初探强化学习(5)DDPG算法。包含逐行分析Pytorch代码和算法分析
这个博客适合老鸟来看,讲得很清楚。但是不详细。
有没有循环神经网络的感觉?这个博客都是这种图,很有意思

本文代码参考这个博客点击博客两字即可跳转。。
主要从这个博客搬来的https://zhuanlan.zhihu.com/p/111257402
还有这个博客讲的很清楚https://blog.csdn.net/weixin_43316082/article/details/89467208?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-1.queryctrv2&spm=1001.2101.3001.4242.2&utm_relevant_index=4
前言–如何快速搞懂一个算法
0.1 搞懂数据流向
只有弄明白数据流向,才能知道开发这个算法人的思想。
0.2 结合代码看如何实现
很多人实现代码的方式是不一样的,但是最终的数据流应该是一样的。
1. 我认为最清晰的图和算法流程分析

a t = μ ( s t ) a_{t} = \mu(s_{t}) at=μ(st)
DDPG算法流程如下:
初始化Actor\Critic的 online 神经网络参数: θ Q \theta^{Q} θQ和 θ μ \theta^{\mu} θμ; 将online网 络 的 参 数 拷 贝 给 对 应 的target网 络 参 数 : θ Q ′ ← θ Q \theta{Q{\prime}} \leftarrow \theta^{Q} θQ′←θQ, θ μ ′ ← θ μ \theta{\mu{\prime}} \leftarrow \theta^{\mu} θμ′←θμ ;
初始化replay memory buffer R;
for each episode:
初始化UO随机过程;
for t = 1, T:
下面的步骤与DDPG实现框架图中步骤编号对应:
1. actor 根据behavior策略选择一个 a t a_{t} at , 下达给gym执行该 a t a_{t} at
![]()
behavior策略是一个根据当前online策略 μ \mu μ和随机UO噪声生成的随机过程, 从这个随机过程采样 获得 a t a_{t} at的值。
2. gym执行 a t a_{t} at,返回reward r t r_{t} rt 和新的状态 s t + 1 s_{t+1} st+1
3. actor将这个状态转换过程(transition): ( s t , a t , r t , s t + 1 ) (s_{t}, a_{t}, r_{t},s_{t+1}) (st,at,rt,st+1) 存入replay memory buffer R中,作为训练online网络的数据集。
4. 从replay memory buffer R中,随机采样 N个 transition 数据,作为online策略网络、 online Q网络的一个mini-batch训练数据。我们用 ( s i , a i , r i , s i + 1 ) (s_{i}, a_{i}, r_{i},s_{i+1}) (si,ai,ri,si+1)表示mini-batch中的单个transition数据。
5. 计算online Q网络的 gradient:
Q网络的loss定义:使用类似于监督式学习的方法,定义loss为MSE: mean squared error:

其中, y i y_{i} yi
可以看做"标签":
![]()
基于标准的back-propagation方法,就可以求得L针对 θ Q \theta^{Q} θQ的gradient: ▽ θ Q L \triangledown_{\theta^{Q}} L ▽θQL 。
有两点值得注意:
- y i y_{i} yi的计算,使用的是 target 策略网络 μ ′ \mu^{\prime} μ′和 target Q 网络 Q ′ Q^{\prime} Q′,
这样做是为了Q网络参数的学习过程更加稳定,易于收敛。 - 这个标签本身依赖于我们正在学习的target网络,这是区别于监督式学习的地方。
6. update online Q: 采用Adam optimizer更新 θ Q \theta^{Q} θQ;
7. 计算策略网络的policy gradient:
policy gradient的定义:表示performance objective的函数 J J J针对 θ μ \theta^{\mu} θμ的gradient。 根据2015 D.Silver 的DPG 论文中的数学推导,在采用off-policy的训练方法时,policy gradient算法如下:
![]()
也即,policy gradient是在s根据 ρ β \rho^{\beta} ρβ分布时, ▽ a Q ⋅ ▽ θ μ μ \triangledown_{a}Q\cdot \triangledown_{\theta^{\mu}} \mu ▽aQ⋅▽θμμ 的期望值。 我们用Monte-carlo方法来估算这个期望值:
在replay memory buffer中存储的(transition) ( s i , a i , r i , s i + 1 ) (s_{i}, a_{i}, r_{i},s_{i+1}) (si,ai,ri,si+1) ,是基于agent的behavior策略 β \beta β 产生的,它们的分布函数(pdf)为 ρ β \rho^{\beta} ρβ,所以当我们从replay memory buffer中随机采样获得mini-batch数据时,根据Monte-carlo方法,使用mini-batch数据代入上述policy gradient公式,可以作为对上述期望值的一个无偏差估计 (un-biased estimate), 所以policy gradient 可以改写为:

