,k为改进值,α为ORB-SLAM2得到的值,β为Blitz-SLAM的值。
表1和表2分别给出了ATE和平移 RPE的结果。Blitz-SLAM在fr3/w/half, fr3/w/xyz, fr3/s/half和fr2/xyz中取得了最好的结果。在fr3/w/rpy中,Blitz-SLAM的结果仅次于Dyna-SLAM。事实上,这四个系统在低动态和静态序列中的结果非常接近。
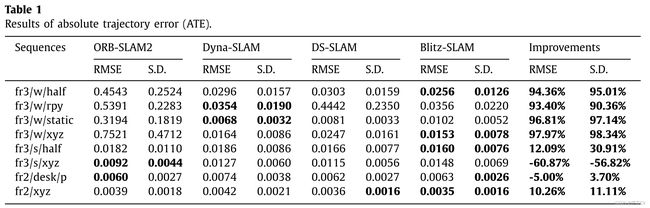
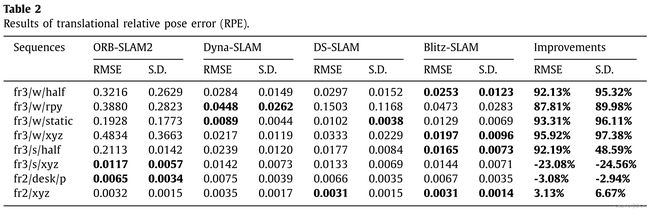
表3显示了旋转RPE的结果。在高动态序列中,总的来说,Dyna-SLAM表现最好。Blitz-SLAM在fr3/w/xyz中的RMSE指标上取得了最佳结果,在fr3/w/half中的s.d指标上取得了最佳值。需要注意的是,在fr3/w/rpy中,Blitz-SLAM的结果仅次于Dyna-SLAM。在低动态序列中,ORB-SLAM2的性能优于这三种动态SLAM系统。在fr3/s/half中,Blitz-SLAM的结果仅次于ORB-SLAM2。
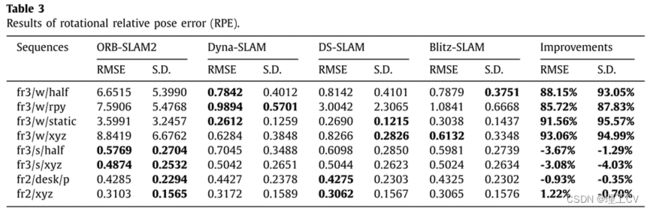
根据表1-表3的结果,我们可以得知,在高动态环境中,消除运动物体后,相机姿态估计将有很大的提高。在四组步行序列中,Dyna-SLAM、DS-SLAM和Blitz-SLAM都取得了较好的姿态估计结果。对于Blitz-SLAM,行走序列中ATE、平移RPE和旋转RPE的平均RMSE改善值分别为95.64%、92.29%和89.62%。行走序列中ATE、平移RPE和旋转RPE的平均S.D改善值分别为95.21%、94.70%和92.86%。这表明所提出的动态对象删除前端可以有效地提高ORB-SLAM2在高动态环境中的性能。同时,我们发现在低动态环境下,我们的方法对ORB-SLAM2的改进没有明显或负面的影响。如前文所述,RANSAC方法可以在低动态环境下有效去除异常值,使得ORB-SLAM2工作良好,因此相机定位的改进空间非常有限。在纯静态序列中,四种SLAM系统的性能相当。
图10显示了四个SLAM系统在四个高度动态序列中的估计轨迹。黑线表示地面真值,蓝线表示估计轨迹,红线表示地面真值与估计轨迹的差值。从第一行我们可以直观地看出,ORB-SLAM2不能有效地处理高度动态的环境。与ORB-SLAM2相比,其他三种SLAM系统估计的摄像机轨迹误差明显减小。

