强化学习(四)--DDPG算法
强化学习(四)--DDPG算法
- 1. DDPG算法
- 2. DDPG算法代码
- 3. DDPG算法的效果展示
上一篇文章介绍了PG算法大类的Reinforce算法,它是一种基于MC更新方式的算法,而它的另一大类是基于Actor-Critic算法,它是一种基于TD更新方式的算法。这一篇文章就来介绍AC算法中应用最多的DDPG算法,它可以直接输出确定性的连续形动作。
1. DDPG算法
详细的算法介绍还是推荐科老师的课程(公开课地址),TD更新方式是指每一个episode的每一个step都进行算法的更新。
DDPG算法有Actor网络和Critic网络,Actor网络输出浮点数,表示确定性的策略,Critic网络则是负责对Actor网络输出的动作进行评价(也就是我们常用的Q值),它的结构图如下图:
- Actor网络: 根据Critic网络的评分来更新策略网络;
- Critic网络: 在每一个step对Actor网络输出的动作评分,根据与环境的reward来调整网络的评估策略,最大化未来总收益。

因此,可以得出优化Actor网络、Critic网络的Loss函数为:
- Actor网络:Loss = -Q;
- Critic网络:Loss = MSE(Q估计,Qtarget).
要注意的是,也可以将DQN中的Target Network和Replay Memory引入到DDPG中,因此需要建立四个神经网络:Critic网络、Target_Critic网络、Actor网络、Target_Actror网络。因此,整个DDPG的框架如下图:
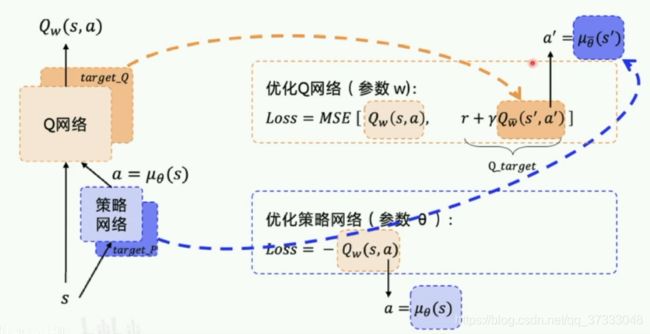
这个框架很清晰的讲解了DDPG算法的核心,可以多看几遍深入了解。
2. DDPG算法代码
如果搞懂了DDPG算法的核心内容,要实现它还是挺容易的,参考前几节的DQN算法,这里直接上完整代码,结合注释很清晰的能看懂:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
##################### hyper parameters ####################
EPISODES = 1000 # 进行多少个Episode
STEPS = 200 # 每个Episode进行多少step
TEST = 5 # 测试时进行多少个Episode
LR_ACTOR = 0.001 # Actor和Critic的学习率
LR_CRITIC = 0.002
GAMMA = 0.9
MEMORY_CAPACITY = 10000 # 经验池的大小
BATCH_SIZE = 32 # 从经验池中取出每个bath的数量
ENV_NAME = 'Pendulum-v0'
env = gym.make(ENV_NAME)
env = env.unwrapped # 用env.unwrapped可以得到原始的类,原始类想step多久就多久,不会200步后失败:
env.seed(1) # 随机种子
s_dim = env.observation_space.shape[0] # 状态的个数
a_dim = env.action_space.shape[0] # 动作的个数
a_bound = env.action_space.high # 动作的上下限
a_low_bound = env.action_space.low
TAU = 0.01 # 用于target网络软更新的参数
########################## DDPG Framework ######################
# # # # Actor策略网络的模型,2层全连接层 # # # #
class ActorNet(nn.Module):
def __init__(self, s_dim, a_dim):
super(ActorNet, self).__init__()
self.fc1 = nn.Linear(s_dim, 30)
self.fc1.weight.data.normal_(0, 0.1) # initialization of FC1
self.out = nn.Linear(30, a_dim)
self.out.weight.data.normal_(0, 0.1) # initilizaiton of OUT
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
x = self.out(x)
x = torch.tanh(x) # tanh函数,把输出限制在[-1,1]的范围内
actions = x * 2 # for the game "Pendulum-v0", action range is [-2, 2]
return actions
# # # # Critic评价网络的模型,3层全连接层 # # # #
class CriticNet(nn.Module):
def __init__(self, s_dim, a_dim):
super(CriticNet, self).__init__()
self.fcs = nn.Linear(s_dim, 30)
self.fcs.weight.data.normal_(0, 0.1)
self.fca = nn.Linear(a_dim, 30)
self.fca.weight.data.normal_(0, 0.1)
self.out = nn.Linear(30, 1)
self.out.weight.data.normal_(0, 0.1)
def forward(self, s, a):
x = self.fcs(s)
y = self.fca(a)
actions_value = self.out(F.relu(x + y)) # critic网络的输入值是s,a两个值
return actions_value
########################## DDPG Class ######################
# # # # 建立DDPG主要的类 # # # #
class DDPG(nn.Module):
def __init__(self,act_dim,obs_dim,a_bound):
super(DDPG,self).__init__()
# 建立状态、动作的参数
self.act_dim = act_dim
self.obs_dim = obs_dim
self.a_bound = a_bound
# 记忆库的参数,当超过记忆库总量时开始训练
self.pointer = 0
# 建立四个网络
self.actor_eval = ActorNet(obs_dim, act_dim)
self.actor_target = ActorNet(obs_dim, act_dim)
self.critic_eval = CriticNet(obs_dim, act_dim)
self.critic_target = CriticNet(obs_dim, act_dim)
# 建立经验回放库
self.memory = np.zeros((MEMORY_CAPACITY, s_dim * 2 + a_dim + 1), dtype=np.float32)
