TensorFlow模型训练中的心酸(问题)汇总
TensorFlow 模型训练遇到的问题汇总
文章目录
-
- TensorFlow 模型训练遇到的问题汇总
- 一、如何用TensorFlow训练模型
- 二、TensorFlow报错处理
-
- 1.无法from object_detection import XXX
- 2.找不到string_int_label_map_pb2.py文件怎么办?
- 3.没有officaial或者无法import officaial如何做?
- 三、如何优雅地进行模型转换
-
- 一、TF2.x的测试
- 二.tf1.x模型的测试
- 总结
问题汇总并解决时间为2022年10-11月,所使用TensorFlow版本为tf1.13-gpu版本和tf2.6(pip install直接安装版本)
以下是本篇文章分享的内容,下面案例可供参考
一、如何用TensorFlow训练模型
1、环境配置
TF2.x : 与TF1.x安装方法相同,只是tensorflow的版本不相同
TF2.x API文件
TF1.x :
1️⃣在anaconda上创建一个虚拟环境 conda create -n your_name python=3.6
2️⃣激活进入虚拟环境 activate ssd #win10系统下,自己创建的虚拟环境
3️⃣根据硬件安装 conda install tensorflow-gpu==1.13.1 或者 tensorflow1.13.1
4️⃣下载Tesorflow Object Detecttion API 的 r1.13.0 版本 并在虚拟环境下编译安装
(版本不对应可能会导致模型训练转换出错)
TF1.x API(以前版本,copy其他博主)
2.数据集收集和制作
将所需要识别物体的图片收集若干张(仅用作测试训练整个流程大概100张就有明显的效果了),通过数据标注工具对图片进行标注,通常用的打标工具为labelImg,可以通过pip install labelImg下载安装,具体使用方法不详细说明。
博主本人用的是网站在线标注(make-sense),标注完后可以选择输出自己喜欢的格式(但是需要注意不同训练代码对xml文件的读取问题,make-sense标注一般没有目标的详细参数,只有矩形框的参数)
3、Xml做分类
将训练的xml文件分为训练集、验证集和测试集。
import os
import random
import time
import shutil
xmlfilepath=r'./your_dataset'
saveBasePath=r"./Annotations"
trainval_percent=0.8
train_percent=0.8
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("train size",tr)
start = time.time()
test_num=0
val_num=0
train_num=0
for i in list:
name=total_xml[i]
if i in trainval: #train and val set
if i in train:
directory="train"
train_num += 1
xml_path = os.path.join(os.getcwd(), 'Annotations/{}'.format(directory))
if(not os.path.exists(xml_path)):
os.mkdir(xml_path)
filePath=os.path.join(xmlfilepath,name)
newfile=os.path.join(saveBasePath,os.path.join(directory,name))
shutil.copyfile(filePath, newfile)
else:
directory="validation"
xml_path = os.path.join(os.getcwd(), 'Annotations/{}'.format(directory))
if(not os.path.exists(xml_path)):
os.mkdir(xml_path)
val_num += 1
filePath=os.path.join(xmlfilepath,name)
newfile=os.path.join(saveBasePath,os.path.join(directory,name))
shutil.copyfile(filePath, newfile)
else:
directory="test"
xml_path = os.path.join(os.getcwd(), 'Annotations/{}'.format(directory))
if(not os.path.exists(xml_path)):
os.mkdir(xml_path)
test_num += 1
filePath=os.path.join(xmlfilepath,name)
newfile=os.path.join(saveBasePath,os.path.join(directory,name))
shutil.copyfile(filePath, newfile)
end = time.time()
seconds=end-start
print("train total : "+str(train_num))
print("validation total : "+str(val_num))
print("test total : "+str(test_num))
total_num=train_num+val_num+test_num
print("total number : "+str(total_num))
print( "Time taken : {0} seconds".format(seconds))
4、Xml转换csv文件
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
print(root.find('filename').text)
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text), #width
int(root.find('size')[1].text), #height
member[0].text,
int(member[4][0].text),
int(float(member[4][1].text)),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for directory in ['train','test','validation']:
xml_path = os.path.join(os.getcwd(), 'Annotations/{}'.format(directory))
xml_df = xml_to_csv(xml_path)
# xml_df.to_csv('whsyxt.csv', index=None)
xml_df.to_csv('./your_dataset.csv'.format(directory), index=None)
print('Successfully converted xml to csv.')