8. update online策略网络:采用Adam optimizer更新 θ μ \theta^{\mu} θμ ;
9. soft update target网络 μ ′ \mu^{\prime} μ′ 和 Q ′ Q^{\prime} Q′,使用running average 的方法,将online网络的参数,soft update给target网络的参数:

2. 我自己总结的DDPG算法流程图和算法分析
2.1 DDPG算法的数据流向图
我自己整理的DDPG算法的数据走向流程图

其中,紫色直线表示训练策略Actor网络每个阶段数据的流向,紫色虚线表示策略Actor网络整体数据的流向。
绿色直线表示训练Q值Critic网络时每个阶段数据的流向,绿色曲线表示训练Q值网络时数据的整体流向。
红色子项表示经验池中数据的流向。
2.2 DDPG算法的优化方法图

从上面可以看出,共有四个网络,actor, critic, Actor_target, cirtic_target。
只要记着一点:目标网络只是用在求target的过程中。如果不是求target用的,就不用目标网络。
2.2 算法分析
DDPG是一种基于Actor-Critic算法的连续型强化学习算法。
因此,我们首先得从AC算法开始分析。
Critic更新(AC) (更新价值网络参数 θ Q \theta^{Q} θQ)
价值网络拟合的目标一般跟DQN网络一样是最大动作价值函数 Q ∗ Q^* Q∗, 期望显然没法求,于是通过蒙特卡洛方法,使用观测值 Q ( s , a ; θ Q ) Q(s,a;\theta^{Q}) Q(s,a;θQ)来近似,再通过TD算法来改进 θ Q \theta^{Q} θQ:

于是 TD error为:
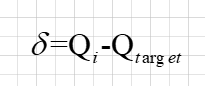
然后通过TD error 梯度下降来更新网络参数 θ Q \theta^{Q} θQ :
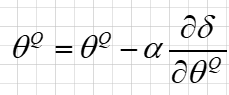
Actor更新(AC) (更新策略网络参数 θ u \theta^u θu)
Critic 输出的价值代表了Actor预测动作的好坏,因此策略网络的目标是最大化价值Value ,自然就想到了用梯度上升法来最大化 Q ( s , a ; θ Q ) Q(s,a;\theta^Q) Q(s,a;θQ) ,于是,我们可以对 Q ( s , a ; θ u ) Q(s,a;\theta^u) Q(s,a;θu)求 θ u \theta^u θu 的梯度,让我们将策略网络记作 π ( s ; θ u ) \pi(s;\theta^u) π(s;θu):
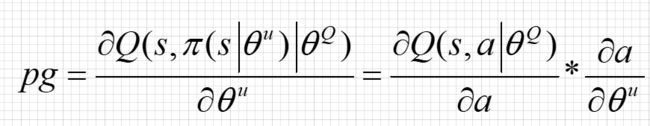
然后用梯度上升更新 θ u \theta^u θu :

Actor更新(DDPG) (更新策略网络参数 θ u \theta^u θu)
和AC不同,Actor(DDPG)输出的是一个确定的动作,Actor(AC)输出的则是这组动作的概率值,毕竟用的是softmax函数。对比AC算法和DDPG算法的Actor部分不难发现,Actor(AC)的输出尺寸是动作空间的维度,而Actor(DDPG)输出尺寸则是1.
Actor的功能是,输出一个动作A,这个动作A输入到Crititc后,能够获得最大的Q值。
所以Actor的更新方式和AC不同,不是用带权重梯度更新,而是用梯度上升。记住这个梯度上升。
Critic更新(DDPG) (更新策略网络参数 θ u \theta^u θu)
Critic网络的作用是预估Q,虽然它还叫Critic,但和AC中的Critic不一样,这里预估的是Q不是V;
注意Critic的输入有两个:动作和状态,需要一起输入到Critic中;
Critic网络的loss其还是和AC一样,用的是TD-error。这里就不详细说明了。
优化高估或低估问题
观察上面的推导过程,我们容易发现,这玩意跟DQN类似,因为bootstraping的通病,一开始低估了就会不断低估,一开始高估了就会不断高估,将会使得估计误差一边倒,导致学习的效果不好。为了处理这个问题,有很多种解决方案,大概就是跟DQN 差不多,DDPG就是这么做的。
引入target network
其实就是加入一个延迟更新策略,分别用两个网络来分别估计 t + 1 t+1 t+1时刻和 t t t时刻的值,即:


仔细观察上面的四个公式和上面与之类似的公式,我们可以发现:在原始的AC算法中,当前时刻和下一时刻的各种数据都是通过同一个函数计算的,也就是同一组参数。
但是在DDPG算法中,针对Actor和Critic是分别有两个网络的,而且这两个网络是相互隔离的。
这样一来就隔断了用自己的估计来估计自己,避免了不断被强化的倾向。但是,实际更新target network参数的过程采用的是这样一种方式:
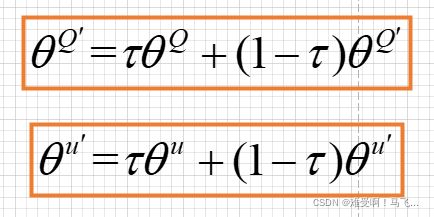
因为target net的参数还是依赖于原来的网络参数,这种传递无法完全避免。
3. 分析pytorch代码
为什么要介绍代码?其实到目前为止,如果大家真的在看我的博客,应该能知道DDPG的所有思想了,但是还有一个关键点的地方就是,DDPG到底该如何保存训练经验的?
往下看…

3.1 Actor代码部分
为了看得清楚点,这块代码我直接截图
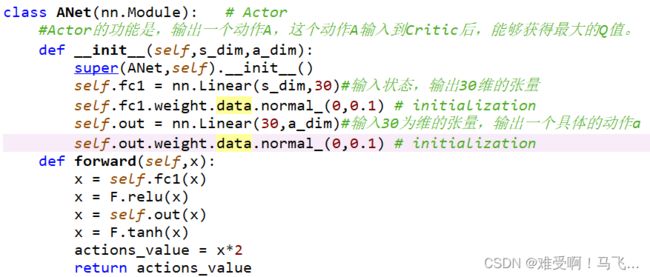
我在代码中做了注释了,
看看算法使用两个nn.Linear()层构成,第一层的输入就是状态s,输出30维的张量,然而第二层还是一个nn.Linear()层组成,输入是上面第一层输出的30维张量,输出是a_dim。哎?看到这边大家是不是矛盾了?为什么说好的输出一个具体的动作,怎么又搞个动作维度呢?到底怎么回事!希望源码程序员给个交代…
好,我现在就给你个胶带…

