neo4j构建郑州2022-年前疫情知识图谱
neo4j构建知识图谱
(python编程疫情知识图谱)
一、知识图谱简介
历史由来什么虚头八脑的咱就直接跳过了,说一说我自己对知识图谱的理解吧。知识图谱理解起来很简单,知识+图谱。把知识用图谱的形式展示出来,这就是知识图谱。而这里知识又是泛指一切事物,那这样就很好理解了,那就是一切事物以图的形式来展示,这,就是知识图谱(我理解的,不一定对)!
那好,既然这样,咱直接上图,帮助各位更好地理解什么叫做知识图谱
请问,这是什么?

这就是知识,因为按照我的理解,知识泛指一切事物
所以他就是知识!(好像和课本里学到的知识怎么差距就这么大呢,手动狗头…)
那好,我们再来看一个图!
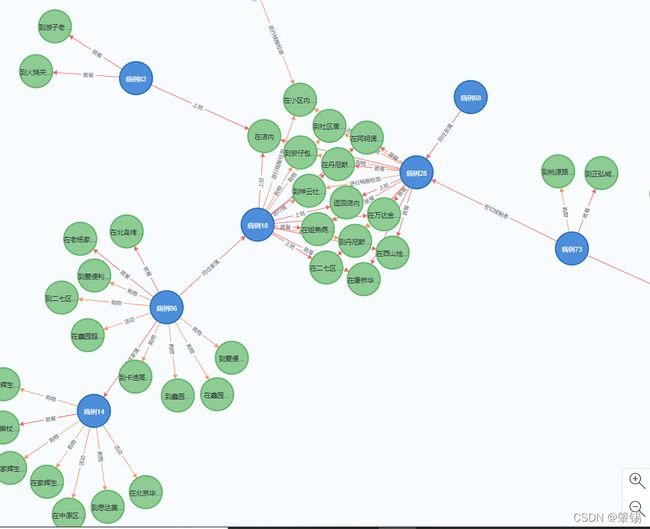
这又是什么?这就是知识图谱,是不是很直观了?
无非就是把上面所说的知识抽取到我所有用的东西,再把它可视化出来。
官方一点儿来说,知识图谱无非就是好多好多个三元组所构成的一系列关系型数据库,存储形式为三元组形式,展示出来为图谱。所以知识图谱就是这么简单。
其实,我个人认为构建知识图谱的目的不在于构建,而在于利用构建好的知识图谱(现有的知识)去推测未知的知识,这才是知识图谱的重要之处。比如说就拿我上述的例子来看,上述例子为年前郑州疫情的例子。数据获取就是从郑州发布公众号中获取到知识,然后再用neo4j这个软件去搭建这样一个图谱,再通过neo4j数据库的语言去进行分析,获取到一些有用的知识。为了直观展示,再给大家看一个图
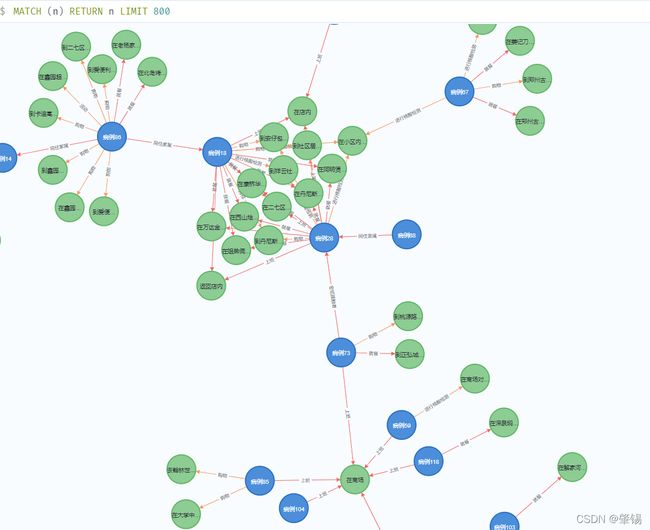
很直观的,病例18和病例28之间说让没有什么关系,当时他们却去过很多相同的地方,那这些地方就很可能是高危感染疫情的地方。我们所得到的高危感染疫情的这个知识,就是未知的知识。我们通过构建知识图谱所获取到的知识。
构建知识图谱的步骤
那好,既然这样,我们简单梳理一下需要做的几个问题。
一、知识从何而来?
