RepVGG backbone
前 言:
repVGG绝对可以算得上2020年在backbone方面有很大影响力的工作,其核心思想是:通过结构重参数化思想,让训练网络的多路结构(多分支模型训练时的优势——性能高)转换为推理网络的单路结构(模型推理时的好处——速度快、省内存)),结构中均为3x3的卷积核,同时,计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,最终可以使网络有着高效的推理速率(其实TensorRT在构建engine阶段,对模型进行重构,底层也是应用了卷积合并,多分支融合思想,来使得模型最终有着高性能的推理速率)。
背 景:
早起我们在设计网络时,为了获得高性能网络结构,不断进行尝试和摸索之后,得到了以下可以显著增长网络性能的结构:
(1)多分支结构:第一次出现多分支结构应该是在Inception中(如果不是,请各位指正),就获得了高性能收益,加上不同分支应用不同卷积核,能获得不同感受野,后续出现的ResNet,其残差结构也是多路结构。但是需要注意的是:多路结构需要保存中间结果,显存占有量会明显增高,只有到多路融合时,显存会会降低。这里如下图所示:
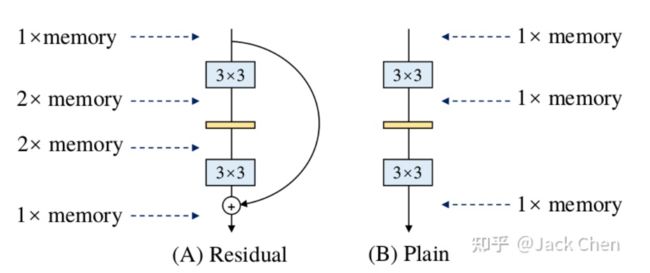
同时,由ShuffleNet论文中提到的网络高效推理法则:模型分支越少,速度越快。所以,可想而知,多分支结果虽然会带来高性能收益,但是,显存占用明显增加,且模型推理速度会一定程度降低,这在工业场景上是不实用的。
(2)性能优异组件:随着不断尝试于探索,出现了很多性能优异的网络组件,比如深度可分离卷积,分组卷积等等,这些都可以显著增加网络性能,但是,我们也知道,就拿group conv来说,当group越多是,我们知道网络性能会越好,但是,其MAC(内存访问成本)也会显著增大,最终导致模型变慢,深度可分离卷积虽然可以显著降低FLOPs,但是其MAC也会增加,最终导致模型速度变慢。
这就引发了一个矛盾,既然多分支结构和性能优异的组件能显著提高模型性能,但是,又会最终导致模型在推理时速度变慢且还非常耗内存,这非常不利于工业场景(尤其实在算力受限的情况下)。这种问题该怎么解决呢?
方案:
想要使网络具有高性能,又要有高效推理速度,怎么才能解决这个问题?repVGG给了我们答案:结构重参数化思想,也即训练时尽量用多分支结构来提升网络性能,而推理时,采用利用结构重参数化思想,将其变为单路结构,这样,显存占用少,推理速度又快。
backbone:
作者最终选择将VGG作为backbone,这里为什么要选择这么古董的玩意儿呢,而不是选择现在主流的ResNet架构?主要是基于以下三点考虑:
1. 速度快:
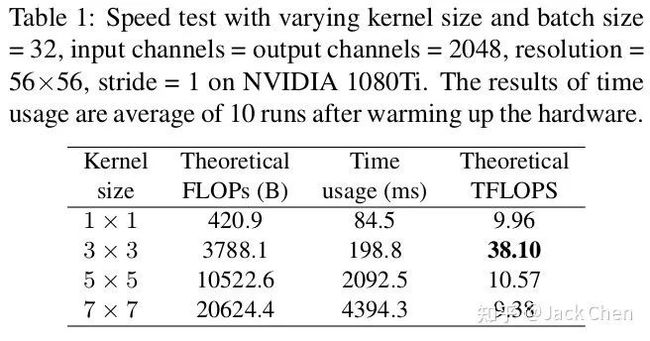
