TensorRT推理手写数字分类(一)
系列文章目录
(一)使用pytorch搭建模型并训练
文章目录
- 系列文章目录
- 前言
- 一、网络搭建
-
- 1.LeNet网络结构
- 2.pytorch代码
- 二、网络训练
-
- 1.pytorch代码
- 2.结果展示
- 三、保存和加载模型
-
- 1.保存整个网络
- 2.保存网络中的参数
- 总结
前言
为了学习一下使用TensorRT进行推理的全过程,便想着写一个TensorRT推理手写数字分类的小例程。这个例程包括使用pytorch进行LeNet网络的搭建、训练、保存pytorch格式的模型(pth)、将模型(pth)转为onnx通用格式、使用tensorRT解析onnx模型进行推理等。
本节介绍使用pytorch进行手写数字分类网络的搭建,并进行训练。
一、网络搭建
1.LeNet网络结构
网络结构图如下所示:
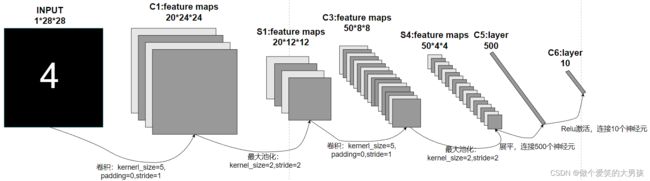
结构说明:输入是单通道的12828的灰度图像,经过卷积、池化、卷积、池化后shape变为5044(50为通道数)。将其展平后维度为1*800,然后连接一个维度为500的线性层C5,C5层的输出经过ReLU函数激活后再连接一个维度为10的线性层C6,C6层的输出就为网络的输出。
一般来说,我们要求的是输入图片属于某一类的概率,所有我们要将C6的输出通过softmax函数进行转换。
2.pytorch代码
新建model.py文件,包含以下代码:
# 搭建网络模型
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary #用来打印网络层的信息
# from torchkeras import summary module 'torch.backends' has no attribute 'mps'
class Net(nn.Module):
def __init__(self) -> None:
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 20, kernel_size=5)
self.conv2 = nn.Conv2d(20, 50, kernel_size=5)
self.fc1 = nn.Linear(800, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), kernel_size=2, stride=2)
x = F.max_pool2d(self.conv2(x), kernel_size=2, stride=2)
x = x.view(-1, 800) # 将其展平
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1) # 要使用NLLLoss()损失函数,所以输出要先经过log_softmax
if __name__ == "__main__":
net = Net()
summary(net, (1,1,28,28))
二、网络训练
1.pytorch代码
新建train.py,包含以下代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from model import Net
import numpy as np
import os
import torch.utils.data
from random import randint
class MnistModel(object):
def __init__(self):
self.batch_size = 64 # 训练batch_size
self.test_batch_size = 100 # 测试batch_size
self.learning_rate = 0.0025 #学习率
self.sgd_momentum = 0.9
self.log_interval = 100
# 构造数据
self.train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"./tmp/mnist/data",
train=True,
download=True,
transform=transforms.Compose( # 预处理:对训练数据只进行标准化
[transforms.ToTensor(),
transforms.Normalize((0.1307),(0.3081,))])
),
batch_size=self.batch_size,
shuffle=True,
num_workers=4,
timeout=600,
)
self.test_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"./tmp/mnist/data",
train=False,
transform=transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307),(0.3081,))])
),
batch_size = self.test_batch_size,
shuffle = True,
num_workers=4,
timeout=600,
)
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
self.network = Net()
self.network.to(self.device)
