推荐一些视觉SLAM的深度学习方法(上)
最近也看了一些VSLAM综述文章,这里收集一些论文推荐供参考。
1。Deep Direct Visual Odometry
这篇论文把DL模型的姿态估计做为传统方法DSO的初始化。如图

DL 模型架构图如下

基于非监督学习的训练框架如下(同时还有depth估计一起训练)

2。Deep Virtual Stereo Odometry: Leveraging Deep Depth Prediction for Monocular Direct Sparse Odometry
这也是在DSO嵌入深度学习模型的方法,改成depth预测辅助初始化。如图所示

其中的depthnet模型架构如图(视差估计)

3。D3VO: Deep Depth, Deep Pose and Deep Uncertainty for Monocular Visual Odometry
这个工作是VO,但仍然有前后台(frontend做跟踪,backend做优化)。这里深度学习参与前后台,给出depth和pose的信息。其框架如下

前台的factor graph结构图(关键帧)

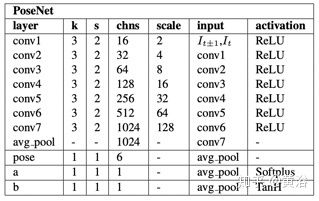
而深度学习模型:posenet和depthnet如下表

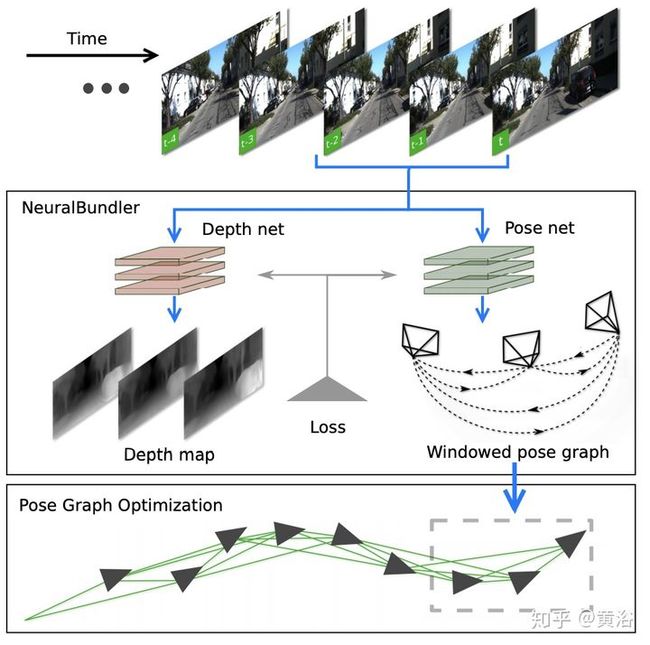
4。Pose Graph Optimization for Unsupervised Monocular Visual Odometry
同样具有前后台的VO,采用非监督学习的DL模型。如图框架所示
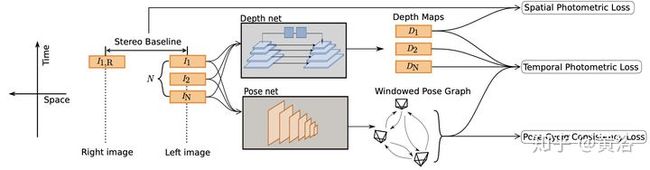
这里PGO分别在局部的滑行窗和全局进行,但没有做SLAM的loop closure和keyframe。如下是DL模型的训练框架(depth和pose),需要双目。
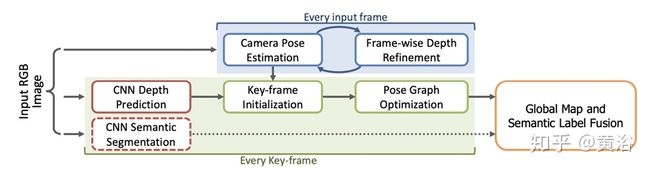
5。CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
同样将深度学习的depth估计去初始化传统SLAM,这里基于LSD-SLAM(半致密法),同时还采用DL的语义分割对生成的全局图做语义融合。如图所示:
6。Self Improving Visual Odometry
这是MagicLeap的工作,基于DL的特征点提取SuperPoint模型和特征点匹配SuperGlue模型,提出一个自监督的VO框架,如图

7。BA-Net
这个方法是除了前端深度图估计之外,还想用DL解决SLAM的后端优化,即BA。如图是框架图

其中的depthnet部分是如下结构
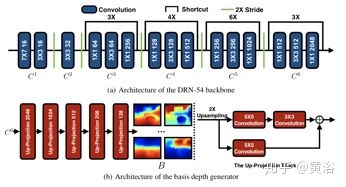
而其中的BA-layer如图(非线性迭代L-M)
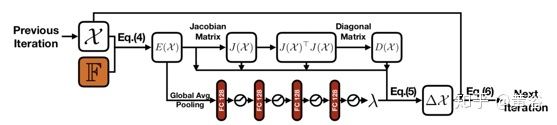
8。Self-Supervised Learning of Depth and Ego-motion with Differentiable Bundle Adjustment
该方法类似,只是扩展了前端,即depthnet和posenet,如图

这里BA layer如图:

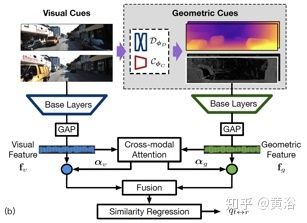
9。Geometry-Aware Learning of Maps for Camera Localization
这是Nvidia的工作,不同于前面方法,采用深度学习做image-based re-localization的思路,但采取VO和PGO增强。如图所示MapNet

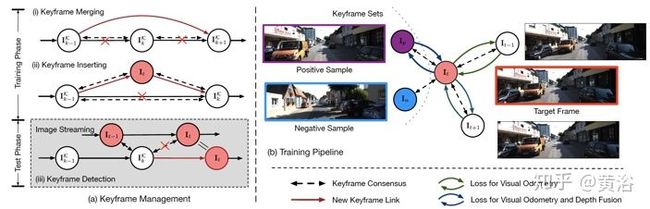
10. Unsupervised Collaborative Learning of Keyframe Detection and Visual Odometry Towards Monocular Deep SLAM
该论文特意通过深度学习,对关键帧提取进行训练,基本框架如图

其中VO包括depthnet和posenet,加上keyframe extractor,如图所示

关于keyframe的管理更新和训练框架,见下图
待续。。。