58、NeuMan: Neural Human Radiance Field from a Single Video
简介
主页:https://machinelearning.apple.com/research/neural-human-radiance-field
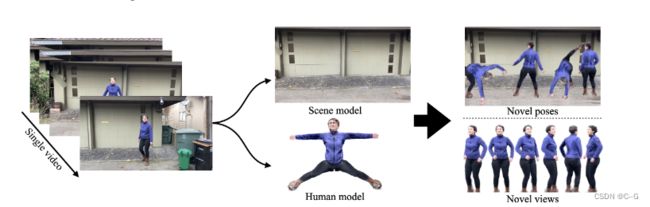
给定一个移动摄像机捕捉的视频,给定一个由移动摄像机捕捉的视频,首先使用传统的现成方法估计人体姿势、人体形状、人体掩码,以及摄像机姿势、稀疏场景模型和深度图,训练两个NeRF模型,一个用于人体,一个用于由 Mask-RCNN估计的分割掩码引导的场景,通过融合来自多视图重建和单眼深度回归的深度估计来正则化场景NeRF模型。

相关工作
- HyperNeRF基于单个视频建模动态场景,但不能由人体姿势驱动
- ST-NeRF用一个依赖于时间的NeRF模型从多个摄像机重建每个个体,但编辑仅限于边界框的转换
- Neural Actor可以生成人类的新姿势,但需要多个视频
- HumanNeRF基于一个带有手动注释掩码的视频构建了一个人体模型,但没有显示对新姿势的泛化
- Vid2Actor生成人类的新姿势与一个单一视频训练的模型,但不能建模背景
贡献点
- 提出了一种框架,用于在不使用任何额外设备或注释的情况下对单个视频中的人和场景进行神经渲染;
- 可以在新颖的姿势下,从新颖的视角,以及场景中,对人体进行高质量的渲染;
- 引入了端到端SMPL优化和纠错网络,以支持对人体几何的错误估计进行训练;
- 允许人和场景NeRF模型的组合,支持远程集合等应用
实现流程
NeRF 回顾

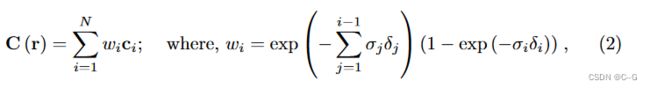
NeuMan实现流程
主要由两个NeRF网络组成
human NeRF,以人体姿势为条件,编码场景中人体的外观和几何形状
scene NeRF编码了背景的样子
先训练 scene NeRF,然后在训练 scene NeRF 的基础上训练 human NeRF