图10所示。估计轨迹的比较。
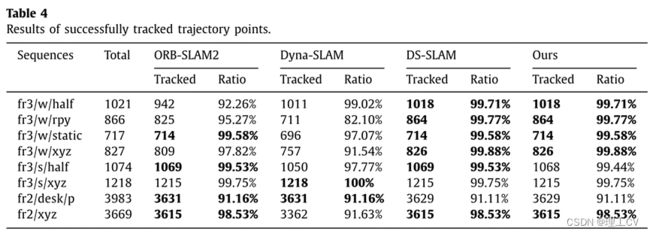
从图10可以看出,这四个SLAM系统都丢失了部分轨迹点。为了定量比较四种系统跟踪的轨迹点,我们给出了它们成功跟踪轨迹点的结果,如表4所示。DS-SLAM和我们的系统在高动态序列中跟踪的轨迹点是最完整的,相比ORB-SLAM2和Dyna-SLAM。ORB-SLAM2、DS-SLAM和Blitz-SLAM在纯静态序列中跟踪的轨迹点数量相同。虽然Dyna-SLAM在fr3/s/xyz和fr2/desk/p上取得了最好的跟踪效果,但在其他6个序列上,Dyna-SLAM跟踪的轨迹点比其他3个SLAM系统少,尤其是在行走序列上。在实践中,特别是长期导航中,更好地覆盖轨迹点比精度的稍微提高更重要。在高动态序列中,Blitz-SLAM成功跟踪轨迹点的平均比例为99.74%。在低动态序列中,Blitz-SLAM成功跟踪轨迹点的平均比例为96.77%。
13、Evaluation of the point cloud map
图11定性显示了TUM行走序列中运动去除的结果。第一行显示了从四组行走序列中选择的RGB图像。第二行和第三行分别显示BlitzNet获得的原始掩码和我们的方法生成的修正掩码。可以看到,原始掩码的边界是平滑的,而修改后的掩码的边界更尖锐。原始掩码无法覆盖移动物体的某些部位,如第一列中行人的腿,第三列中坐着的人的脚和背部,第四列中左边人的手臂。与原始掩码相比,改进后的掩码能更完整地覆盖移动对象的区域。第四行图像是去除移动对象修正掩模覆盖区域后得到的局部点云,其中去除了移动对象形成的污迹。

图11所示,运动去除的结果。第一行:TUM行走序列的RGB图像。第二排:BlitzNet获得的原始掩码。第三行:我们的方法得到的修正掩码。第四行:去除移动物体后的局部点云。改进后的掩模比原始掩模更能完全覆盖运动物体的区域。
如图12所示,我们给出了ORB-SLAM2、Dyna-SLAM、DS-SLAM和Blitz-SLAM在高动态序列fr3/w/xyz上获得的全局点云图的三种视图。两个人的大部分信息都保留在ORB-SLAM2构建的点云图中,看起来很凌乱。你甚至不能指出点云图中存在什么对象,桌子的木板严重扭曲。

图12所示,高动态序列fr3/w/xyz中四个系统构建的点云图的比较。我们的Blitz-SLAM可以给出最清晰的点云图。
Dyna-SLAM和DS-SLAM虽然去除了两个人的干扰,但由于语义分割不完善,导致两个人的边界信息泄露到点云图中。与ORB-SLAM2相比,Dyna-SLAM和DS-SLAM的点云图中的噪声块相对稀疏,可以清楚地看到环境中有什么对象。然而,在无人系统导航中,这种带有大量噪声块的点云图无法直接应用。无人系统必须首先确定这些噪声块所占用的空间是否可以通过,这是非常困难的。
由于去除了环境中移动的人泄露的边界信息,所以Blitz-SLAM得到的点云图中几乎没有人的残留信息。在Dyna-SLAM和DS-SLAM得到的点云图中可以发现两把椅子多次出现。这是因为这两个椅子的位置经常被两个人改变,每个不同位置的椅子的信息都保留在点云图中。在环境中有固定位置的两台计算机显示器上不会出现这种现象。在我们的点云图中,我们只保留两个人与两个椅子交互之前椅子的最新信息。所以可以看到这两把椅子在我们的点云图中只出现了一次。
4个SLAM系统在低动态序列fr3/s/xyz中获得的点云图的三视图如图13所示。在第一列图像中,我们可以很容易地识别出点云图中的物体,桌板没有变形。这是因为ORB-SLAM2可以在较低的动态环境中准确定位相机,并将点映射到正确的位置。但是,两个人的信息完全保留在点云图中。

图13所示,四种系统在低动态序列fr3/s/xyz中构造的点云图的比较。我们的Blitz-SLAM也可以给出最清晰的点云图。
从第二和第三列的图片可以看出,Dyna-SLAM和DS-SLAM已经删除了两人的大部分信息。但我们可以指出两个人的轮廓是由噪声块组成的。从第四列的图像可以看出,去掉了两个人形成的噪声块。但是可以注意到,左边的人的腿的部分信息仍然存在于地图中。认为造成这种现象的原因有二:一是在语义分割阶段,原始掩码覆盖的人体区域太小;第二,这个人的腿离桌子很近,左腿在桌子下面,这导致了后续的几何方法的失败。总体而言,与其他三种SLAM系统相比,Blitz-SLAM在低动态序列中获得的全局点云图最好。
在获得无噪声块的全局点云图后,将静态对象的语义信息映射到全局点云图上,生成语义图。以图12中Blitz-SLAM得到的点云图为例,我们将两把椅子和两个显示器的语义信息映射到点云图上,其中椅子被染成红色,显示器被染成蓝色,如图14所示。由于我们只将对象的深度掩码区域对应的语义信息映射到点云图上,可以明显看出对象的语义信息没有泄漏到环境中,也没有污染其他点。

