最近火爆了的对话ChatGPT
前言
相信最近小伙伴们已经被ChatGPT的惊艳效果刷屏了,之前笔者也介绍过一些对话方向的工作,感兴趣的小伙伴可以穿梭:
对话系统最新综述II https://zhuanlan.zhihu.com/p/446760658
在对话系统中建模意图、情感: https://zhuanlan.zhihu.com/p/468317109
对话模型背后可以做更多事: https://zhuanlan.zhihu.com/p/458097616
但今天要介绍的ChatGPT可以说是非常值得一看的,其不但能够回答日常的一些基本问题而且能够改代码修bug,关键是回答的什么之流畅通顺且严谨,强烈建议关注ChatGPT。
而且其目前也支持中文,效果也是什么的惊艳!网上目前已经有许许多多有意思的case了,大家随便搜搜就可以看得到,比如 ChatGPT教学习知识图谱
更有甚者觉得其会颠覆现在已有的搜索引擎,其实单从效果来看其可以渗透的场景非常之多:搜索、客服、机器人等等。
其目前也是在短短的五天时间内迎来了百万用户的体验,这个效果突破也算是NLP业界一大幸喜之事了吧,很开心,哈哈哈
那么ChatGPT究竟做了什么才导致其有这么好的效果呢?让我们来看看吧~
链接:https://openai.com/blog/chatgpt/
方法
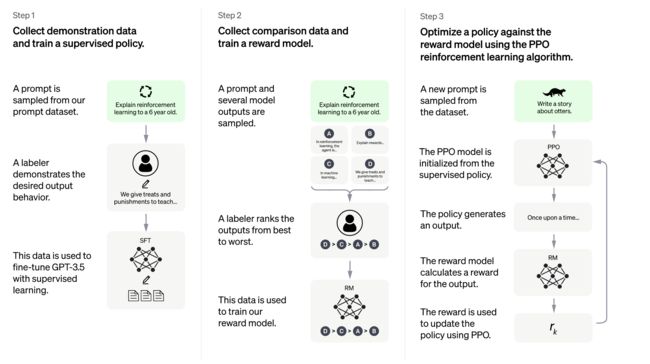
ChatGPT主要的训练流程如上所示,主要包含三个阶段
- 第一阶段
在GPT-3.5基础上训练一个加强版chat模型,其中GPT-3.5是一个很强的语言模型backbone,具体的做法就是从训练集中随机抽取一些prompt,然后由标注人员去根据prompt给出一个高质量合理的answer,于是乎就有了
- 第二阶段
基于第一步训练好的模型,每当来一个prompt,模型就会产生n个answer(比如上图中是4个输出),然后此时又会请标注人员来为这n个answer的生成质量进行排序,可以看到这最后其实也是一份标注数据,基于这个标注数据就可以训练一个reward model,其实就是个打分模型,这个模型的目标就是尽可能给每个answer打的分数和人标注的相同,更具体的就是要体现出次优之分,比如上图标注的answer质量是D>C>A>B,那么reward model在给D的打分也有高于给C打的分。
- 第三阶段
现在经过一二阶段,手头已经有了一个还不错的chat模型以及一个可以评判生成效果好坏的reward model模型,为了使得最终的模型效果更好,于是就可以让这两个模型或者说这两个阶段多循环几遍,循序渐进、彼此增益迭代、越来越好。
具体的方法,ChatGPT的研究者们采用的是强化学习RL,用第二阶段的粉丝作为奖励来更新第一阶段的chat模型,这也是为什么作者将第二阶段的模型称为reward model的原因。
- 小结
到这里就全部介绍完了,是不是整个过程还是比较清晰且容易理解的,但是很难想象在标注这里ChatGPT究竟投入了多少!最后这个惊艳的效果笔者感觉很大一部分增益也是得益于这个reward model或者说这里源源不断的高质量标注数据,这个投入应该是巨大的。
ChatGPT目前存在的一些问题
研究员们同时也提出了一些ChatGPT目前的badcase
- ChatGPT 有时会写出看似合理但不正确或荒谬的答案
研究员们认为要解决这个问题是具有一定挑战性的,因为(1)在强化学习训练期间,没有真真意义上的正确答案 (2) 因为在训练模型的时候为了保住生成结果的严谨性,导致模型比较谨慎,不敢多回答,其实一些问题本来可以大胆正确回答出来的 (3) 监督训练这一范式也会导致模型学偏,使得其更加偏向于学习标注人员自己知道的,而不是真真的。
- ChatGPT 对输入的prompt很敏感
同样一个问题,可能前后稍加修改或者说微调,那么ChatGPT的反馈是大不一样的,有可能前一次是拒绝回答,后面稍微改一下输入,语义什么的都一样,但是ChatGPT就可以回答出来了。
- ChatGPT 回答通常是过于冗长并过度使用某些短语
ChatGPT很喜欢用一些固定的短语,比如它会经常说它是OpenAI训练出来的语言模型,这其实和训练语料的偏置有关,比如其答案通常都很长的原因就是标注人员标注的好结果通常来说都是比较长的,因为在标注人员看来长一点的句子通常来说更全面、更让人理解。
- ChatGPT 自己做主
理想情况下,当用户提问出模棱两可的问题时,模型的做法应该是去进一步询问确认出清晰的问题后再回答。但是现在的ChatGPT通常会自作主张的猜测用户的意图。
- ChatGPT 安全内容问题
其实这也是对话领域的通病,就是怎么拒绝回答一些不友好话题的问题,目前其用了Moderation API来告警这些不安全的内容,但是可以预见的是还是会不可避免的有漏洞
总结
总的来说,虽然长路漫漫,但是看到这个现象级的效果升级,还是很开心的。其让相关的研究者看到了一丝曙光,也让一些之前基于AI的智能生活场景更可能早一点的到来。还有一点就是怎么把这么大的模型在线上成本降下来,让其真真能够落地服务千万家,也是一个很重要有意义的课题。
期待、共勉~
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布