蓝色的样本是场景分支,红色的样本是人类分支。基于估计的SMPL网格和纠错网络,将人体样本扭曲到规范空间。在评估RGB和不透明度后,将两组样本合并为最终积分,得到像素颜色
The Scene NeRF Model
scene NeRF模型与传统运动检测工作中的背景模型相似,不同的是,它是一个NeRF,构建了一个NeRF模型,并只使用被认为来自背景的像素进行训练
对于射线 r,给定人体分割掩码为 M®,其中如果射线对应于人体,M® = 1,而 M® = 0对应于背景,将场景NeRF模型的重建损失表示为
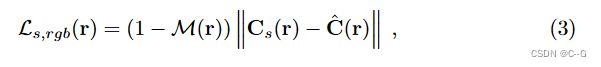
其中 C ^ \hat{C} C^(r)对应于真实的RGB颜色值, C s C_s Cs(r)对应于场景NeRF模型渲染的颜色值。
如 Video-NeRF 中empty loss,简单地最小化Eq. 3会导致“模糊的”物体漂浮在场景中,通过在估计密度上添加正则化器来解决这个问题,并强制相机和场景之间的空间为0,对于每条射线 r, 对终止深度值 z ^ r = D f u s e ( r ) \hat{z}r = D_{fuse}(r) z^r=Dfuse(r)进行采样并最小化
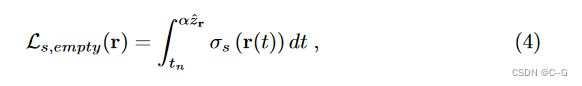
其中 α = 0.8 为松弛裕量,以避免深度估计不准确时的强正则化
结合后损失函数为
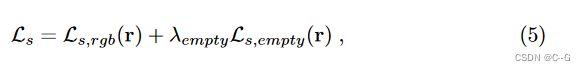
其中 λ e m p t y λ_empty λempty = 0.1 是所有实验中控制空性正则化的超参数。
Preprocessing
给定一个视频序列,使用COLMAP来获取摄像机姿态、稀疏场景模型和多视点立体(MVS)深度图。通常情况下,MVS深度图 D m v s D_{mvs} Dmvs 包含孔,使用密集的单眼深度图 D m o n o D_{mono} Dmono 填充孔。将 D m v s D_{mvs} Dmvs 和 D m o n o D_{mono} Dmono 融合在一起,得到一个具有一致比例尺的融合深度图 D f u s e D_{fuse} Dfuse 。
更详细地说,使用具有两个估计值的像素,找到两个深度映射之间的线性映射。然后用这个映射变换 D m o n o D_{mono} Dmono 的值,以匹配 D m v s D_{mvs} Dmvs 中的深度标度,通过填充孔得到融合深度图 D f u s e D_{fuse} Dfuse 。
在检索人体分割地图时,使用 Mask-RCNN。人体的掩码进一步扩张了 4% ,以确保人体完全掩盖了。根据估计的相机姿态和背景掩模,只在背景上训练场景NeRF模型。
The Human NeRF Model
为了建立一个可以姿势驱动的人体模型,要求模型是姿势独立的,为此,定义了一个基于大-pose (Da-pose) SMPL 网格的规范空间,与传统的 T-pose 相比,Da-pose 避免了腿部从观察空间弯曲到规范空间时的体积碰撞。
为了用该模型在观察空间中渲染一个人的像素,将沿该射线的点转换为规范空间,困难在于如何将 SMPL 网格的转换扩展到整个观测空间,以允许在规范空间中进行光线跟踪,这里使用一种简单的策略将 网格skinning 扩展到体积弯曲领域。
在每一帧 f 中,给定观测空间中的一个三维点 x f = r f ( t ) x_f = r_f (t) xf=rf(t),并根据预处理得到相应的 SMPL 网格估计 θ f θ_f θf ,对其在网格上的最近点进行刚变换,将其转化为正则空间;将这个基于网格的变换表示为 T,使 x f ′ = T θ f ( x f ) x'_f = T_{θ_f} (x_f) xf′=Tθf(xf) 。然而,这种转换完全依赖于 θ f θ_f θf 的准确性,这是不可靠的,即使与最近的艺术状态。为了缓解 SMPL 估计值与潜在人体之间的偏差,在训练时联合优化 θ f θ_f θf 和神经辐射场。
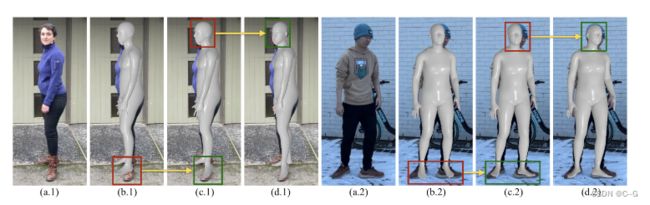
姿态优化示例——提出的对SMPL参数的预处理和端到端优化有效地产生了更好的人体拟合,参见边界框。(一)原始图像。(b)的ROMP的估计。©预处理SMPL。(d)端到端优化的SMPL。
此外,为了考虑到 SMPL 模型无法表达的细节,引入了纠错网络 ε \varepsilon ε,一种修正翘曲场中的错误的MLP。最后,得到观测空间中的点与规范空间 x f → x ~ f ′ x_f→\tilde{x}'_f xf→x~f′ 中的校正点之间的映射为

纠错网只在训练过程中使用,在验证和新姿态的渲染中被丢弃。
由于使用单一的规范空间来解释所有的姿势,纠错网络自然地对每一帧进行过拟合,使规范体更加一般化。
由于翘曲场的性质,在观测空间中的一条直线在翘曲后的正则空间中是弯曲的。因此,通过考虑光线在标准空间中的实际传播方式,通过观察前一个样本的位置,重新计算了视角
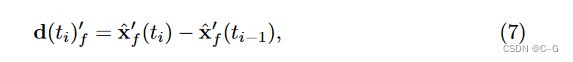
其中, x ^ f ′ ( t i ) \hat{x}'_f (t_i) x^f′(ti) 和 d ( t i ) f ′ d(t_i)'_f d(ti)f′ 为标准空间中第 i 个样本沿弯曲射线的坐标和视角。最后,在标准空间坐标 x ^ f ′ \hat{x}'_f x^f′ 和校正视角 d f ′ d'_f df′ 下,得到人体模型的辐射场值

