点云损失函数Chamfer Distance 和 Earth Mover‘s Distance
这里假设两个点云集 和
和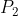 。
。
1、Chamfer Distance
计算 中每个点到中最近点的距离,并将它们相加:
![]()
def array2samples_distance(array1, array2):
"""
arguments:
array1: the array, size: (num_point, num_feature)
array2: the samples, size: (num_point, num_feature)
returns:
distances: each entry is the distance from a sample to array1
"""
num_point1, num_features1 = array1.shape
num_point2, num_features2 = array2.shape
# 这里是计算的重点,array1是直接复制了num_point2次(abab),
# 而array2是分别对每个点复制num_point1次(aabb)
expanded_array1 = array1.repeat(num_point2, 1)
expanded_array2 = torch.reshape(
torch.unsqueeze(array2, 1).repeat(1, num_point1, 1),
(-1, num_features2))
distances = (expanded_array1-expanded_array2)* (expanded_array1-expanded_array2)
# distances = torch.sqrt(distances)
distances = torch.sum(distances,dim=1)
distances = torch.reshape(distances, (num_point2, num_point1))
distances = torch.min(distances,dim=1)[0]#查找P1到P2中每个点的最小距离
distances = torch.mean(distances)
return distances
def chamfer_distance(array1, array2):
batch_size, num_point, num_features = array1.shape
dist = 0
for i in range(batch_size):
av_dist1 = array2samples_distance(array1[i], array2[i])
av_dist2 = array2samples_distance(array2[i], array1[i])
dist = dist + (0.5*av_dist1+0.5*av_dist2)
return dist*100 Chamfer Distance的基本思路就是计算点集到点集中每一个点的距离,然后再查找最小距离,然而这个距离是有问题的,可能存在点集的某个点使用多次,这可能会导致点集的点聚集在一起,点云失去了均匀性。且可能存在多组点集到点集的距离相同,失去了点集的唯一性。
2、EMD
为解决Chamfer Distance 约束点云收敛的问题,故在点云生成过程中,会采用Earth Mover's Distance 约束 点集到点集的距离。
完全解析EMD距离(Earth Mover's Distance)这里解释了EMD的基本原理,EMD的计算保证每一个点只使用了一次,且类似于匈牙利算法,寻找 点集到点集的最近距离,进而进行优化网络的训练。
可见EMD的计算会消耗大量的计算资源,因此在论文{eometric data analysis, beyond convolutions}中采用了EMD的近似计算方法,代码如下:
import torch
from geomloss import SamplesLoss
def batch_EMD_loss(x, y):
bs, num_points_x, points_dim = x.size()
_, num_points_y, _ = y.size()
batch_EMD = 0
L = SamplesLoss(loss = 'gaussian', p=2, blur=.00005)
for i in range(bs):
loss = L(x[i], y[i])
batch_EMD += loss
emd = batch_EMD/bs
return emd这里采用了SampleLoss,可以运用在网络的训练的过程中,加速网络的收敛,但是在metric时不能使用该损失函数,因为计算结果会存在误差。