精度《MoViNets: Mobile Video Networks for Efficient Video Recognition》论文
文章目录
- 1 背景说明
- 2 之前方法存在的问题
- 3 文章要解决的核心问题
- 4 文章的贡献
- 5 结论
- 6 Mobile Video Networks (MoViNets)
-
- 6.1 Searching for MoViNet
- 6.2 The Stream Buffer with Causal Operations
-
- 因果操作
- 流缓冲器的训练和推理
- 6.3 Temporal Ensembles
- 实验
未完待续…

论文名:MoViNets: Mobile Video Networks for Efficient Video Recognition
论文链接:论文链接
代码链接:Pytorch代码链接
1 背景说明
和上一篇TSM论文的背景其实都是差不多的,略过。
点击:上一篇TSM论文精读超链接
2 之前方法存在的问题
- 3DCNN在视频识别方面很精确,但需要大量的计算和内存预算,而且不支持在线推理,这使得它们很难在移动设备上工作。(MoviNet这篇论文很巧妙地把对比方法限制在了3DCNN,这样就可以不对比2.5D的方法。因为其实在TSM论文中就已经提出了在线进行视频识别了。)
3 文章要解决的核心问题
在视频理解上实现高精度和低计算成本,并支持在线推理。
4 文章的贡献
- 他们首先定义了一个MoViNet搜索空间,让神经结构搜索(NAS)有效地权衡时空特征表示。
- 然后,他们为MoViNets引入流缓冲区,它能处理小的连续子视频,只需要恒定的内存,但不牺牲长时间依赖性,并支持在线推理。
- 最后,他们创建流的时间集成器MoViNets,从流缓冲区中恢复稍微丢失的准确性。
5 结论
- MoViNets 提供了一套高效的模型,可以很好地迁移到不同的视频识别数据集。
- 加上流缓冲区,MoViNets 显著降低了训练和推理的内存成本,同时还支持流视频的在线推理。
6 Mobile Video Networks (MoViNets)
6.1 Searching for MoViNet

MoViNet搜索空间。
他们在Kinetics 600数据集上进行网络结构搜索,且模型是以TuNAS框架开始的(由于现在重点不是NAS,所以在这里也不过多展开)。他们在MobileNetV3上建立基本搜索空间。MobileNetV3由几个反向 bottleneck 层块组成,每个层具有不同的 filter 宽度、 bottleneck 宽度、block的深度和 kernel sizes。并且,跟X3D差不多,他们把MobileNetV3中的2D block进行拓展(变成2.5D和3D),用于处理3D视频输入。他们把输入固定为 T × S 2 = 50 × 22 4 2 T \times S^2 = 50 \times 224^2 T×S2=50×2242,其中 T T T代表着时间维度、 S S S代表着空间维度。对于网络中的每个block,他们搜索基本过滤器宽度 c b a s e c^{base} cbase和block里面的层数 L ≤ 10 L \leq 10 L≤10。***他们使用乘数{0.75, 1,1.25}在每个block内的特征映射通道上,四舍五入到8的倍数。***他们设置block的数量 n = 5 ,除了第4个block外(为了确保最后一个block的空间分辨率为 7 2 7^2 72),对每个块的第一层进行空间下采样,下采样为2。block逐渐增加它们的特征通道:{16,24,48,96,96,192}。最后一个的卷积层的基本滤波器宽度是512,在分类层前面,跟随一个2048维度的dense层。
他们在每个层内定义3D卷积核大小, k t i m e × ( k s p a c e ) 2 k^{time} \times (k^{space})^2 ktime×(kspace)2,会从后面这些预定义的卷积核大小中选:{1x3x3, 1x5x5, 1x7x7, 5x1x1,7x1x1, 3x3x3, 5x3x3}。这些选择能够让关注和聚合不同的维度表示,在减少其他维度上的计算量的同时,在最相关的方向上拓展了网络的感受野。一些核大小可能得益于拥有不同数量的输入filters,因此我们在瓶颈宽度范围内搜索 c e x p a n d c^{expand} cexpand,定义为相对于 c b a s e c^{base} cbase的乘子{1.5,2.0,2.5,3.0,3.5,4.0}。每一层都用两个1x1x1的卷积包围3D卷积在 c b a s e c^{base} cbase和 c e x p a n d c^{expand} cexpand之间进行扩展和投影,且在这个过程中不采用下采样。他们使用SE blocks 聚合时空特征,并将其应用于每个瓶颈block中。
缩放搜索空间。
他们的基本搜索空间构成了MoViNet-A2的基础。对于其他MoViNet,他们应用了与EfficientNet中相似的缩放。不一样的是,他们是缩放了搜索空间而不是模型。
6.2 The Stream Buffer with Causal Operations
假设我们有一个有T帧的输入视频x,如果T过大会导致超过设定的内存预算。因此6.2节的内容是提出了一个流缓存,减少了这个内存消耗。

流缓冲区。
为了克服上述限制,他们提出流缓冲机制,将特征激活缓存在子片段边界上,允许他们跨子片段扩展时间接受域,并且不需要重新计算,如图1的右边所示。首先将一段视频分成n段不相交的视频,每个视频长度为 T c l i p T^{clip} Tclip。然后初始化长度为b的缓冲区B(其实理论上来说,要初始化数量和层数一样深的缓冲区),并且这个B在其他维度的是和特征保持一致的(比如长和宽)。然后按照下面的公式来计算特征和更新B:

![]()
这里的 i i i指的是第 i i i段子视频。公式1中,当 i = 0 i=0 i=0时,也就是意味着是第1段子视频,这个时候B是为0的,可以理解成 0 padding(但其实是和0进行concat),且都在同一边进行concat。然后这时候是每一层都这么干,都和0进行concat。然后再根据公式2,取最边边的b帧特征,所以从 i = 1 i=1 i=1开始,B就再也不等于0了,而是来自于上一段子视频的特征。所以这个时候时间复杂度是 O ( b + T c l i p ) O(b+T^{clip}) O(b+Tclip)。
与TSM的关系。
文章中说TSM是特殊的一种流缓存,这个时候b=1。但其实我个人理解起来还是有点差异,因为在这篇论文中,他是专门申请了一块内存,为上一段视频的特征而准备的,本来只是0。在接受了上一段视频的特征之后,才变得有意义。而本身的特征,除了长度为b那块边边的要送给下一段视频以外,其他的特征是不会变动的。而TSM中是将某个通道的特征按照时间维度全部移动了,所以差异还是不小的。
因果操作
这个操作其实指的就是把之前的时间特征concat到现在的时间特征上,来实现在线推理功能,对标TSM中的单向时间shift。此外,他们还提出一个非因果操作,即concat的方向有两个,对标TSM中的双向时间shift,就没了在线推理功能。
因果卷积(CausalConv)
他们用CausalConvs替换所有的时间卷积,有效地使它们沿时间维单向。

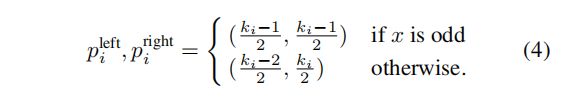

在图2中,可以看到,在标准卷积,在保证不降低维度的前提下,它会在两个方向同时做padding操作。但是这样的话,时间维度上的卷积的感受野会包含前后的时间信息。而在因果卷积中,我们是把时间的感受野限制在了前面(包括当今)的几帧,从而实现一个因果关系。而公式4和5就说明了,其实实现这个只是通过控制padding的方向就可以实现了。在层数变深之后,时间感受野就会一致扩大,直到感受野为(0,t]。(图2中,因果卷积那里维度增加了1维,按照文章后面所讲,这里应该是一个时间维度的累积和)
当使用因果卷积的流缓冲区时,我们可以用缓冲区本身替换因果填充,将前一个子视频的最后几帧向前移动,并将它们复制到下一个子视频的填充中。如果我们的时间核大小为k(并且我们不使用任何跨步采样),那么我们的填充和缓冲区宽度将变成b = k−1。
累积全局平均池化(CGAP)

他们使用CGAP来计算时间维度的全局平均池化,其计算过程如公式3所示。并且他们保留一个单帧流缓冲区,存储 T ′ T' T′帧的累积和。
带有位置编码的CausalSE
他们表示CausalSE是作为CGAP在SE中的应用。将第 t 帧处,将的空间特征图与CGAP(x, t)计算的SE相乘。这个可以和SE类比来理解,SE是先通过池化,消掉空间维度,剩下特征通道维度,然后再与原特征点乘,增强某些通道的作用。而这里的CausalSE,是消掉时间维度,剩下空间、特征通道维度,然后再点乘,增强某些空间/特征通道的作用。也就是说,CausalSE的作用是先考虑了(0,t]之间重要的空间和特征通道,然后再在各个时间上增强这些空间和特征通道。但是直接应用这个CausalSE的话,效果不是很好,文中说的原因是视频早期存在高的方差(不知道是不是说的浅层特征)。为了解决这个问题,他们应用了一种基于正弦的固定位置编码(POSENC)方案。我们直接使用帧索引作为位置,并将编码向量与CGAP输出相加。
流缓冲器的训练和推理
训练
为了减少训练期间的内存需求,我们使用了一种循环训练策略,其中我们将给定的一个batch的样本分成n个子视频,应用前向传递,为每个子视频输出预测,使用流缓冲区缓存特征。然而,关于缓冲区,他们不反向传播梯度,因此之前的子视频的内存可以被释放。然而,他们会计算损失并在子剪辑之间积累计算的梯度,类似于批量梯度积累。当 T = n T c l i p T=nT^{clip} T=nTclip时,在应用梯度之前先来n次前向传播。这种训练策略允许网络学习更长期的依赖关系,从而获得比使用较短视频长度训练的模型更好的准确性。
在线推理
使用因果操作(如CausalConv和CausalSE)的一个主要好处是允许3D视频CNN在线工作。类似于训练,我们使用流缓冲区来缓存视频之间的特征。
6.3 Temporal Ensembles
在Kinetics 600数据集上,流缓冲器可以将MoViNet的内存占用减少到一个数量级,而在精度下降约1%。他们使用简单的集成策略来恢复精度。他们用相同的架构独立训练两个MoViNet,但是将帧率减半,保持持续时间相同(导致输入帧数减半),个人理解是即n不变, T c l i p T^{clip} Tclip减半。他们将一个视频输入到两个网络中,其中一个网络的帧偏移了一帧(即把一个 T c l i p T^{clip} Tclip变成了两个一半,这两个刚好相差一帧)。最后将两个帧率减半的模型集成起来,集成后两个模型的FLOPs加起来和之前单个没降帧率之前是差不多的,但是性能提高了。