# 建立网络优化器和loss
self.actor_optimizer = torch.optim.Adam(self.actor_eval.parameters(), lr=LR_ACTOR)
self.critic_optimizer = torch.optim.Adam(self.critic_eval.parameters(), lr=LR_CRITIC)
self.loss_func = nn.MSELoss()
# 动作选择的函数
def choose_action(self,obs):
obs = torch.unsqueeze(torch.FloatTensor(obs),0)
action = self.actor_eval(obs)[0].detach()
return action
# 经验回放的函数
def store_transition(self,obs,action,reward,next_obs):
transition = np.hstack((obs, action, [reward], next_obs))
index = self.pointer % MEMORY_CAPACITY # replace the old data with new data
self.memory[index, :] = transition
self.pointer += 1
# 学习的函数
def learn(self):
# target 网络的软更新
for x in self.actor_target.state_dict().keys(): # state_dict,它包含了优化器的状态以及被使用的超参数
eval('self.actor_target.' + x + '.data.mul_((1-TAU))')
eval('self.actor_target.' + x + '.data.add_(TAU*self.actor_eval.' + x + '.data)')
for x in self.critic_target.state_dict().keys():
eval('self.critic_target.' + x + '.data.mul_((1-TAU))')
eval('self.critic_target.' + x + '.data.add_(TAU*self.critic_eval.' + x + '.data)')
# 从经验池中取一个batch的数据
indices = np.random.choice(MEMORY_CAPACITY, size=BATCH_SIZE)
batch_trans = self.memory[indices, :]
# extract data from mini-batch of transitions including s, a, r, s_
batch_s = torch.FloatTensor(batch_trans[:, :self.obs_dim])
batch_a = torch.FloatTensor(batch_trans[:, self.obs_dim:self.obs_dim + self.act_dim])
batch_r = torch.FloatTensor(batch_trans[:, -self.obs_dim - 1: -self.obs_dim])
batch_s_ = torch.FloatTensor(batch_trans[:, -self.obs_dim:])
# Actor策略网络的更新
action = self.actor_eval(batch_s)
Q = self.critic_eval(batch_s,action)
actor_loss = -torch.mean(Q)
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Critic评价网络的更新
act_target = self.actor_target(batch_s_)
q_tmp = self.critic_target(batch_s_,act_target)
Q_target = batch_r + GAMMA * q_tmp
Q_eval = self.critic_eval(batch_s,batch_a)
td_error = self.loss_func(Q_eval,Q_target)
self.critic_optimizer.zero_grad()
td_error.backward()
self.critic_optimizer.step()
########################## Training ######################
# # # # 主函数 # # # #
def main():
var = 3
agent = DDPG(a_dim, s_dim, a_bound) # 定义DDPG的类
for episode in range(EPISODES):
obs = env.reset()
for step in range(STEPS):
action = agent.choose_action(obs) # 选择动作
action = np.clip(np.random.normal(action, var), a_low_bound, a_bound)
next_obs,reward,done,_ = env.step(action)
agent.store_transition(obs,action,reward,next_obs) # 存入经验回放池
if agent.pointer > MEMORY_CAPACITY: # 当超过经验回放池的容量时
var *= 0.9995 # 减少探索的比例
agent.learn()
obs = next_obs
if done:
break
# 每20个episode进行测试
if episode % 20 == 0:
total_reward = 0
for i in range(TEST): # 每次测试取5个episode的平均
obs = env.reset()
for j in range(STEPS):
env.render()
action = agent.choose_action(obs)
action = np.clip(np.random.normal(action, var), a_low_bound, a_bound)
next_obs,reward,done,_ = env.step(action)
obs = next_obs
total_reward += reward
if done:
break
avg_reward = total_reward / TEST # 计算测试的平均reward
print('Episode: ',episode,'Test_reward: ',avg_reward)
if __name__ == '__main__':
main()
3. DDPG算法的效果展示
这里使用的是gym中的 **‘Pendulum-v0’**环境,它是一个基于连续动作的环境,输出的动作是[-2,2]的浮点数,目标是保持杆子零角度(垂直),旋转速度最小,力度最小。

在训练了200个episode后,杆子立起来的时间越来越长,DDPG算法具有效果。