main()
5、Csv转换Tensorflow训练所用的record文件
# csv2tfrecord.py
# -*- coding: utf-8 -*-
"""
Usage:
# From tensorflow/models/
# Create train data:
python csv2tfrecord.txt --csv_input=train_labels.csv --output_path=train.record
# Create test data:
python csv2tfrecord.py --csv_input=test.csv --output_path=itest.record
"""
import os
import io
import pandas as pd
import tensorflow.compat.v1 as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
os.chdir('./test1')
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label): # 根据自己的标签修改
if row_label == 'object':
return 1
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), './data') # 需改动
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
如此上述所需文件已经配置完成,训练所需config自己配置。
tensorFlow预训练模型:
tf2.预训练模型
tf1.预训练模型
二、TensorFlow报错处理
1.无法from object_detection import XXX
运行训练指令时model_main_tf2.py与object_detection在同一级目录下,无法正常导入。如何避免非在同一级目录下from XXX import 文件。
在anaconda 的当前环境中,lib->site_package->添加pth文件(文件内包含所需越级访问的路径,经过测试,在计算机path添加没有效果)
PTH文件内的输入所需要的绝对路径,可以参考如下:
C:\Users\呆呆兽\Desktop\tensorflow_models\models-master\research
C:\Users\呆呆兽\Desktop\tensorflow_models\models-master\research\slim
C:\Users\呆呆兽\Desktop\tensorflow_models\models-master\research\object_detection
C:\Users\呆呆兽\Desktop\tensorflow_models\models-master\official
2.找不到string_int_label_map_pb2.py文件怎么办?
“protoc.exe” object_detection/protos/*.proto --python_out=.
将object_detection/protoc 内的py文件编译
还有可能出现错误:
cannot import name ‘builder’ from ‘google.protobuf.internal’
解决:https://github.com/protocolbuffers/protobuf/issues/9778
更换个与本机pip库 相匹配的protoc,例如本机版本为3.19.1,不能使用protoc_3.20版本
3.没有officaial或者无法import officaial如何做?
错误做法:把与reasearch同一级的offical复制
正确做法: pip install tf-models-official
安装中途可能遇到的错误: pip install pypiwin32 提示Cannot uninstall ‘pywin32’
site_package中直接删除pywin32文件夹,或则删除pywin32-220-py3.6.egg-info
三、如何优雅地进行模型转换
经过上述两步骤,tensorflow API的环境应该可以运行了
一、TF2.x的测试
TF2.x 训练指令
️模型训练:
python object_detection/model_main_tf2.py --model_dir=log --pipeline_config_path=log/ssd_mobilenet_v2_320x320_coco17_tpu-8.config --alsologtostderr
️模型导出(原始模型):
python exporter_main_v2.py --input_type=image_tensor --pipeline_config_path=log/ssd_mobilenet_v2_320x320_coco17_tpu-8.config --trained_checkpoint_dir=log/ --output_directory=log/eval:
**Saved_model模型验证:**
# coding: utf-8
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # Suppress TensorFlow logging (1)
import pathlib
import tensorflow as tf
import cv2
import argparse
tf.get_logger().setLevel('ERROR') # Suppress TensorFlow logging (2)
parser = argparse.ArgumentParser()
parser.add_argument('--model', help='Folder that the Saved Model is Located In',
default='log/eval/eval')
parser.add_argument('--labels', help='Where the Labelmap is Located',
default='tag_label_map.pbtxt')
parser.add_argument('--image', help='Name of the single image to perform detection on',
default='00028.jpg')
parser.add_argument('--threshold', help='Minimum confidence threshold for displaying detected objects',
default=0.5)
#home/models-master/research/object_detection/image/JPEGImages/00004.jpg
args = parser.parse_args()