def learn(self, num_epochs=2): # 训练两个epoch
#
# Train the network for a single epoch
def train(epoch):
self.network.train()
optimizer = optim.SGD(self.network.parameters(), lr=self.learning_rate, momentum=self.sgd_momentum) # 使用SGD优化器
for batch, (data, target) in enumerate(self.train_loader):
data, target = Variable(data.to(self.device)), Variable(target.to(self.device))
optimizer.zero_grad()
output = self.network(data)
loss = F.nll_loss(output, target).to(self.device)
loss.backward()
optimizer.step()
if batch % self.log_interval == 0: #每100个batch打印一次信息
print(
"Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}".format(
epoch,
batch * len(data),
len(self.train_loader.dataset),
100.0 * batch / len(self.train_loader),
loss.data.item(),
)
)
# Test the network
def test(epoch):
self.network.eval()
test_loss = 0
correct = 0
for data, target in self.test_loader:
with torch.no_grad():
data, target = Variable(data.to(self.device)), Variable(target.to(self.device))
output = self.network(data)
test_loss += F.nll_loss(output, target).data.item()
pred = output.data.max(1)[1] # 输出最大值的索引为预测的类别
correct += pred.eq(target.data).cpu().sum()
test_loss /= len(self.test_loader)v # 测试集每一个batch的平均损失
print(
"\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n".format(
test_loss, correct, len(self.test_loader.dataset), 100.0 * correct / len(self.test_loader.dataset)
)
)
for e in range(num_epochs):
train(e + 1)
test(e + 1)
train_model = MnistModel()
train_model.learn()
总的来说,训练代码中没有太值得让人注意的地方。如果非要说有,那我觉得以下三点可能是要注意的地方:
- 对输入的预处理,转为Tensor,然后作了标准化(均值为0,标准差为1),除此之外再也没有做其他的操作。
- 损失函数这里,我们决定使用交叉熵损失函数。因为我们在定义网络时,网络最后一层的输出经过了log_softmax,所以这里使用了nn.NLLLoss()损失函数即可。如果你网络最后一层的输出没有经过log_softmax,那么你可以使用nn.CrossEntropyLoss(),因为nn.NLLLoss()+log_softmax=nn.CrossEntropyLoss()。在代码中,我们使用的是F.nll_loss()函数,其实与nn.NLLLoss()没有区别(nn.NLLLoss()类其实也是调用F.nll_loss()函数)。
- 这里选择只训练两个epoch,是因为我在训练的时候,两个epoch后网络在验证集上就有比较好的效果,网络训练打印的信息在结果展示中贴出。
2.结果展示
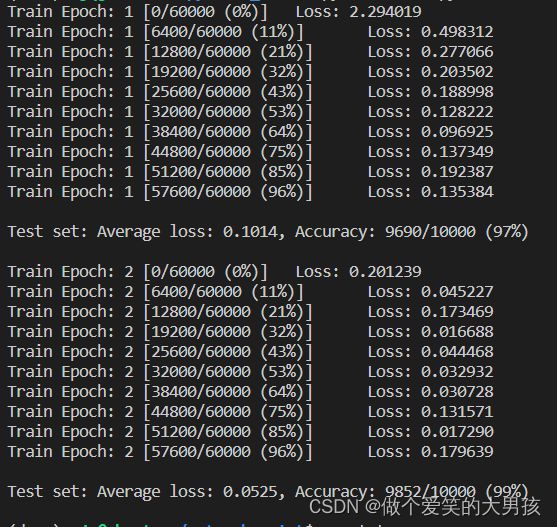
可以看到,两个epoch后,模型的准确率为99%,所以我选择停止训练,然后保存模型。
三、保存和加载模型
在pytorch中保存模型有两种形式,一种是保存整个网络,一种是只保存网络中的参数。
1.保存整个网络
保存整个网络的方法如下:
# 保存整个网络
torch.save(net, path)
# 加载网络
model = torch.load(path)
2.保存网络中的参数
只保存网络中的参数的方法如下:
# 保存
torch.save(net.state_dict(), path)
# 加载
model = model.load_state_dict(torch.load(path))
在这个demo中,我们只需要在train.py后加上
torch.save(net.state_dict(), './model.pth')
就可以保存模型为model.pth文件。
总结
本节我们进行了模型的搭建、训练以及保存模型。下一节我们将介绍如何将我们保存的pth文件转为onnx通用格式,同时对我们转成的onnx文件进行检查和验证。