万物互联的时代,知识当然要靠爬虫而来。因此针对这个实例,我们获取到所有知识,均是从公众号所在的网页爬取下来的。
具体学习爬虫相关的知识,请看我的其他博客:https://blog.csdn.net/petrichor316/category_11603104.html
二、图谱从何而来?
利用neo4j软件,在python编程平台通过py2neo函数包进行构建三元组关系,也就是我们的图谱。
三、未知的知识从何而来?
通过neo4j软件他的数据库语言进行分析而来。
简要的展示代码:
一、爬取知识:
通过最近的一个网页获取到有关的所有网页
def gettitle(self):
"""获取到活动轨迹的通报以及病例"""
req = requests.get(url=self.target)
req.encoding = 'utf-8'
html = req.text
# 获取到文本及网址信息
bs = BeautifulSoup(html, 'lxml')
headlines = bs.find('section', style="font-size: 16px;white-space: normal;")
headlines = headlines.find_all('a')
# title1 = bs.find('h1', id="activity-name").string
# 得到所有的网址
websites = []
titles = []
websites.append(self.target)
# titles.append(title1)
for headline in headlines:
# print('爬取网址中...',headline)
website = headline.get('href')
# title = headline.find('span').string
# print(title)
# titles.append(title)
print('爬取网页中...',website)
websites.append(website)
websites.append('https://mp.weixin.qq.com/s/MenNRSpSA5ORNGtjosfZLw')
websites.append('https://mp.weixin.qq.com/s/PLyt4qip04CBp8jF9wXO9g')
# time.sleep(1)
print('爬取完毕,正在整理数据,马上呈现......')
# texts.append(text)
# print(websites)
# print(titles)
return websites
紧接着获取所有的网页中的内容。
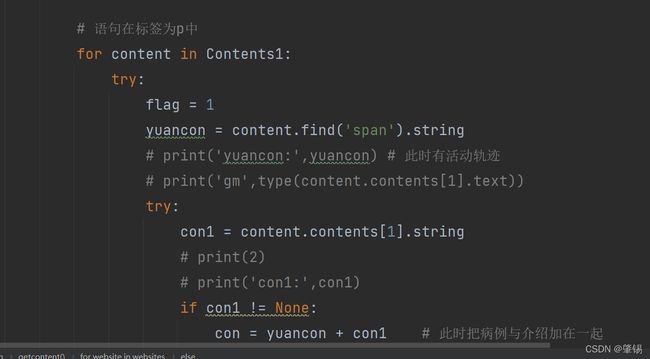
由于网页标签不规范,导致代码过长,仅展示部分源码。
二、构建图谱
创建三元组中的每一个节点
def CreateNode(self):
"""创建病例的节点"""
for names in self.perdir:
ids = self.perdir[names]['属性']['姓名']
trenders = self.perdir[names]['属性']['性别']
ages = self.perdir[names]['属性']['年龄']
# print(ids,trenders,ages)
add = []
fri = []
adds = ()
fris = ()
for attrs in self.perdir[names]['属性']:
# print(attrs)
if bool('地址' in attrs):
# print(attrs)
# print(self.perdir[names]['属性'][attrs])
add.append(self.perdir[names]['属性'][attrs])
elif '家属' in attrs:
# print(self.perdir[names]['属性'][attrs])
fri = self.perdir[names]['属性'][attrs]
# print(fri)
# print('names',names)
if len(add) == 1:
# print(add[0])
adds = add[0]
elif len(add) > 1:
# print(add)
adds = tuple(add)
# print(adds)
if len(fri) == 1:
# print(fri[0])
fris = fri[0]
elif len(fri) > 1:
# print(fri)
fris = tuple(fri)
# print(fris)
name = Node('病例',bingli_id = ids,trender = trenders,age = ages,
address = adds,friend = fris)
self.graph.create(name)
# 创建地址节点
for dates in self.perdir[names]['轨迹']:
for time in range(len(self.perdir[names]['轨迹'][dates])):
# print('action:', list(self.perdir[names]['轨迹'][dates][time])[2])
# print('adds:', list(self.perdir[names]['轨迹'][dates][time])[1])
# print(dates, self.perdir[names]['轨迹'][dates][time][0])
place = Node('外出地址',add_id=list(self.perdir[names]['轨迹'][dates][time])[1])
self.graph.create(place)
# 创建病例与轨迹之间的关系
# track = Relationship(names, self.perdir[names]['轨迹'][dates][time][2],
# self.perdir[names]['轨迹'][dates][time][1], date=dates, time=time)
# self.graph.create(track)
创建边的关系
def CreateRel(self):
for names in self.perdir:
# 创建病例与病例之间的联系
for rels in self.perdir[names]['属性']:
if type(self.perdir[names]['属性'][rels]) == list:
# print(rels, ':', self.perdir[names]['属性'][rels])
for index in self.perdir[names]['属性'][rels]:
# print(names,rels,index)
# 构建病例与病例之间的关系
try:
NamRel = Relationship(self.matcher.match('病例',bingli_id=names).first(),rels,
self.matcher.match('病例',bingli_id=index).first())
self.graph.create(NamRel)
except:
print(names+'构建联系出错'+index)
for dates in self.perdir[names]['轨迹']:
for time in range(len(self.perdir[names]['轨迹'][dates])):
print(list(self.perdir[names]['轨迹'][dates][time])[1])
# print(self.matcher.match('外出地址',add_id=list(self.perdir[names]['轨迹'][dates][time])[1]))
# print(self.perdir[names]['轨迹'][dates][times][2])
print(names,
list(self.perdir[names]['轨迹'][dates][time])[2],
list(self.perdir[names]['轨迹'][dates][time])[1],
dates,
list(self.perdir[names]['轨迹'][dates][time])[0]
)
times = list(self.perdir[names]['轨迹'][dates][time])[0]
track = Relationship(self.matcher.match('病例',bingli_id=names).first(),
list(self.perdir[names]['轨迹'][dates][time])[2],
self.matcher.match('外出地址',add_id=list(self.perdir[names]['轨迹'][dates][time])[1]).first(),
date = dates,time = times)
self.graph.create(track)
这部分代码也是进行在neo4j中构建图谱的核心代码。
三、进行数据分析
这部分内容不做过多的介绍,因为这是知识图谱创建完毕后,进行数据分析所要做的工作。
简单的给各位看一下在neo4j中的一个增删改查,当然这在python中也可以实现。

最后给大家展示一下最终的结果,当然截图没有办法截全,只给大家展示一部分。

这部分内容不做过多的介绍,因为这是知识图谱创建完毕后,进行数据分析所要做的工作。
备注:由于本人纯属爱好学习知识图谱,走过不少弯路。本实例是利用爬虫中的正则表达式进行数据的筛选,数据清理不够完善。如果能够利用哈工大的语义分割包进行分割附标签,效果会更好!
本人也非常渴望能向知识图谱业界的大神多多学习,也希望能够给刚刚入门知识图谱的朋友规避一些坑,能够更有效的提高能力。
希望可以和各位高人多多交流~
附本人邮箱:[email protected]
如果有人需要我的具体代码,或者入门知识图谱的过程,也欢迎各位与我联系
欢迎各位加我qq一起探讨哦(qq:630317316)
如果大家觉着我提供了一种思路,请大家随意打赏!~~