# Enable GPU dynamic memory allocation
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
# PROVIDE PATH TO IMAGE DIRECTORY
IMAGE_PATHS = args.image
# PROVIDE PATH TO MODEL DIRECTORY
PATH_TO_MODEL_DIR = args.model
# PROVIDE PATH TO LABEL MAP
PATH_TO_LABELS = args.labels
# PROVIDE THE MINIMUM CONFIDENCE THRESHOLD
MIN_CONF_THRESH = float(args.threshold)
# LOAD THE MODEL
import time
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
PATH_TO_SAVED_MODEL = PATH_TO_MODEL_DIR + "/saved_model"
print('Loading model...', end='')
start_time = time.time()
# LOAD SAVED MODEL AND BUILD DETECTION FUNCTION
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
# LOAD LABEL MAP DATA FOR PLOTTING
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warnings
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
print('Running inference for {}... '.format(IMAGE_PATHS), end='')
image = cv2.imread(IMAGE_PATHS)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_expanded = np.expand_dims(image_rgb, axis=0)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis, ...]
# input_tensor = np.expand_dims(image_np, 0)
t1=time.time()
detections = detect_fn(input_tensor)
t2=time.time()
print(t2-t1)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(detections.pop('num_detections'))
detections = {key: value[0, :num_detections].numpy()
for key, value in detections.items()}
detections['num_detections'] = num_detections
# detection_classes should be ints.
detections['detection_classes'] = detections['detection_classes'].astype(np.int64)
image_with_detections = image.copy()
# SET MIN_SCORE_THRESH BASED ON YOU MINIMUM THRESHOLD FOR DETECTIONS
viz_utils.visualize_boxes_and_labels_on_image_array(
image_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=100,
min_score_thresh=MIN_CONF_THRESH,
agnostic_mode=False)
print('\n' + 'Done')
# DISPLAYS OUTPUT IMAGE
#if image_with_detections.shape[0]>1000:
#image_with_detections = cv2.resize(image_with_detections,[int(0.5*image_with_detections.shape[0]),[int(0.5*image_with_detections.shape[1]]))
#cv2.imwrite("pic/"+IMAGE_PATHS.split("/")[-1],image_with_detections)
#cv2.imwrite("test.jpg",image_with_detections)
cv2.imshow('Object Detector', image_with_detections)
#cv2.resizeWindow("Object Detector", 720,1280)
# CLOSES WINDOW ONCE KEY IS PRESSED
cv2.waitKey(0)
# CLEANUP
cv2.destroyAllWindows()
看看验证效果:

未知能否成功的冻结:
为了减少模型大小,还可以强行将save_model进行冻结(冻结代码仅供参考,还未完全验证)
import tensorflow as tf
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
# 模型path
pb_file_path = './log/eval/eval/saved_model'
# 图片path
image_path = './00028.jpg'
# 定义输入格式
img = tf.io.read_file(image_path)
img = tf.image.decode_jpeg(img, channels=3) # shape=(450, 600, 3)
img = tf.image.resize(img, (300, 300))
img = tf.expand_dims(img, axis=0) # shape=(1, 450, 600, 3)
img=tf.cast(img,dtype=tf.uint8)
# 加载模型
network = tf.saved_model.load(pb_file_path)
#奇怪的模型输出加载方式不同,若是keral则tf.keras.models.load_model
# Convert Keras model to ConcreteFunction
full_model = tf.function(lambda x: network(x))
full_model = full_model.get_concrete_function(