其中 Φ 是人体NeRF F Φ F_Φ FΦ 的参数。
为了渲染一个像素,发射两条射线,一条用于人体NeRF,另一条用于场景NeRF。沿着射线计算两组样本的颜色和密度。然后根据它们的深度值按升序对颜色和密度进行排序,类似于 ST-NeRF。最后,对这些值进行积分,使用Eq.(2)得到像素。
Training
为了训练人体辐射场,在人体掩码覆盖的区域上采样,并将其最小化
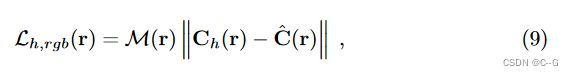
其中 C h ( r ) C_h(r) Ch(r) 是来自人体NeRF模型的渲染颜色。与HumanNeRF类似,也使用LPIPS作为额外的损失项 L l p i p s L_{lpips} Llpips,通过采样32 × 32的补丁。使用 L m a s k L_{mask} Lmask 来强制从人体NeRF累积的alpha映射,使其与检测到的人体掩码相似。
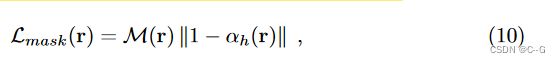
其中 α h α_h αh 为射线的累积密度。
为了避免规范空间中的斑点和半透明的 canonical human,强制规范SMPL网格内部的体积为固体,而强制规范SMPL网格外部的体积为空,由

此外,利用硬表面损失 L h a r d L_hard Lhard来减轻canonical human周围的光环。具体来说,鼓励每个样本的权重为1或0,
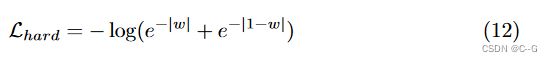
其中 w 为射线终止处的透明度。然而,仅这一惩罚还不足以获得一个清晰的规范形状, 还添加了一个规范边缘损失, L e d g e L_{edge} Ledge 。通过渲染标准体积中的随机直线射线,鼓励累积alpha值为1或0。这是由
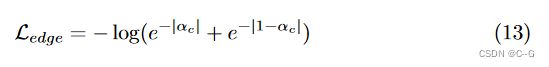
其中 α c α_c αc 为正则空间中随机直射线的累积 α 值。因此,最终损失由
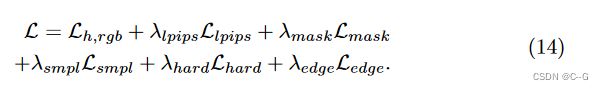
联合优化 θ f θ_f θf, ε \varepsilon ε 和 F Φ F_Φ FΦ,最小化这个损失。我们设置 λ l p i p s λ_{lpips} λlpips = 0.01, λ m a s k λ_{mask} λmask = 0.01, λ s m p l λ_{smpl} λsmpl = 1.0, λ h a r d λ_{hard} λhard = 0.1, λ e d g e λ_{edge} λedge = 0.1。由于检测到的掩模是不准确的,通过训练线性衰减 λ 掩模到 0。
Preprocessing Scene-SMPL Alignment
利用ROMP 来估计视频中人体的SMPL参数。然而,估计的SMPL参数并不准确。因此,使用估计的轮廓和估计的二维关节优化SMPL参数,细化SMPL估计。然后将SMPL估算值与场景坐标对齐。
Scene-SMPL Alignment
为了构建一个具有新颖视角和姿势的人的场景,并训练两个NeRF模型,对两个NeRF模型所在的坐标系进行对齐。事实上,这是一个非常重要的问题,因为人体姿势估计器在自己的相机系统中操作,通常使用的是接近正投影的相机模型。为了解决这一问题,首先解决了透视 n 点(PnP)问题之间估计的三维节点和投影的二维节点与摄像机本征从COLMAP。这解决了任意比例的对齐问题。然后假设人至少在一帧中站在地面上,通过找到SMPL模型的脚网格与地面平面接触的比例尺来解决比例尺模糊的问题。通过RANSAC程序得到了地平面。

SMPL的可视化和场景对齐——显示采样的视频帧(第一行),以及估计的SMPL网格叠加在场景点云(第二行)上。人在场景中的比例是正确的,因为脚是接触地面的。SMPL网格是基于时间着色的。
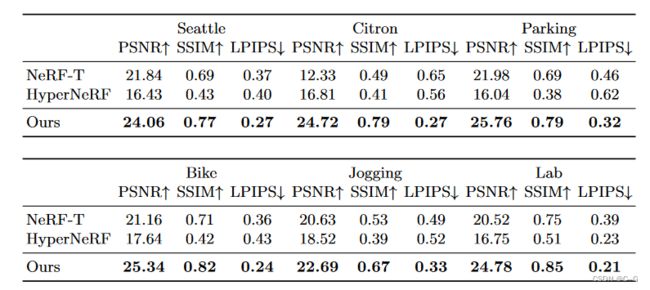
效果