pytorch基础
文章目录
- 一. pytorch 基础
-
- 1.1 损失函数与反向传播
- 1.2 优化器
- 1.3 VGG16模型的使用与修改
- 1.4 完整网络模型的训练套路简单汇总
-
- 1.4.1 网络模型的保存与读取
- 1.4.2 完整模型套路
-
- 创建网络模型(model.py要确保与train.py在同一文件夹就行)
- 对分类问题特有的衡量指标-正确率的理解与应用
一. pytorch 基础
1.1 损失函数与反向传播
先是简单的自定义tensor张量去计算loss:
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32) # 自定义的tensor张量, 变成浮点数
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))# input(N,*) 改变input与targets的形状:1个样本,通道为1,宽高为1*3(一行三列)
targets = torch.reshape(targets,(1, 1, 1, 3))
loss = L1Loss() # L1Loss()可以选择计算的方式
result = loss(inputs, targets)
loss_mse = nn.MSELoss( )
result_mse = loss_mse(inputs,targets)
print(result)
print(result_mse)
# 代码的计算过程为 :
# 1-1 = 0, 2-2 = 0,3-5 = -2 , 绝对值相加除以3 = 0.6667
# 若 loss = L1Loss(reduction="sum") 则结果只相加 = 2
x= torch.tensor([0.1,0.2,0.3])
y= torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
我们再将之前简单的神经网络模型直接应用CIFAR10图片数据集的十分类问题中,其中需要注意的是我们应该通过对比outputs与targets之间的关系去选择合适的loss function;比如下面分类图片例子中,根据输出与标签可得应选择CrossEntropyLoss(),并且该交叉熵有两个作用:
- 计算实际输出与目标之间的差距;
- 为更新输出提供一点的依据(方向传播),grad
每一个需要更新的参数都需要求出一个对应的梯度,在优化过程中,可根据梯度进行参数优化,达到降低loss的目的。(梯度下降法)
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
#Sequential可以简化代码
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
test1=test()
loss=nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
print(imgs.shape)
outputs = test1(imgs)
print(outputs) # outputs为经过VGG模型分类的输出
print(targets) # targets为标签
result_loss = loss(outputs,targets)
print(result_loss)
result_loss.backward()
print("ok")
1.2 优化器
我们之前的做的反向传播具有极大的作用对于训练模型参数,有了模型中各节点的参数梯度,该如何选择合适的优化器来进行参数优化,以达到最低的loss。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class test(nn.Module):
def __init__(self):
super(test, self).__init__()
# Sequential可以简化代码
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2, stride=1),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
test1 = test()
loss = nn.CrossEntropyLoss()
# 设置优化器
optim = torch.optim.SGD(test1.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
#print(imgs.shape)
outputs = test1(imgs)
#print(outputs) # outputs为经过VGG模型分类的输出
#print(targets) # targets为标签
result_loss = loss(outputs, targets)
optim.zero_grad()
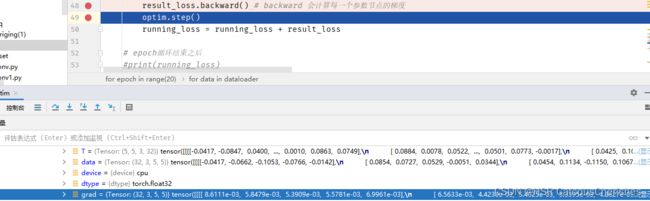
result_loss.backward() # backward 会计算每一个参数节点的梯度
optim.step()
running_loss = running_loss + result_loss
# epoch循环结束之后
print(running_loss)
# Files already downloaded and verified
# tensor(18638.4355, grad_fn=<AddBackward0>)
# tensor(16128.6719, grad_fn=<AddBackward0>)
# 进程已结束,退出代码0
在优化过程中可利用debug操作,观测grad的变化:如下图
1.3 VGG16模型的使用与修改
利用现有的VGG16模型去添加模型结构,适合去做一个前置的网络结构,可以提取一些特殊的特征,这其实也十分重要!