tf.TensorSpec(img.shape, img.dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
layers = [op.name for op in frozen_func.graph.get_operations()]
print("-" * 50)
print("Frozen model layers: ")
for layer in layers:
print(layer)
print("-" * 50)
print("Frozen model inputs: ")
print(frozen_func.inputs)
print("Frozen model outputs: ")
print(frozen_func.outputs)
# Save frozen graph from frozen ConcreteFunction to hard drive
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="./frozen_models",
name="frozen_graph.pb",
as_text=False)
二.tf1.x模型的测试
TF1.x 训练指令
️模型训练:
python object_detection/legacy/train.py --logtostderr --train_dir=training/ --pipeline_config_path=ssd_mobilenet_v2_coco.config
️模型导出(冻结图):
python object_detection/export_inference_graph.py --input_type image_tensor --pipeline_config_path ssd_mobilenet_v2_coco.config --trained_checkpoint_prefix training/model.ckpt-6000 --output_directory inference_graph
验证frozen.pb文件:
import numpy as np
import os
import glob
import tensorflow as tf
import time
from distutils.version import StrictVersion
import matplotlib
from matplotlib import pyplot as plt
from PIL import Image
import keras
import tensorflow as tf
from object_detection.utils import ops as utils_ops
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
keras.backend.tensorflow_backend.set_session(tf.Session(config=config))
# 防止backend='Agg'导致不显示图像的情况
#os.environ["CUDA_VISIBLE_DEVICES"] = "-1" #CPU
matplotlib.use('TkAgg')
if StrictVersion(tf.__version__) < StrictVersion('1.12.0'):
raise ImportError('Please upgrade your TensorFlow installation to v1.12.*.')
MODEL_NAME = 'inference_graph'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = 'tag_label_map.pbtxt'
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
def load_image_into_numpy_array(image):
im_width, im_height = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
PATH_TO_TEST_IMAGES_DIR = '00001.jpg'
TEST_IMAGE_PATHS = glob.glob(PATH_TO_TEST_IMAGES_DIR)
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[1], image.shape[2])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: image})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.int64)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
start = time.time()
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np_expanded, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=5)
print("class:",output_dict['detection_classes'])
print("score:",output_dict['detection_scores'])
end = time.time()
print("internel:",end-start)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()
看看效果:

**pb模型转换ir模型:**
需要自己安装Openvino在电脑上(运行代码前已经成功激活)
自定义模型转换ir 测试大概限于tf1.x
python mo_tf.py --input_model frozen_graph.pb --tensorflow_use_custom_operations_config extensions/front/tf/ssd_v2_support.json --tensorflow_object_detection_api_pipeline_config pipeline.config --data_type FP16
验证一下Openvino 对模型的加速力度
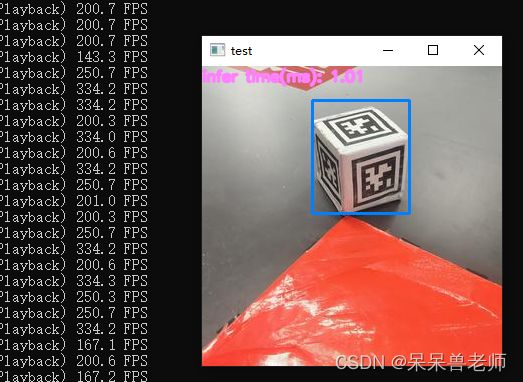
可以看到成功验证!!!
总结
入手TensorFlow一个星期,每天晚上都在查找各种报错原因,最终才发现TF1.x和TF2.x 新酒不能装旧瓶子的痛苦
好在不断坚持下,成功训练出ssd_mobilenetV2_coco的模型,并将其转换为可以intel加速的IR模型,终于把之前没有解决的问题完善了。
希望看到博客的你能够从中成功解决问题,如果有对TF2模型如何冻结优化也可以在评论区交流
由于是新人博主,希望能对文章中不对的内容指正!!!