哦,不好意思,上错图了。其实我真的没有威胁你,

下面先看这个代码的参数部分:
我们使用的是gym里面最简单的部分了
然后,让我们在代码里print一下s_dim和a_dim

看到没有,a_dim = 1,s_dim = 3,注意了,这里的s_dim
3.2 Critic代码部分
直接上代码截图
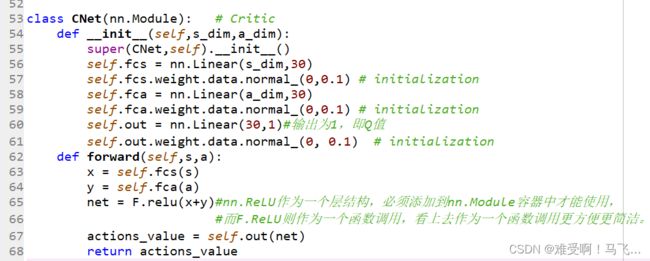
前面怎么说的来着?Critic(DDPG)输出的是Q值,因为Actor(DDPG)输出的是一个具体的动作。
Critic(AC)输出的是V值,因为Actor(AC)输出的是一个状态S下所有的动作概率。
前面还说了,Critic(DDPG)输入的是状态s和动作a。所以可以看出来Cnet代码里有fcs和fca
这两个层用的都是nn.Linear()输入分别是状态和动作,输出都是30维的张量。
然后输出out用的还是nn.Linear()。注意下面的forward部分,直接是relu(x+y)。其实这里不一定是x+y,也可以是连接,如果是连接的话,就得设置self.out = nn.Linear(60,1)#输出为1,即Q值.
30改成60.
两个主要的网络结构介绍完了。下面介绍DDPG网络
这个模块比较长,对,比你还长,应该超过25厘米了。所以我只能贴代码了
3.3 DDPG模块
class DDPG(object):
def __init__(self, a_dim, s_dim, a_bound,):
self.a_dim, self.s_dim, self.a_bound = a_dim, s_dim, a_bound,
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
self.pointer = 0
#self.sess = tf.Session()
self.Actor_eval = ANet(s_dim,a_dim)
self.Actor_target = ANet(s_dim,a_dim)
self.Critic_eval = CNet(s_dim,a_dim)
self.Critic_target = CNet(s_dim,a_dim)
self.ctrain = torch.optim.Adam(self.Critic_eval.parameters(),lr=LR_C)
self.atrain = torch.optim.Adam(self.Actor_eval.parameters(),lr=LR_A)
self.loss_td = nn.MSELoss()
def choose_action(self, s):
s = torch.unsqueeze(torch.FloatTensor(s), 0)
return self.Actor_eval(s)[0].detach() # ae(s)
def learn(self):
for x in self.Actor_target.state_dict().keys():
eval('self.Actor_target.' + x + '.data.mul_((1-TAU))')
eval('self.Actor_target.' + x + '.data.add_(TAU*self.Actor_eval.' + x + '.data)')
for x in self.Critic_target.state_dict().keys():
eval('self.Critic_target.' + x + '.data.mul_((1-TAU))')
eval('self.Critic_target.' + x + '.data.add_(TAU*self.Critic_eval.' + x + '.data)')
# soft target replacement
#self.sess.run(self.soft_replace) # 用ae、ce更新at,ct
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
bt = self.memory[indices, :]
bs = torch.FloatTensor(bt[:, :self.s_dim])
ba = torch.FloatTensor(bt[:, self.s_dim: self.s_dim + self.a_dim])
br = torch.FloatTensor(bt[:, -self.s_dim - 1: -self.s_dim])
bs_ = torch.FloatTensor(bt[:, -self.s_dim:])
a = self.Actor_eval(bs)
q = self.Critic_eval(bs,a) # loss=-q=-ce(s,ae(s))更新ae ae(s)=a ae(s_)=a_
# 如果 a是一个正确的行为的话,那么它的Q应该更贴近0
loss_a = -torch.mean(q)
#print(q)
#print(loss_a)
self.atrain.zero_grad()
loss_a.backward()
self.atrain.step()
a_ = self.Actor_target(bs_) # 这个网络不及时更新参数, 用于预测 Critic 的 Q_target 中的 action
q_ = self.Critic_target(bs_,a_) # 这个网络不及时更新参数, 用于给出 Actor 更新参数时的 Gradient ascent 强度
q_target = br+GAMMA*q_ # q_target = 负的
#print(q_target)
q_v = self.Critic_eval(bs,ba)
#print(q_v)
td_error = self.loss_td(q_target,q_v)
# td_error=R + GAMMA * ct(bs_,at(bs_))-ce(s,ba) 更新ce ,但这个ae(s)是记忆中的ba,让ce得出的Q靠近Q_target,让评价更准确
#print(td_error)
self.ctrain.zero_grad()
td_error.backward()
self.ctrain.step()
def store_transition(self, s, a, r, s_):
transition = np.hstack((s, a, [r], s_))
index = self.pointer % MEMORY_CAPACITY # replace the old memory with new memory
self.memory[index, :] = transition
self.pointer += 1
首先看一下初始化部分

self.memory这一行用于创建经验回放机制的经验池,大小是2000。
然后下面一些的就是实例化DDPG的四个网络。
对应一下符号
eval部分表示的是算法中的online部分,这块的网络参数是实时更新的
self.Actor_eval = ANet(s_dim,a_dim)
self.Critic_eval = CNet(s_dim,a_dim)
target部分表示的是算法中的target部分,这块的网络参数是软更新的
self.Actor_target = ANet(s_dim,a_dim)
self.Critic_target = CNet(s_dim,a_dim)
优化两个神经网络的分别是ctrain和atrain,但是最终只有一个损失函数self.loss_td = nn.MSELoss()
一个模型不能有两个损失函数,这样就没法收敛了、。
3.4 选择动作

torch.unsqueeze()的作用是扩展维度
torch.tensor.detach()用法介绍:
(1)返回一个新的从当前图中分离的Variable。
(2)返回的 Variable 不会梯度更新。
(3)被detach 的Variable volatile=True, detach出来的volatile也为True。
(4)返回的Variable和被detach的Variable指向同一个tensor
3.5 Learning框架

indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
这个就不解释了,从记忆池中按批次提取训练数据
bt = self.memory[indices, :]
bs = torch.FloatTensor(bt[:, :self.s_dim])
ba = torch.FloatTensor(bt[:, self.s_dim: self.s_dim + self.a_dim])
br = torch.FloatTensor(bt[:, -self.s_dim - 1: -self.s_dim])
bs_ = torch.FloatTensor(bt[:, -self.s_dim:])
这一连串的也不用说了,明显是对indices做切片的,肯定是把前面保存的(s,a,r,s_)挨个提取出来。
a = self.Actor_eval(bs)
q = self.Critic_eval(bs,a) # loss=-q=-ce(s,ae(s))更新ae ae(s)=a ae(s_)=a_
这两个不说了。分别用actor和critic求动作和q值。
loss_a = -torch.mean(q)
self.atrain.zero_grad()#清零梯度
loss_a.backward()#反向传播计算
self.atrain.step()
这部分的代码是实时训练训练actor网络,
从这块代码可以看出,online网络是实时训练的。
调用backward()函数之前都要将梯度清零,因为如果梯度不清零,pytorch中会将上次计算的梯度和本次计算的梯度累加。这样逻辑的好处是,当我们的硬件限制不能使用更大的bachsize时,使用多次计算较小的bachsize的梯度平均值来代替,更方便,坏处当然是每次都要清零梯度。
一般形似这样
optimizer.zero_grad()
output = net(input)
loss = loss_f(output, target)
loss.backward()
.step()******标记这个
这是大多数optimizer所支持的简化版本。一旦梯度被如backward()之类的函数计算好后,我们就可以调用step()这个函数。
a_ = self.Actor_target(bs_) # 这个网络不及时更新参数, 用于预测 Critic 的 Q_target 中的 action
q_ = self.Critic_target(bs_,a_) # 这个网络不及时更新参数, 用于给出 Actor 更新参数时的 Gradient ascent 强度
q_target = br+GAMMA*q_ # q_target = 负的
q_v = self.Critic_eval(bs,ba)
td_error = self.loss_td(q_target,q_v)
# td_error=R + GAMMA * ct(bs_,at(bs_))-ce(s,ba) 更新ce ,
#但这个ae(s)是记忆中的ba,让ce得出的Q靠近Q_target,让评价更准确
self.ctrain.zero_grad()
td_error.backward()
self.ctrain.step()
这一部分代码是更新target网络代码,同时也适用于估计下一时刻动作a_和q_值的代码。
同时还包含了TD算法的代码,使用TD_error更新Critic网络。
注意看这边的Actor_target,Critic_target,Critic_eval,的输入是什么?是从及一单元中提取出来的。
再看看记忆回访单元

