打通tensorflow版Unet_v1代码
目录
知识积累:
代码调试:
构建Unet网络:
1.Conv2D
ModelCheckpoint
model.fit()
代码
data.py
unet.py
运行情况
最终结果(必还有优化的空间)
知识积累:
卷积、池化->CNN->FCN->Unet_WRStop的博客-CSDN博客_fcn
代码调试:
tensorflow版Unet(U-net-master)代码调试_WRStop的博客-CSDN博客
构建Unet网络:
model = self.get_unet()- encoder:5个子模块,每个模块有两个卷积层,每个模块之后有一个通过maxpool实现的下采样层。
- decoder:4个子模块,每个模块有两个卷积层,每个模块之后跟着一个上卷积
1.Conv2D
定义:

[tensorflow] 卷积和池化中的padding操作带来的维度变化_ASR_THU的博客-CSDN博客
Tensorflow 中 tf.keras.layers.Conv2D 中filter 参数的含义 - 简书
filters:Conv2D继承自Conv类,所以filter参数也赋值到Conv类的filters参数里面。在上面Conv类的build方法里面可以看到,filters参数同input_channel参数连接到kernel_size后面。所以filters参数是kernel_shape四元组的最后一个元素。而kernel_shape元祖格式为(height,width,input_channel, output_channel)所以filter就是卷积操作后结果输出的通道数。相当于图像卷积后输出的图像通道数。
kernerl-size:是卷积核的大小,如果为3的话,卷积核大小为(3*3)
strides:步长
activation:激活函数
padding:
变量x是一个2×3的矩阵,max pooling窗口为2×2,两个维度的步长strides=2
由于步长为2,当向右滑动两步之后,VALID方式发现余下的窗口不到2×2所以直接将第三列舍弃,而SAME方式不会把多出的一列丢弃,而是填充0,same可以保证2x2不影响原始信息。

valid

same
ModelCheckpoint

model_checkpoint = ModelCheckpoint('unet.hdf5', monitor='loss',verbose=1, save_best_only=True)参考:ModelCheckpoint详解_you是mine的博客-CSDN博客_modelcheckpoint函数
ModelCheckpoint该回调函数将在每个epoch后保存模型到filepath
filename:字符串,保存模型的路径
monitor:需要监视的值,通常为:val_acc 或 val_loss 或 acc 或 loss
verbose:信息展示模式,0或1。为1表示输出epoch模型保存信息,默认为0表示不输出该信息,信息形如:
![]()
save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
model.fit()