我们都知道,VGG几乎都是由3x3卷积堆叠而成,而现在加速库比如NVIDIA的cudNN,Intel的MKL和相关硬件对3x3的卷积核有非常好的性能优化,而在VGG中,几乎都是conv3x3。因此,利用现有加速库,会得到更好的性能优化,从下表就就可以看出,在相同channels、input_size和batchsize条件下,不同卷积核的FLOPs和TFLOPs和用时,可以看出,3x3卷积非常快。在GPU上,3x3卷积的计算密度(理论运算量(Theoretical FLOPs ÷ Time usage)除以所用时间)可达1x1和5x5卷积的4倍。
2. 节省内存:
VGG是一个直筒性单路结构,由上述分析可知,单路结构会占有更少的内存,因为不需要保存其中间结果,同时,单路架构非常快,因为并行度高。同样的计算量,大而整的运算效率远超小而碎的运算。
3. 灵活性好:
多分支结构会引入网络结构的约束,比如Resnet的残差结构要求输入和卷积出来的张量维度要一致(这样才能相加),这种约束导致网络不易延伸拓展,也一定程度限制了通道剪枝。对应的单路结构就比较友好,非常容易改变各层的宽度,这样剪枝后也能得到很好的加速比。
RepVGG主体部分只有一种算子: conv3x3+ReLU。在设计专用芯片时,给定芯片尺寸或造价,我们可以集成海量的3x3卷积-ReLU计算单元来达到很高的效率。别忘了,单路架构省内存的特性也可以帮我们少做存储单元。
综上所述,我们提出regVGG结构,如下图所示:
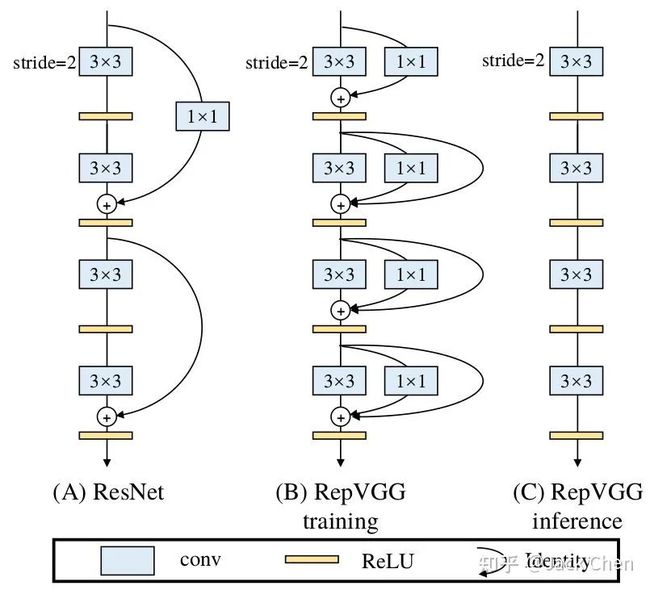
可以看到,我们在原始VGG基础上,引入和残差分支和1x1卷积分支,为了后续重参数化成单路结构,我们调整了分支放置的位置,没有进行跨层连接,而是直接连了过去,后续的对比试验也证明了残差分支和conv_1x1均能增加网络性能,如下图所示:

多路模型(train)转换单路模型(test)
网络在训练完毕后,怎样将多路模型转化为单路模型,最终部署到终端,这应该是本文的核心,如下图所示:
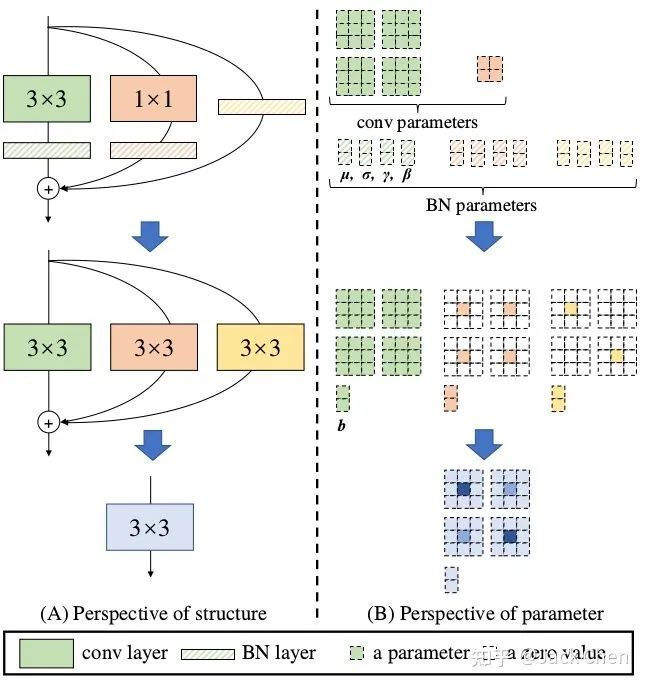
上述过程就是将train好的multi_path model 转换为single_path model,从而最终在推理时达到高性能。上面训练过程用到的模型涉及到三路:常规的conv_3x3,conv_1x1,identity,且这三路每一路都跟着BN层,下面仔细讲解这三路是怎样合并成一个conv_3x3单元的。
1. 卷积层和BN层合并:
repVGG中大量运用conv+BN层,我们知道将层合并,减少层数能提升网络性能,下面的推理是conv带有bias的过程:

这其实就是一个卷积层,只不过权重考虑了BN的参数 我们令:

最终的融合结果即为:
![]()
相关融合代码如下图所示:
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
...
