mRMR算法解析
1. 绪论
在特征选择过程中,有一种算法叫做mRMR(Max-Relevance and Min-Redundancy)。其原理非常简单,就是在原始特征集合中找到与最终输出结果相关性最大(Max-Relevance),但是特征彼此之间相关性最小的一组特征(Min-Redundancy)。
本文主要对彭汉川老师的提出mRMR算法进行翻译解读。
Hanchuan Peng, Fuhui Long, and Chris Ding, "Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy,"
IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 27, No. 8, pp.1226-1238, 2005. [PDF]
2. 具体算法解读
2.1 Max-Dependency与Max-Relevance and Min-Redundancy算法的关系
提到互信息,特征选择的目的是找到一个具有m个特征{ }的特征子集S,这些特征与目标分类c有最大的依赖性。这种方法叫做Max-Dependency,其公示表示如下:
}的特征子集S,这些特征与目标分类c有最大的依赖性。这种方法叫做Max-Dependency,其公示表示如下:
![]()
很明显,当m=1时,就是最大化互信息![]() 。当m>1时,一个简单的增量搜索策略就是每次增加一个特征:给定m-1个特征子集
。当m>1时,一个简单的增量搜索策略就是每次增加一个特征:给定m-1个特征子集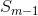 ,第m个特征选择对于互信息
,第m个特征选择对于互信息![]() 增加最大的特征,可以得到以下公式:
增加最大的特征,可以得到以下公式:
![]()
![]()
![]()
尽管最大依赖性理论上可以计算得到,但是由于在高维空间中存在两大问题,通常很难获得概率密度函数![]() 和
和![]() :1)采样的数量通常并不充分;2)要求解多变量密度估计需要计算高维相关矩阵的逆矩阵,这是一个很难求解的问题。最大相关性的另外一个缺点是计算速度慢。这些问题在在连续特征变量时更为突出。
:1)采样的数量通常并不充分;2)要求解多变量密度估计需要计算高维相关矩阵的逆矩阵,这是一个很难求解的问题。最大相关性的另外一个缺点是计算速度慢。这些问题在在连续特征变量时更为突出。
即使针对于离散特征,在实际应用中以上问题也不能完全避免。例如,假设每个特征有三个不同的状态,共进行N次采样。K个特征具有最多![]() 个联合状态。当联合状态迅速增加到与采样数量N达到一个数量级时,则这些特征的联合概率、互信息不能被很好的估计。因此,尽管最大依赖特征选择算法在特征少并且采样多的情况下很实用,但是在特征数量多的情况下并不适用。
个联合状态。当联合状态迅速增加到与采样数量N达到一个数量级时,则这些特征的联合概率、互信息不能被很好的估计。因此,尽管最大依赖特征选择算法在特征少并且采样多的情况下很实用,但是在特征数量多的情况下并不适用。
2.2 Max-Relevance and Min-Redundancy
由于Max-Dependency很难实现,一个替代的选择是Max-Relevance(最大相关性)。最大相关性是搜索满足以下公式的特征:
![]()
其中采用所有特征 与分类c之间的互信息的平均值来近似
与分类c之间的互信息的平均值来近似![]()
通过Max-Relevance选择的特征可能具有冗余,这些特征之间的依赖性非常大。当两个特征互相冗余,当去掉其中一个的时候,分类结果并不会有非常大的变化。因此Min-Redundancy方式可以用来剔除掉冗余特征:
![]()
将最大相关性D与最小冗余度R结合起来,我们称其为minimal-redundancy-maximum-relevancy(mRMR)。我们定义算子![]() 用来结合D与R,考虑最简单的结合方式:
用来结合D与R,考虑最简单的结合方式:
![]()
在实际应用中,采用定义的算子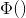 ,采用增量搜索方法可以得到近似最优解。假设已经获得特征子集,需要在剩余的
,采用增量搜索方法可以得到近似最优解。假设已经获得特征子集,需要在剩余的![]() 的特征子集内选择出第m个特征。通过最大化来进行选择特征,即最大化:
的特征子集内选择出第m个特征。通过最大化来进行选择特征,即最大化:
![]()
该算法计算复杂度为![]()
3. 算法实现
以下算法为彭汉川在matlab贴出来的实现算法,具体网址为https://www.mathworks.com/matlabcentral/fileexchange/14608-mrmr-feature-selection-using-mutual-information-computation
function [fea] = mrmr_miq_d(d, f, K)
% function [fea] = mrmr_miq_d(d, f, K)
% d-输入N*M矩阵,N个采样值,M个特征,特征向量
% f-输入的N*1向量,分类结果
% K-选择的葛铮的个数
% MIQ scheme according to MRMR
%
% By Hanchuan Peng
% April 16, 2003
%
bdisp=0;
nd = size(d,2);%特征个数
nc = size(d,1);%采样个数
t1=cputime;
for i=1:nd
t(i) = mutualinfo(d(:,i), f);%分别计算每个特征与分类f之间的互信息
end
fprintf('calculate the marginal dmi costs %5.1fs.\n', cputime-t1);
[tmp, idxs] = sort(-t);%按照计算的互信息降序排列,tmp存储的是降序排列的值,idxs为原来的序号
fea_base = idxs(1:K);%取前k个特征的序号,赋值给fea_base
fea(1) = idxs(1);%将互信息最大的特征赋值给fea(1)
KMAX = min(1000,nd); %如果特征多于1000个,则首先选择前1000个
idxleft = idxs(2:KMAX);%获得剩余特征的序号
k=1;
if bdisp==1
fprintf('k=1 cost_time=(N/A) cur_fea=%d #left_cand=%d\n', ...
fea(k), length(idxleft));
end
for k=2:K
t1=cputime;
ncand = length(idxleft);%获得剩余特征的个数
curlastfea = length(fea);%获得当前已选择的特征数
for i=1:ncand
t_mi(i) = mutualinfo(d(:,idxleft(i)), f); %计算剩余特征与分类f之间的互信息,相当于公式中的D
mi_array(idxleft(i),curlastfea) = getmultimi(d(:,fea(curlastfea)), d(:,idxleft(i)));%计算每个特征之间的互信息
c_mi(i) = mean(mi_array(idxleft(i), :)); %求特征之间互信息的平均值,相当于公式中的R
end
% [tmp, fea(k)] = max(t_mi(1:ncand) ./ c_mi(1:ncand));
[tmp, fea(k)] = max(t_mi(1:ncand) ./ (c_mi(1:ncand) + 0.01));
%此处与公式中不一样,此处用的是D/R的最大值作为标准,+0.01是为了避免c_mi为0的情况
tmpidx = fea(k); fea(k) = idxleft(tmpidx); idxleft(tmpidx) = [];
%选择第k个特征
if bdisp==1
fprintf('k=%d cost_time=%5.4f cur_fea=%d #left_cand=%d\n', ...
k, cputime-t1, fea(k), length(idxleft));
end
end
return;
%=====================================
function c = getmultimi(da, dt)
for i=1:size(da,2)
c(i) = mutualinfo(da(:,i), dt);
end