model.fit(imgs_train, imgs_mask_train, batch_size=4, epochs=10, verbose=1,validation_split=0.2, shuffle=True, callbacks=[model_checkpoint])参考:model.fit() fit函数_a1111h的博客-CSDN博客_model.fit()
batch_ size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
validation_ split: 0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意validation_ split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_ split, 否则可能会出现验证集样本不均匀。
shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
callbacks: list, 其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数。
代码
data.py
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import numpy as np
import os
import glob
import cv2
#from libtiff import TIFF
#之前所有地path应该都是\\,都改成了/
class dataProcess(object):
def __init__(self, out_rows, out_cols, data_path = "data/train/image", label_path = "data/train/label", test_path = "data/test", npy_path = "npy_data", img_type = "tif"):
"""
"""
self.out_rows = out_rows
self.out_cols = out_cols
self.data_path = data_path
self.label_path = label_path
self.img_type = img_type
self.test_path = test_path
self.npy_path = npy_path
# 将data/train/image里面的图片加载进来并数字化存储到npy_data下
def create_train_data(self):
i = 0
print('-'*30)
print('Creating training images...')
print('-'*30)
# 返回所有匹配的文件路径列表,它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。
imgs = glob.glob(self.data_path+"/*."+self.img_type)
# GitHub源代码的基础上改动:由于glob的图片读入并不是顺序的,所以加上sort函数,参考CSDN
imgs.sort(key=lambda x: int(x.split('/')[3][:-4]))
print(len(imgs))
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8) # 创建ndarray对象
imglabels = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
for imgname in imgs:
#print(imgname) # data/train/image/13.tif
midname = imgname[imgname.rindex("/")+1:]
#print(midname) # 13.tif
img = load_img(self.data_path + "/" + midname,grayscale = True)
#print(img)
label = load_img(self.label_path + "/" + midname,grayscale = True)
img = img_to_array(img) # 图片转为数组,img_to_array 转换前后类型都是一样的,唯一区别是转换前元素类型是整型,转换后元素类型是浮点型(和keras等机器学习框架相适应的图像类型)
label = img_to_array(label)
#img = cv2.imread(self.data_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#label = cv2.imread(self.label_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#img = np.array([img])
#label = np.array([label])
imgdatas[i] = img
imglabels[i] = label
if i % 100 == 0:
print('Done: {0}/{1} images'.format(i, len(imgs)))
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_train.npy', imgdatas) # 存储到npy_data文件夹路径下
print(imgdatas)
np.save(self.npy_path + '/imgs_mask_train.npy', imglabels)
print('Saving to .npy files done.')
def create_test_data(self):
i = 0
print('-'*30)
print('Creating test images...')
print('-'*30)
imgs = glob.glob(self.test_path+"/*."+self.img_type)
imgs.sort(key=lambda x: int(x.split('/')[2][:-4]))
print(len(imgs))
imgdatas = np.ndarray((len(imgs),self.out_rows,self.out_cols,1), dtype=np.uint8)
for imgname in imgs:
midname = imgname[imgname.rindex("/")+1:]
img = load_img(self.test_path + "/" + midname,grayscale = True)
img = img_to_array(img)
#img = cv2.imread(self.test_path + "/" + midname,cv2.IMREAD_GRAYSCALE)
#img = np.array([img])
imgdatas[i] = img
i += 1
print('loading done')
np.save(self.npy_path + '/imgs_test.npy', imgdatas)
print('Saving to imgs_test.npy files done.')
def load_train_data(self):
print('-'*30)
print('load train images...')
print('-'*30)
# train
imgs_train = np.load(self.npy_path+"/imgs_train.npy") # imgs_train = np.load(self.npy_path+"\\imgs_train.npy")
# train的label
imgs_mask_train = np.load(self.npy_path+"/imgs_mask_train.npy") # imgs_mask_train = np.load(self.npy_path+"\\imgs_mask_train.npy")
imgs_train = imgs_train.astype('float32') #转换为float32
imgs_mask_train = imgs_mask_train.astype('float32')
# 二值化操作,0、255
imgs_train /= 255
#mean = imgs_train.mean(axis = 0)
#imgs_train -= mean
imgs_mask_train /= 255
imgs_mask_train[imgs_mask_train > 0.5] = 1
imgs_mask_train[imgs_mask_train <= 0.5] = 0
return imgs_train,imgs_mask_train
def load_test_data(self):
print('-'*30)
print('load test images...')
print('-'*30)
imgs_test = np.load(self.npy_path+"/imgs_test.npy")
imgs_test = imgs_test.astype('float32')
imgs_test /= 255
#mean = imgs_test.mean(axis = 0)
#imgs_test -= mean
return imgs_test
if __name__ == "__main__":
#aug = myAugmentation()
#aug.Augmentation()
#aug.splitMerge()
#aug.splitTransform()
mydata = dataProcess(512,512)
mydata.create_train_data()
mydata.create_test_data()
#imgs_train,imgs_mask_train = mydata.load_train_data()
#print imgs_train.shape,imgs_mask_train.shape
unet.py
import os
#os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import numpy as np
import tensorflow
#之前所有的path应该都是\\,我给都改成了/
from keras.models import *
from keras.layers import Input, merge, Conv2D, MaxPooling2D, UpSampling2D, Dropout, Cropping2D
from keras.optimizer_v1 import Adam
from keras.optimizer_v2 import adam as adam_v2 # 更新为v2版的adam_v2
from keras.optimizers import *
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as keras