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std上述融合过程是conv带有bias的,现在一般带有BN的conv几乎已经不带bias了,已经将其与BN层中的β进行合并,带有BN层的conv+bn计算过程如下图所示:

2. conv_3x3和conv_1x1合并
这里为了详细说明下,假设输入特征图特征图尺寸为(1, 2, 3, 3),输出特征图尺寸与输入特征图尺寸相同,且stride=1,下面展示是conv_3x3的卷及过程:
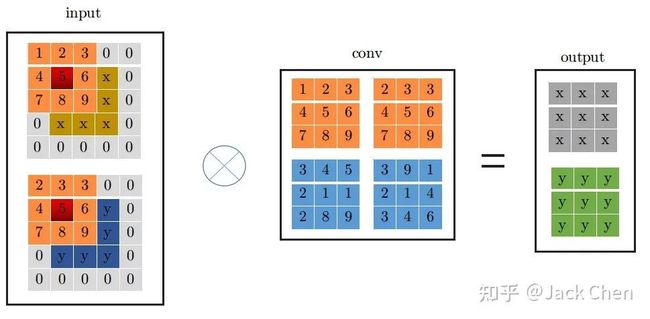
conv_3x3卷积过程大家都很熟悉,看上图一目了然,首先将特征图进行pad=kernel_size//2,然后从左上角开始(上图中红色位置)做卷积运算,最终得到右边output输出。下面是conv_1x1卷积过程:
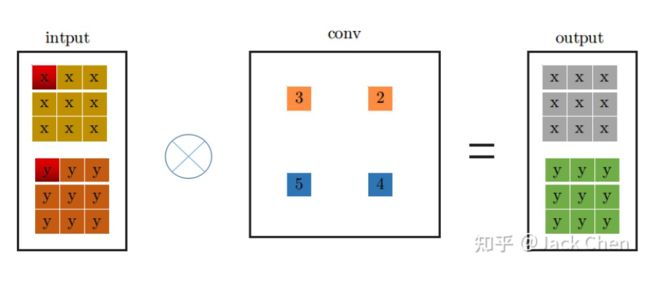
同理,conv_1x1跟conv_3x3卷积过程一样,从上图中左边input中红色位置开始进行卷积,得到右边的输出,观察conv_1x1和conv_3x3的卷积过程,可以发现他们都是从input中红色起点位置开始,走过相同的路径,因此,将conv_3x3和conv_1x1进行融合,只需要将conv_1x1卷积核padding成conv_3x3的形式,然后于conv_3x3相加,再与特征图做卷积(这里依据卷积的可加性原理)即可,也就是conv_1x1的卷积过程变成如下形式:
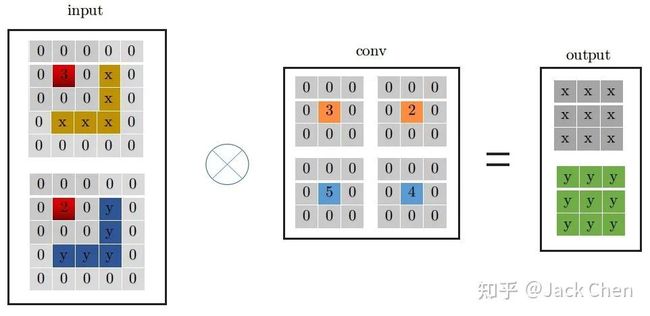
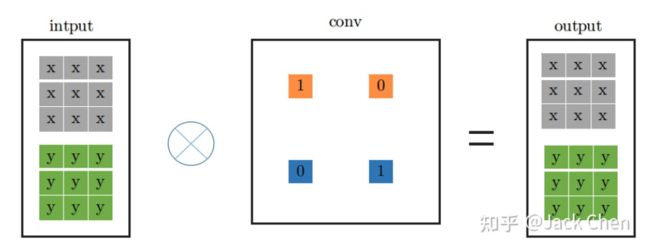