看看它都存储了哪些东西?
首先看一下np.hstack这个函数,可以参考这个链接。他的作用是将上面的四个张量都堆叠到一块。
index = self.pointer % MEMORY_CAPACITY#取模 - 返回除法的余数
取模运算,self.pointer是0,1,2,3,4,5,6,7,8,9,…它与MEMORY_CAPACITY=10000的余数成为替换memary中数据的标签。
大家注意这边,这边是通过一种近似随机的方式替换记忆池。也就是说可能会把不好的也存进来,把好的给删除了。
3.6 再看训练部分
首先,为什么有人说强化学习其实是一种进化算法,类似于经预算法WOA,遗传算法之类的。
因为这两类算法选优的核心机制是Exploration and Exploitation
翻译成中文就是探索和开发
探索,就是在执行探索的时候多用随机动作。
开发,就是在执行动作的时候使用经验池中的经验。
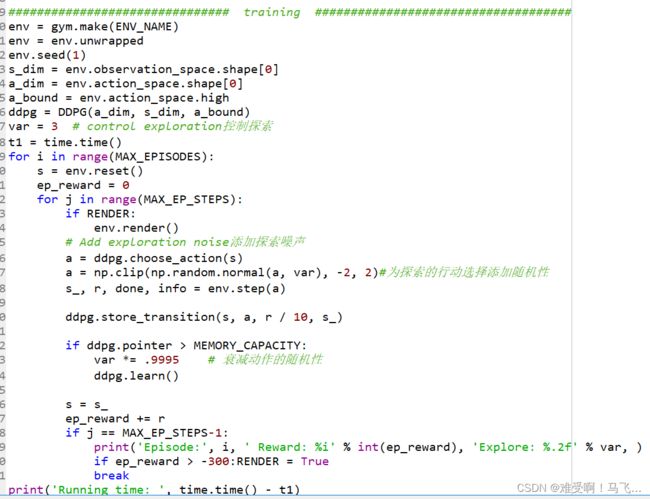
env = gym.make(ENV_NAME)
env = env.unwrapped
env.seed(1)
上面三个代码就是调用环境,第三个代码就是伪随机数
s_dim = env.observation_space.shape[0]
a_dim = env.action_space.shape[0]
a_bound = env.action_space.high
ddpg = DDPG(a_dim, s_dim, a_bound)
var = 3 # control exploration控制探索
t1 = time.time()
这边也是基础的参数设置,然后实例化DDPG网络,DDPG网的三个主要输入都弄好了。
下面就是关于var这个变量,我们先从下面这个大循环开始吧。把大循环讲完了就结束了
首先,我们讲一下np.clip()这个函数
介绍
clip函数:限制一个array的上下界
给定一个范围[min, max],数组中值不在这个范围内的,会被限定为这个范围的边界。如给定范围[0, 1],数组中元素值小于0的,值会变为0,数组中元素值大于1的,要被更改为1.
参数
numpy.clip(a, a_min, a_max, out=None)
a : array
a_min : 要限定范围的最小值
a_max : 要限定范围的最大值
out : 要输出的array,默认值为None,也可以是原array
下面开始讲大循环:
外循环当然是迭代次数了200
s = env.reset()
ep_reward = 0
reset()函数详解
reset()为重新初始化函数。那么这个函数有什么用呢?
在强化学习算法中,智能体需要一次次地尝试,累积经验,然后从经验中学到好的动作。一次尝试我们称之为一条轨迹或一个episode. 每次尝试都要到达终止状态. 一次尝试结束后,智能体需要从头开始,这就需要智能体具有重新初始化的功能。函数reset()就是这个作用。
每次episode结束之后,将奖励值清零,环境状态也清零,重新开始。唯一没清零的是什么?是学习到的网络的参数
开始小循环,
小循环是,每一个episode中智能体的探索步骤次数,在这个步骤内探索到目标点则结束,探索不到则200次强制结束。
render()函数详解
render()函数在这里扮演图像引擎的角色。一个仿真环境必不可少的两部分是物理引擎和图像引擎。物理引擎模拟环境中物体的运动规律;图像引擎用来显示环境中的物体图像。其实,对于强化学习算法,该函数可以没有。但是,为了便于直观显示当前环境中物体的状态,图像引擎还是有必要的。另外,加入图像引擎可以方便我们调试代码。下面具体介绍gym如何利用图像引擎来创建图像。
好了,我们来看看小循环到底做了什么

小循环就是agent在的探索过程:
首先是DDPG算法选择一个动作,大家在脑袋里想一下那个流程图
a = np.clip(np.random.normal(a, var), -2, 2)#为探索的行动选择添加随机性
首先里面的np.random.normal(a, var)是生成高斯分布的概率密度随机数
其中a是此概率分布的均值(对应着整个分布的中心centre)
var是此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
这边的意思是什么呢?本来呢,DDPG算法输出的是一个确定的动作,而且网络更新呢还是异步的,这就导致算法动作一直是一样的,所以呢,这里就通过这种方式来让动作具有一定随机性,即
np.clip这个函数使用来选择动作的,但是呢,为了防止随机的步子太大扯到了蛋,随意它约束了最终的结果,让np.random.normal(a, var)生成的值在(-2,2)之间。
然后,选择这个动作之后,首先需要让这个动作与环境交互,生成新的s_,r等
s_, r, done, info = env.step(a)
done用于判断是否到目标点。
ddpg.store_transition(s, a, r / 10, s_)
然后DDPG把这一步的记忆存储到记忆池中。
导致一步我们明白了该博客第三节的开头的目的

DDPG是每个步骤存储一次的。
然后看下面这一步,
这个if’条件句判断的是什么?
是当这个记忆池满了之后,前面的高斯函数会变瘦,我给大家画个图


看,这个if条件句的意思就是,当记忆单元存满之后,var会越来越小,越小则函数越瘦,这样的意思就是不用探索了。直接训练,ddpg.learn()就是训练模型。
训练好后,将s_赋值给s,进行下一个步骤累加期望奖励ep_reward += r
然后判断时候到了最终的尝试次数

好了,讲完了…
搞懂了DDPG,下面就可以去想着如何跟实际环境结合了。