图14所示,fr3/w/xyz中Blitz-SLAM构建的语义点云图。椅子的尖端被染成红色,显示器的尖端被染成蓝色。
14、Evaluation of processing time
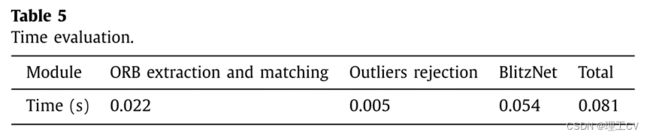
在实际应用中,实时性能是评价SLAM系统的一个重要指标。由于构建全局点云地图需要大量的计算资源,因此我们使用离线地图构建方法。我们测试了相机定位子模块处理一帧所需的时间;结果如表5所示。可以看出,在摄像机定位的三个子模块中,移动对象的分割和检测耗时最长。总体而言,我们的摄像机定位模块满足了实时性的要求。
15、Evaluation in the real-world environment
为了在现实世界中证明Blitz-SLAM的有效性,我们使用Xtion Pro-camera在实验室环境中进行了大量的实验。照相机已经过精确校准。捕获的RGB图像和深度图像尺寸均为640 × 480。在我们的实验中,相机是用手移动的,在移动的过程中,相机会抖动和旋转。在拍摄过程中,有两个人进入了相机的视场,干扰了相机的定位和点云图的构建。
动态特征点剔除的结果如图15所示。在第一行中,环境区域和潜在动态区域通过两个人的边界框快速划分。第二行是动态和静态特征点的分类结果。移动人群的特征点大多被判断为动态点,并用红点标记。

图15所示,动态特征点的位置。第一行:移动人群检测结果。第二行:特征点分类,绿点表示静态特征点,红点表示动态特征点。
图16分别为去除了两人信息前后构建的点云图。在第一排中,墙上的图片被移动的人形成的噪音块挡住了,由于相机定位错误,墙面也严重变形。第二排完全排除了人的干扰,静态物体清晰可见,房间的几何结构也得到了很好的保留。

图16所示,真实环境点云图的定性比较。第一行:ORB-SLAM2获取的点云图。第二行:Blitz-SLAM得到的点云图。两组点云图的对比表明,我们的Blitz-SLAM有效地消除了移动人员带来的负面影响。
Conclusion
在本文中,我们提出了一个工作在动态环境中的语义SLAM系统,称为Blitz-SLAM。Blitz- SLAM的主要思想是利用语义信息来帮助SLAM系统消除移动物体引起的干扰。将原始掩模和运动对象的深度信息相结合得到深度掩模。将深度掩模与原始掩模相结合得到的修正掩模能有效覆盖运动物体的区域。同时,我们提出了一种确定移动物体是否与人接触过的方法,消除了可移动物体在全局地图中出现在不同位置的现象。利用移动对象的边界框,将图像划分为环境区域和潜在动态区域。利用环境区域中的匹配点构造极域约束,去除潜在动态区域中的异常值。实验结果表明,在动态环境下,Blitz-SLAM能够获得准确的摄像机姿态和干净的全局点云图。
但仍有一些问题需要进一步讨论:首先,图像中匹配点的数量和分布将直接影响相机位姿估计的结果。匹配点的优化选择是进一步提高摄像机定位精度的关键。其次,目前语义SLAM系统中的运动对象主要是预先定义的,这意味着当一个未知的运动对象进入相机的视场时,相机的位姿估计会受到干扰,地图会被该物体形成的污迹污染。在这种情况下,可以通过多源传感器信息融合,如IMU(惯性测量单元)与相机的结合,估计出相机的姿态,然后处理地图中未知运动物体形成的涂抹。第三,我们的系统目前的设计是处理室内动态场景,并没有扩展到室外场景。下一步的工作是扩展系统的应用场景,这对于自动驾驶等实际的户外应用将有意义。最后,考虑到无人系统在实际应用中可能与移动物体发生交互,对象级SLAM将是我们未来的研究重点之一。跟踪运动目标并准确估计其姿态有利于提高复杂环境下SLAM系统的鲁棒性。