python pandas.pivot_table透视表函数
文章目录
- 一、官方文档
- 二、参数解析
- 三、案例解析
-
- 3.1 新建数据集
- 3.2 两种写法
- 3.3 columns参数
- 3.4 fill_value 缺失值填充
- 3.5 margins 求合计
- 3.6 dropna 删除缺失值
- 3.7 aggfunc 聚合函数与自定义函数
一、官方文档
pandas.pivot_table
二、参数解析
DataFrame.pivot_table(
#column to aggregate, optional(要计数的列)
values=None,
#column, Grouper, array, or list of the previous(要分组的索引)
index=None,
#column, Grouper, array, or list of the previous(要分组的列名)
columns=None,
#function, list of functions, dict, default numpy.mean(透视的函数,默认平均值)
aggfunc='mean',
#scalar, default None(标量,默认无)
fill_value=None,
#bool, default False(合计)
margins=False,
#bool, default True(是否删除缺失值)
dropna=True,
#str, default 'All'('合计'命名)
margins_name='All',
)
三、案例解析
3.1 新建数据集
import pandas as pd
import numpy as np
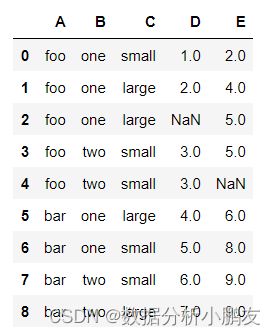
df = pd.DataFrame({
"A": ["foo", "foo", "foo", "foo", "foo","bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two","one", "one", "two", "two"],
"C": ["small", "large", "large", "small","small", "large", "small", "small","large"],
"D": [1, 2, np.nan, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, np.nan, 6, 8, 9, 9]
})
3.2 两种写法
# 一般写法
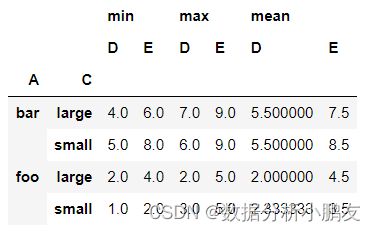
df.pivot_table(
values=['D','E'], # 计算的数值列选择D、E
index=['A','C'], # 维度选择A、C
aggfunc=[min,max,np.mean] # 聚合函数
)
#另一种写法
pd.pivot_table(
df,
values=['D','E'], # 计算的数值列选择D、E
index=['A','C'], # 维度选择A、C
aggfunc=[min,max,np.mean] # 聚合函数
)
3.3 columns参数
pd.pivot_table(
df,
values=['D','E'],
columns=['A'],
aggfunc=[min,max,np.mean]
)

3.4 fill_value 缺失值填充
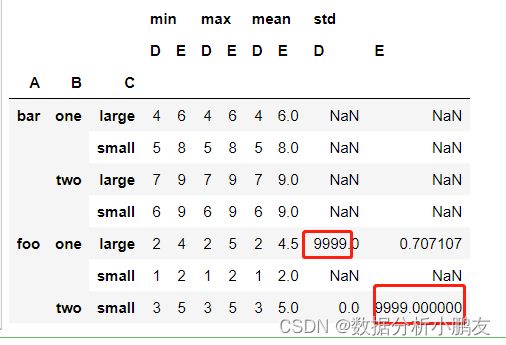
df.pivot_table(
values=['D','E'],
index=['A','B','C'],
aggfunc=[min,max,np.mean,np.std],
fill_value=9999, # 缺失值填充
)
3.5 margins 求合计
df.pivot_table(
values=['D','E'],
index=['A','B'],
columns=['C'],
margins=True,
margins_name="合计" # 合计名称
)

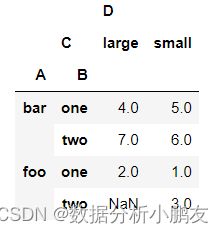
3.6 dropna 删除缺失值
df.pivot_table(
values=['D'],
index=['A','B'],
columns=['C'],
dropna=True, # 删除缺失值
aggfunc=np.min
)
3.7 aggfunc 聚合函数与自定义函数
- 采用字典方法
- 通过 lambda 方法可以传入自定义函数
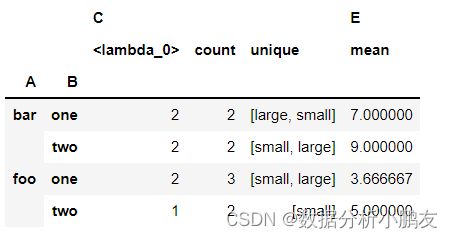
df.pivot_table(
values=['C', 'E'],
index=['A', 'B'],
aggfunc={
'C': ["count","unique",lambda x:len(x.unique())],
'E': np.mean
}
)