import torchvision
from torch import nn
# train_data = torchvision.datasets.ImageNet("../dataset",split = 'train',download = True,
# transform=torchvision.transforms.ToTensor())
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True) # 模型参数都有训练好的VGG模型
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("../dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 添加
vgg16_true.add_module('add_linear', nn.linear(1000,10))
print(vgg16_true)
# 修改
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)
# 发现有修改
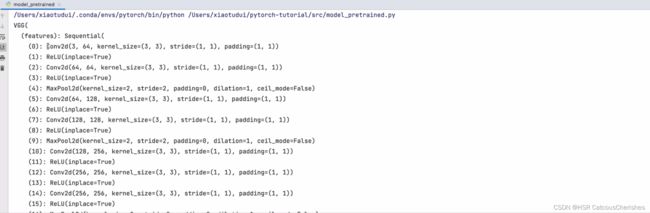
原始的VGG16 模型的网络结构如下图所示:是直接从model里面下载的结构:
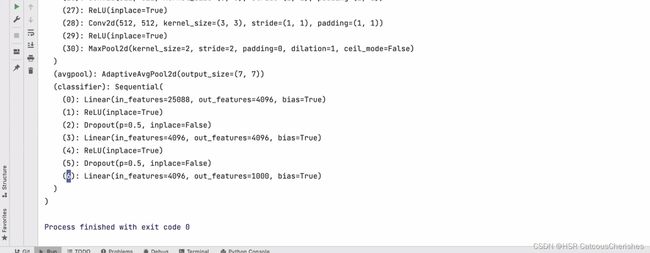
会发现模型的网络结构发生添加或者修改了。
1.4 完整网络模型的训练套路简单汇总
1.4.1 网络模型的保存与读取
保存方式1: 模型结构+参数(占内存大,不推荐)
保存方式2:模型参数
import torch
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
# 保存方式1 “保存路径.pth”什么后缀都行推荐为.pth 保存 模型结构+参数
torch.save(vgg16, "vgg16_method1.pth")
# 保存方式2 , 模型参数(官方推荐)
torch.save(vgg16.state_dict(), "vgg16_method2.pth")
#依然是保存方式1:(自定义的模型需要全部引入,才能读取到)
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3) ## 随意的一个操作
def forward(self, x):
x = self.conv1(x)
return x
test = Test()
torch.save(test,"test_method1.pth")
读取方式与保存方式对应:
import torch
from model_save import *
import torchvision
# 保存与读取方式需要对应(方式一),加载方式1:
model = torch.load("vgg16_method1.pth")
# print(model)
# 方式二对应读取方式(官方比较推荐的读取方式)
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
model = torch.load('test_method1.pth')
print(model)
1.4.2 完整模型套路
搭建神经网络,CIFAR10有10个类别,所以要搭建一个10分类的网络:
创建网络模型(model.py要确保与train.py在同一文件夹就行)
import torch
from torch import nn
class Test(nn.Module):
def __init__(self):
super(Test, self).__init__()
# 为了避免上下两个def都写一整串,将整个网络放到序列当中
self.model = nn.Sequential(
# Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0),按ctrl+p会提示需填写的参数
nn.Conv2d(3, 32, 5, 1, 2), # 卷积
nn.MaxPool2d(2), # 最大池化
nn.Conv2d(32, 32, 5, 1, 2), # 卷积
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64), # 最后两步的展平
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 简单的验证模型是否正确
if __name__ == '__main__':
test = Test()
input = torch.ones((64, 3, 32, 32)) # 创建一个输出的尺寸 64个图片,3个通道,32*32的
output = test(input)
print(output.shape)
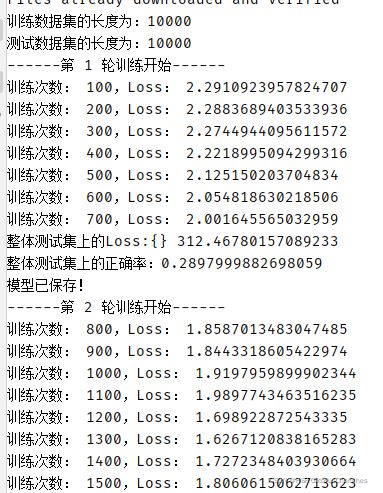
训练模型的完整步骤:
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 训练数据集的下载,root为下载位置
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 测试数据集的下载
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(test_data)
test_data_size = len(test_data)