3. identity 等效为特殊权重的卷积层
identity层就是输入直接等于输出,也即input中每个通道每个元素直接输出到output中对应的通道,用一个什么样的卷积层来等效这个操作呢,我们知道,卷积操作必须涉及要将每个通道加起来然后输出的,然后又要保证input中的每个通道每个元素等于output中,从这一点,我们可以从PWconv想到,只要令当前通道的卷积核参数为1,其余的卷积核参数为0,就可以做到;从DWconv中可以想到,用conv_1x1卷积且卷积核权重为1,就能保证每次卷积不改变输入,因此,identity可以等效成如下的conv_1x1的卷积形式:
从上面的分析,我们进一步可以将indentity -> conv_1x1 -> conv_3x3的形式,如下所示:
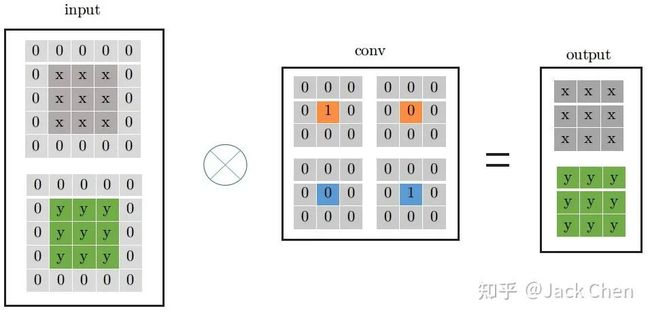
上述过程就是对应论文中所属的下述从step1到step2的变换过程,涉及conv于BN层融合,conv_1x1与identity转化为等价的conv_3x3的形式:
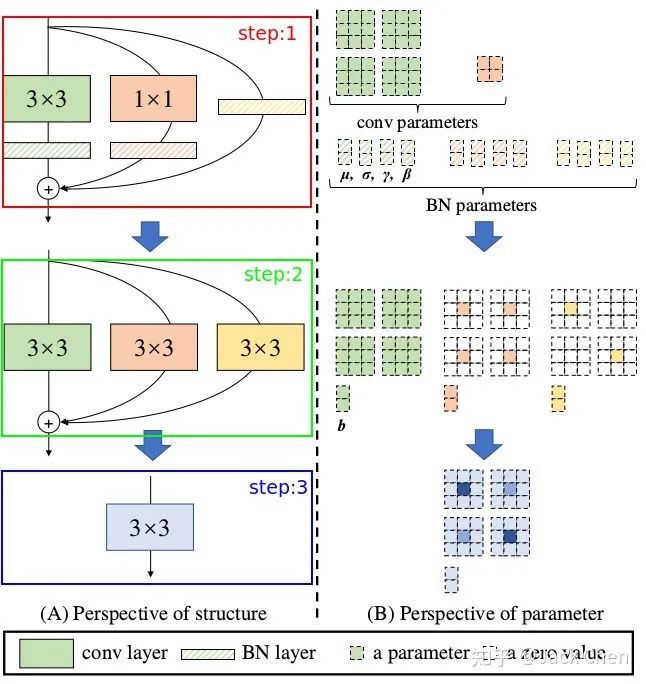
结构重参数化的最后一步也就是上图中step2 -> step3, 这一步就是利用卷积可加性原理,将三个分支的卷积层和bias对应相加组成最终一个conv_3x3的形式即可。
感想:
repVGG总的来说,是一篇非常棒的关于backbone工作,将常规的工作思路:train model -> deploy model,转换为:train model -> redefine model -> deploy model,我猜测与TensorRT在根据train model构建高效率的inference engine思路一样,tensorRT对模型进行加速,也是在模型进行优化和等效变换,看下述模型:
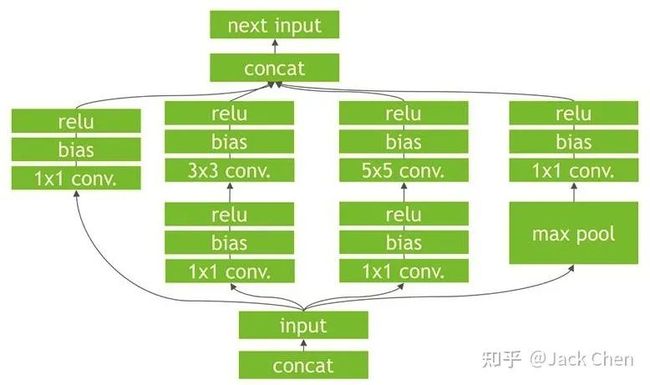
可以看到上图中很多零散的OP节点,我们知道OP越多,会导致网络推理越慢,因为,cudnn是一个动态库,对于每个op,程序运行时都是需要在.so库(Win系统下是.dll)找到对应的实现,因为会导致推理变慢。
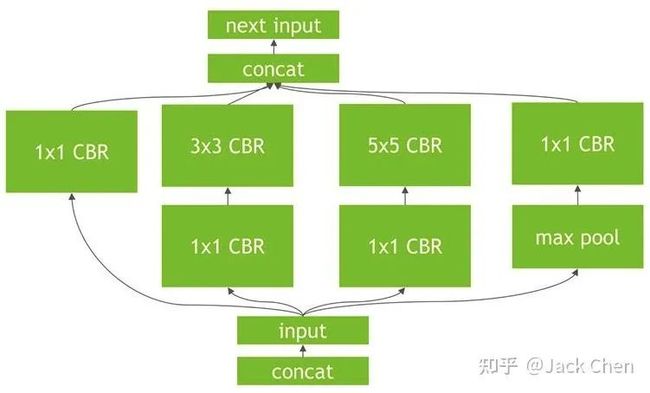
TensorRT的优化如上图,将CONV+BN+ReLU层进行合并(也称之为*垂直融合*),至于为什么上图中写的是bias而不是BN层,这是因为,带有BN的层的conv的实现,其bias和BN层的beta项进行合并了。

进一步的发现,TensorRT会继续做合并优化处理,在上图的基础上,你会发现conv_1*1被合并成了一个超级大的层。这里是水平融合机制,也即在同一个level层面上的相同操作进行融合。
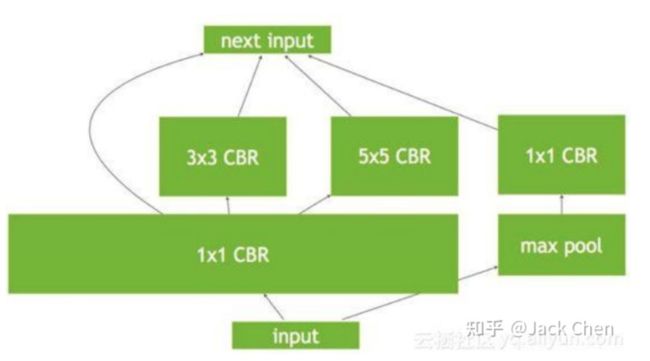
最后,进一步取消一些没必要的层,比如concat操作。
对于模型加速和模型等效以及部署加速工作,repVGG给了我们很多启发,此外,丁霄汉大佬的另外一篇优秀论文:arxiv.org/pdf/1908.0393, ACNet,后续会深入研究这篇论文。
参考文献:
[1]. 郑泽康:图解RepVGG
[2]. https://zhuanlan.zhihu.com/p/344324470
原文连接:https://www.cnblogs.com/shuimuqingyang/p/14472515.html