sklearn.preprocessing.MinMaxScaler
sklearn.preprocessing.MinMaxScaler(feature_range=(0, 1), copy=True)将数据的每一个特征缩放到给定的范围,将数据的每一个属性值减去其最小值,然后除以其极差(最大值 - 最小值)
原理实现:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
缩放回去:
X_scaled = X_std * (max - min) + min
Parameters(参数):
feature_range : tuple (min, max), default=(0, 1)
所需的转换数据范围。
copy : boolean, optional, default True
是否将转换后的数据覆盖原数据,默认为false.
Attributes(属性):
min_ : 每个特征调整的最小值
scale_ :每个特征数据缩放的比例
data_min_ : 每个特征的最小值
data_max_ : 每个特征的最大值
data_range_ :*数据中看到的每个特征范围(data_max_-data_min_)Methods(方法):
fit(self, X[, y]) 计算用于以后缩放的最小值和最大值fit_transform(self, X[, y]) Fit 数据, 然后 transform
get_params(self[, deep]) 得到这个estimator .的参数
inverse_transform(self, X) 根据feature_range撤消X的缩放比例
partial_fit(self, X[, y]) Online computation of
min and max on X for later scalingset_params(self, **params)
设置此 estimator(估计器,评估器) 的参数transform(self, X) 根据feature_range缩放X 的特征
from sklearn.preprocessing import MinMaxScaler
data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
scaler = MinMaxScaler(feature_range=(0, 1))
scaler.fit(data) #找出每列最大、小值,并存储
scaled_df = scaler.transform(data) #将df进行转化到(0,1)间
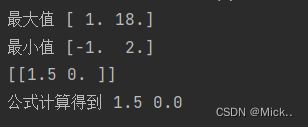
print('最大值',scaler.data_max_) #查看最大值
print('最小值',scaler.data_min_) #查看最小值
# scaled_df = scaler.fit_transform( data ) 将fit,transform一步到位
scaler.inverse_transform( scaled_df ) #将数据返回到原来的范围
print(scaler.transform([[2, 2]]))
print('公式计算得到',(2+1)/2,(2-2)/16)
"""
# 将数据scale为(0,1)间数据
scaled_data = (data - data.min()) / (data.max()-data.min())
# 将(0,1)间数据scale回原来的范围
scaled_data * (data.max() - data.min()) + data.min()
"""
#导⼊入需要的模块和库
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
#建立数据集
class_1 = 500
class_2 = 500 #两个类别分别设定500个样本
centers = [[0.0, 0.0], [2.0, 2.0]] #设定两个类别的中心
clusters_std = [0.5, 0.5] #设定两个类别的方差
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y
,test_size=0.3
,random_state=420)
#去除列表中重复的元素,并按照由大到小返回一个新的无重复元素的列表
print(np.unique(Ytrain))
print((Ytrain==1).sum())
print((Ytrain==1).sum()/Ytrain.shape[0])
#归一化
mms = MinMaxScaler().fit(Xtrain)
Xtrain_ = mms.transform(Xtrain)
Xtest_ = mms.transform(Xtest)