es部署及使用
本文链接:http://huserblog.com/articles/2020/10/16/1602852358163.html
- es介绍
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库Apache Lucene™ 基础之上。详细参考:https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html
- es基础知识
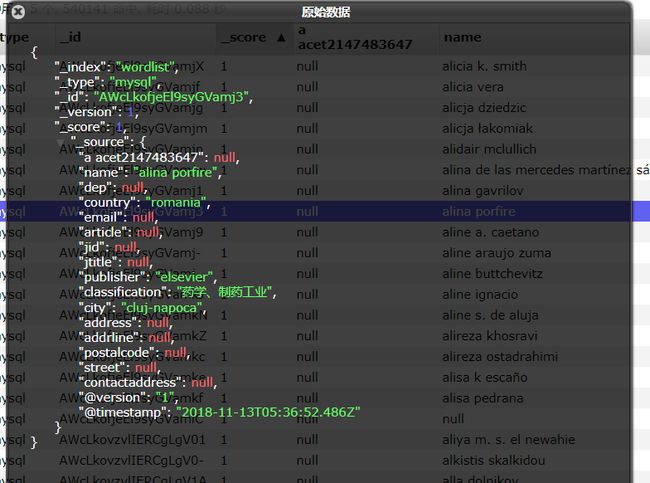
es数据存储的结构(三个主要结构:index、type、document)
index > type > document
index:最高级的结构
type:次一级结构
document:最低级结构(存储数据的结构,数据以json的格式存储)
es数据实例:
- es交互
如果你正在使用 Java,在代码中你可以使用 Elasticsearch 内置的两个客户端:
节点客户端(Node client)
传输客户端(Transport client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道 数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
轻量级的传输客户端可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
传输客户端的使用实例如下:
Map<String, String> map = new HashMap<String, String>();
map.put("cluster.name", "es");
Settings.Builder settings = Settings.builder().put(map);
TransportClient client = TransportClient.builder().settings(settings).build()
.addTransportAddress(
new InetSocketTransportAddress(
InetAddress.getByName("192.168.56.151"), Integer.parseInt("9300")
));
其中map里放的是es集群的名称。
参考:https://www.elastic.co/guide/en/elasticsearch/client/java-api/2.2/transport-client.html
- es数据导入导出
Hadoop与es的数据交换,可以直接使用MapReduce对es集群进行读写操作,不过这种方法比较麻烦,es里有一个elasticsearch-hadoop包,使用这个包会更方便。
例:elasticsearch-hadoop从es导入数据到hdfs,首先主函数的配置如下:
Configuration conf = new Configuration();
conf.setBoolean("mapred.map.tasks.speculative.execution", false);
conf.setBoolean("mapred.reduce.tasks.speculative.execution", false);
//ElasticSearch节点
conf.set(ConfigurationOptions.ES_NODES, "192.168.56.150:9200");
conf.set(ConfigurationOptions.ES_NODES, "192.168.56.151:9200");
conf.set(ConfigurationOptions.ES_NODES, "192.168.56.152:9200");
conf.set(ConfigurationOptions.ES_NODES, "192.168.56.153:9200");
//ElaticSearch Index/Type
conf.set("es.resource", "wordlist/2/");
conf.set("fs.defaultFS", "hdfs://192.168.56.150:9000");
Job job = Job.getInstance(conf, "JOBE2H01");
job.setJarByClass(EshMapImport.class);
job.setInputFormatClass(EsInputFormat.class);
job.setMapperClass(EshMapImport.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LinkedMapWritable.class);
FileOutputFormat.setOutputPath(job, new Path("/out/esinput"));
job.waitForCompletion(true);
首先在conf中配置es的节点信息,然后配置index与type。其余与正常mr相同。Mapperclass无特殊操作。
Bug备注:
在将程序打包提交到集群上执行时出现了错误:Truncated class file。详细日志如下:
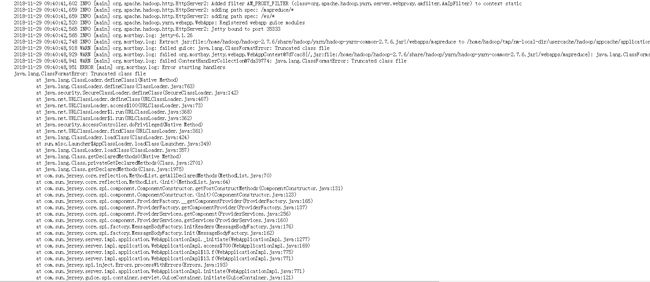
错误描述:该class文件被截断了。
原因:推测为jar包中的文件名过长,导致DataNode在抽取jar包中的文件到指定目录时,其文件名超出了Linux的限制。所以无法复制class文件。
修复方法:更改打包方法。上述打包方式为:runnable jar(将依赖包一起加入jar中)。将其改为普通的jar包,依赖的jar包在程序中指定。指定方法如下:

其中jar的路径为hdfs上的路径。
数据库与es的数据交换
推荐使用Logstash
Logstash简介
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash安装:
下载后解压即可
Logstash导入数据到es:
Logstash导入数据十分简单,只需配置好配置文件,然后执行便可。以mysql为例导入的配置文件如下:

配置也十分简单:input是数据所在的一端,上图是mysql数据库,使用jdbc导数据,配置好jdbc所需的各个参数。Output是数据需要导入的地方。上图是es集群。如上图简单配置即可。其中document_id是用于指定es中document的ID,可以指定为mysql中的字段,若不写,则随机生成。
- es Java api使用
参考:https://www.elastic.co/guide/en/elasticsearch/client/index.html
添加
向es中添加数据的Java使用如下:
String json=" {\r\n" +
"\"word\": \"Department\",\r\n" +
"\"num\": 203453\r\n" +
"}";
IndexResponse response = client.prepareIndex("wordlist", "test")
// .setId("1")
.setSource(json)
.execute()
.actionGet();
其中client是上文中的TransportClient的实例(以下使用的都是该实例)。参数wordlist是index的名称,test是type的名称,json是要插入的数据。
修改
修改es中的数据的方法如下(已知id):
String json=" {\r\n" +
"\"word\": \"Department\",\r\n" +
"\"num\": 20345343\r\n" +
"}";
client.prepareUpdate("wordlist", "test", "AWdxzRh3SyjkjqM3Yd9w")
.setDoc(json).get();
删除
client.prepareDelete("wordlist", "test", "AWdxzRh3SyjkjqM3Yd9w").get();
查询
Es的查询支持很多种方式,其中最简单的查询方法如下:
SearchResponse searchResponse=client.prepareSearch().get();
SearchHit[] searchHits = searchResponse.getHits().getHits();
for (int i = 0; i < searchHits.length; i++) {
System.out.println(searchHits[i].getSourceAsString());
}
Es的查询可以跨一个或多个索引和跨一个或多个类型执行。更多的查询方法请参考以下文档:
https://www.elastic.co/guide/en/elasticsearch/client/java-api/2.2/java-search.html
https://www.elastic.co/guide/cn/elasticsearch/guide/current/search-in-depth.html
https://www.elastic.co/guide/en/elasticsearch/reference/2.2/search.html