# 如果训练数据集的长度train_data_size=10,则会输出 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型(model要确保在同一文件夹就行)
test =Test()
# 创建定义好损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 1e-2 # SGD为随机梯度下降优化器,学习速率为learning_rate = 0.01
optimizer = torch.optim.SGD(test.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard的使用
writer = SummaryWriter("logs_train")
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1)) # 为了符合阅读习惯,写成i+1 (i从0取到9)
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = test(imgs)
loss = loss_fn(outputs, targets) # 输出和目标之间的损失值
# 优化器调优 优化模型
optimizer.zero_grad() # 优化前梯度清零
loss.backward() # 调用损失的反向传播,得到每个参数检验的梯度
optimizer.step()# 调用优化器,进行了一次训练,完成一次优化
# 一次训练完成,训练次数+1
total_train_step = total_train_step + 1
#只显示100能够整除的信息
if total_train_step %100 == 0:
# 因为有两个{}需要替换,所以format有两个量去替换大括号中的值
print("训练次数: {},Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss",loss.item(),total_train_step) # 添加tensorboard
# 测试步骤开始
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets =data
outputs = test(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
print("整体测试集上的Loss:{}",format(total_test_loss))
writer.add_scalar("test_loss",total_test_loss,total_test_step) # 添加tensorboard
total_test_step = total_test_step + 1
# 保存训练模型的每一轮
torch.save(test,"test_{}.pth".format(i))
print("模型已保存!")
writer.close()
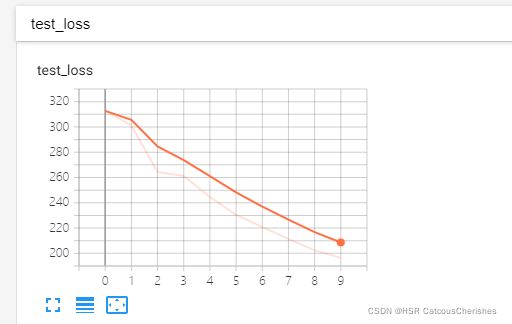
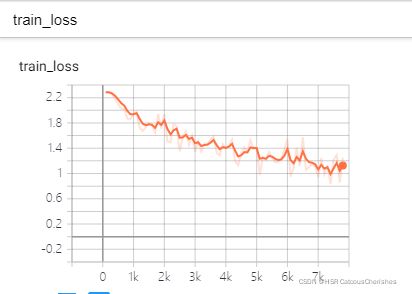
并在tensorboard上面展示模型训练LOSS下降的过程:
在终端中输入:tensorboard --logdir=logs_train
对分类问题特有的衡量指标-正确率的理解与应用
import torch
# 假设的二分类问题
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
test_len=10 # 测试集长度
print(outputs.argmax(1)) # 按横向取出最大的值
preds = outputs.argmax(1) # preds取最大值的位置
targets = torch.tensor([0, 1])
print(preds ==targets)
print((preds ==targets).sum()) # 计算为true的个数
print(((preds ==targets).sum())/test_len)
#tensor([1, 1])
#tensor([False, True])
#tensor(1)
#tensor(0.1000)
将正确率应用到上面的模型中:
# 测试步骤开始
total_test_loss = 0
total_accuary =0
with torch.no_grad():
for data in test_dataloader:
imgs,targets =data
outputs = test(imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuary = (outputs.argmax(1) ==targets).sum()
total_accuary =total_accuary +accuary
print("整体测试集上的Loss:{}",format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuary/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step) # 添加tensorboard
writer.add_scalar("test_accuacy",total_accuary/test_data_size,total_test_step)
total_test_step = total_test_step + 1