from keras.layers import merge
from data import *
#import data
class myUnet(object):
def __init__(self, img_rows = 512, img_cols = 512):
self.img_rows = img_rows
self.img_cols = img_cols
def load_data(self):
mydata = dataProcess(self.img_rows, self.img_cols)
imgs_train, imgs_mask_train = mydata.load_train_data()
imgs_test = mydata.load_test_data()
return imgs_train, imgs_mask_train, imgs_test
def get_unet(self):
inputs = Input((self.img_rows, self.img_cols,1))
'''
unet with crop(because padding = valid)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(inputs)
print "conv1 shape:",conv1.shape
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv1)
print "conv1 shape:",conv1.shape
crop1 = Cropping2D(cropping=((90,90),(90,90)))(conv1)
print "crop1 shape:",crop1.shape
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print "pool1 shape:",pool1.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool1)
print "conv2 shape:",conv2.shape
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv2)
print "conv2 shape:",conv2.shape
crop2 = Cropping2D(cropping=((41,41),(41,41)))(conv2)
print "crop2 shape:",crop2.shape
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print "pool2 shape:",pool2.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool2)
print "conv3 shape:",conv3.shape
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv3)
print "conv3 shape:",conv3.shape
crop3 = Cropping2D(cropping=((16,17),(16,17)))(conv3)
print "crop3 shape:",crop3.shape
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print "pool3 shape:",pool3.shape
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
crop4 = Cropping2D(cropping=((4,4),(4,4)))(drop4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = merge([crop4,up6], mode = 'concat', concat_axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = merge([crop3,up7], mode = 'concat', concat_axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = merge([crop2,up8], mode = 'concat', concat_axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = merge([crop1,up9], mode = 'concat', concat_axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'valid', kernel_initializer = 'he_normal')(conv9)
'''
# 构建卷积层。用于从输入的高维数组中提取特征。
# filters:输出空间的维数;kernel_size:卷积核大小;strides=(1, 1)横向和纵向的步长;padding :valid表示不够卷积核大小的块,则丢弃; same表示不够卷积核大小的块就补0,所以输出和输入形状相同;activation:激活函数;kernel_initializer:卷积核的初始化
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
print("conv1 shape:",conv1.shape)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
print("conv1 shape:",conv1.shape)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
print("pool1 shape:",pool1.shape)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
print("conv2 shape:",conv2.shape)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
print("conv2 shape:",conv2.shape)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
print("pool2 shape:",pool2.shape)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
print("conv3 shape:",conv3.shape)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
print("conv3 shape:",conv3.shape)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
print("pool3 shape:",pool3.shape)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = merge.concatenate([drop4,up6], axis=3 ) # 参考CSDN改成了keras.layers.merge新版本的新用法
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = merge.concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = merge.concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = merge.concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)
model = Model(inputs = inputs, outputs = conv10) #也是改为了新版本的keras中的语法
model.compile(optimizer = adam_v2.Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy']) # 更新为v2版的adam_v2.Adam
return model
def train(self):
print("loading data")
imgs_train, imgs_mask_train, imgs_test = self.load_data()
print("loading data done")
# 搭建unet模型
model = self.get_unet()
print("got unet")
# ModelCheckpoint该回调函数将在每个epoch后保存模型到filepath
model_checkpoint = ModelCheckpoint('unet.hdf5', monitor='loss',verbose=1, save_best_only=True)
print('Fitting model...')
model.fit(imgs_train, imgs_mask_train, batch_size=4, epochs=10, verbose=1,validation_split=0.2, shuffle=True, callbacks=[model_checkpoint])
print('predict test data')
imgs_mask_test = model.predict(imgs_test, batch_size=1, verbose=1)
np.save('/Users/fengyuting/Documents/pycharm/CV/Unet/U-net-master/results/imgs_mask_test.npy', imgs_mask_test)
def save_img(self):
print("arrays to image")
imgs = np.load('/Users/fengyuting/Documents/pycharm/CV/Unet/U-net-master/results/imgs_mask_test.npy')
# 二值化
# imgs[imgs > 0.5] = 1
# imgs[imgs <= 0.5] = 0
for i in range(imgs.shape[0]):
img = imgs[i]
img = array_to_img(img)
img.save("/Users/fengyuting/Documents/pycharm/CV/Unet/U-net-master/results/results_jpg/%d.jpg"%(i))
if __name__ == '__main__':
myunet = myUnet()
myunet.train()
myunet.save_img()
运行情况


最终结果(必还有优化的空间)
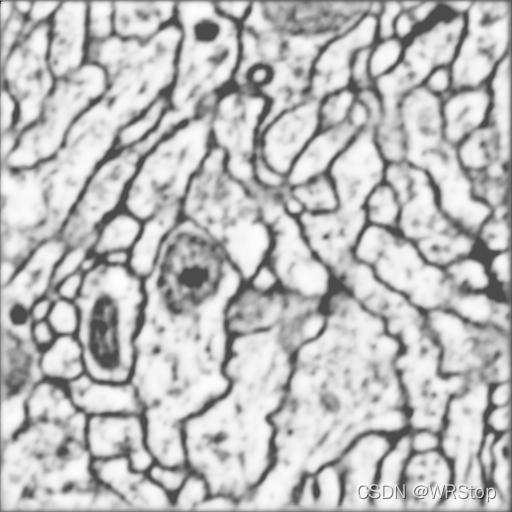
最最开始predict的一次的0.jpg (那时候还没有对test数据sort)