目标分类和目标检测学习笔记-理论篇
文章目录
- 一、目标分类篇
-
- **1.AlexNet**
-
-
- 网络结构
- 网络亮点
-
- **2.VGG**
-
-
- 网络结构
- 网络亮点
-
- **3.GoogLeNet**
-
-
- 网络结构
- 网络亮点
-
- **4.Resnet**
-
-
- 网络结构
- 网络亮点
- 为什么残差网络会work?
-
- 5.MobileNet
- 6.ShuffleNet
- 7.EfficientNet
- 8.Vision Transformer
- 二、目标检测篇
-
- 1.RCNN->Fast_RCNN->Faster_RCNN
-
-
- **RCNN**(mAP:53.7% of PASCAL VOC 2010)
-
- 算法流程
- Fast-RCNN(mAP:66% of PASCAL VOC 2012)
-
- 算法介绍
- 算法流程
- 算法重点内容
- Faster R-CNN (mAP:70.4% on PASCAL VOC 2012)
-
- 算法流程
- 算法重点内容
- 总结
-
- 2.SSD:Single Shot MultiBox Detector
-
-
-
- 网络结构
- 论文重点
-
-
- 3.YOLOv1->YOLOv2->YOLOv3->YOLOv3 SPP
-
-
- YOLOv1
-
- 论文思想
- 网络结构
- 损失函数
- YOLOv2
- YOLOv3 SPP
-
一、目标分类篇
1.AlexNet
网络结构
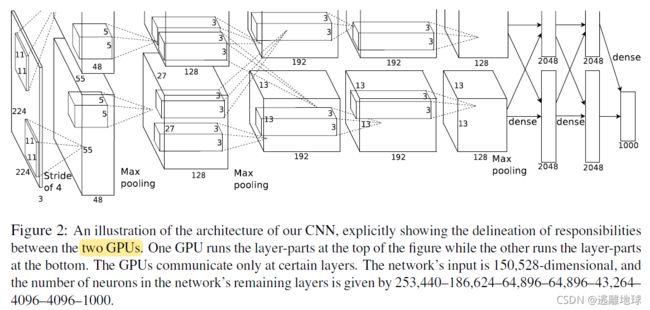
网络亮点
1.首次使用GPU加速网络训练
2.ReLU激活函数
关于Sigmod,ReLU,LeakyReLU激活函数的比较
3.使用LRN局部响应归一化

4.在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合

*Note:
经 过 卷 积 后 的 矩 阵 尺 寸 大 小 计 算 公 式 为 : N = W − F + 2 P S + 1 输 入 图 片 大 小 : W × W 卷 积 核 尺 寸 : F × F 步 长 s t r i d e : S p a d d i n g 值 : P 经过卷积后的矩阵尺寸大小计算公式为:\\ N=\frac{W-F+2P}{S}+1\\ 输入图片大小:W \times W \quad 卷积核尺寸:F \times F \quad 步长stride:\ S \quad padding值:P 经过卷积后的矩阵尺寸大小计算公式为:N=SW−F+2P+1输入图片大小:W×W卷积核尺寸:F×F步长stride: Spadding值:P
2.VGG
–VERY DEEP CONVOLUTIONAL NETWORKS–
网络结构

网络亮点
-
通过堆叠多个3x3的卷积核来替代大尺度卷积核 (减少所需参数)
可以通过堆叠两个3x3的卷积核替代5x5的卷积核,堆叠三个3x3的卷积核替代7x7的卷积核,它们拥有相同的感受野(receptive field).。
感 受 野 计 算 公 式 : F ( i ) = ( F ( i + 1 ) − 1 ) × S t r i d e + K s i z e 感受野计算公式:F(i)=(F(i+1)-1)\times Stride+Ksize 感受野计算公式:F(i)=(F(i+1)−1)×Stride+Ksize

2.通过堆叠3x3的卷积核减少了模型参数

3.LRN对模型效果没有改善

3.GoogLeNet
网络结构

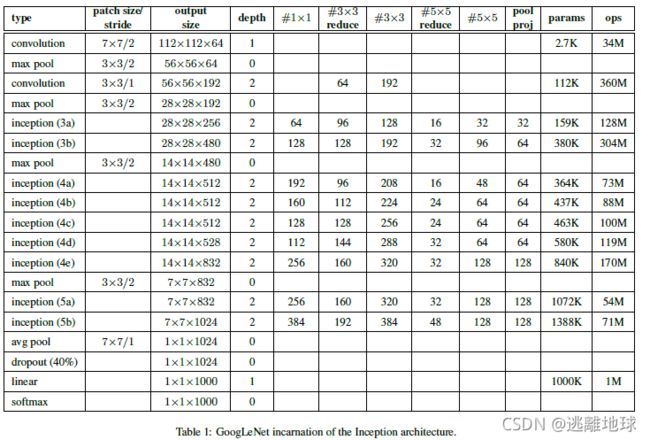
网络亮点
1.引入了Inception结构(融合不同尺度的特征信息)

2.使用1x1的卷积核进行降维以及映射处理

3.添加两个辅助分类器帮助训练

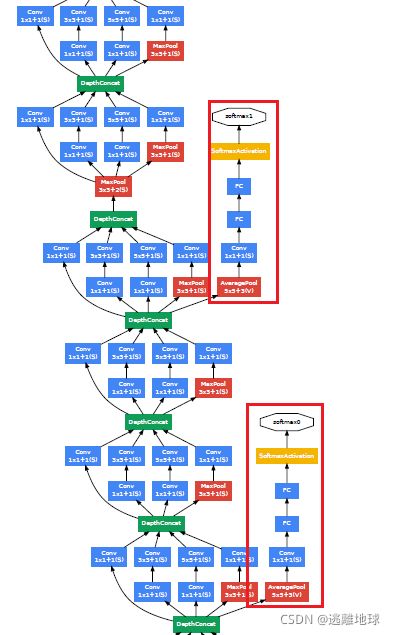
4.丢弃全连接层,使用平均池化层(大大减少模型参数)
4.Resnet
**Question:**Is learning better networks as easy as stacking more layers?

Anwser:如图 所示,在训练集上,传统神经网络越深效果不一定越好。而 Deep Residual Learning for Image Recognition 这篇论文认为,理论上,可以训练一个 shallower 网络,然后在这个训练好的 shallower 网络上堆几层 identity mapping(恒等映射) 的层,即输出等于输入的层,构建出一个 deeper 网络。这两个网络(shallower 和 deeper)得到的结果应该是一模一样的,因为堆上去的层都是 identity mapping。这样可以得出一个结论:理论上,在训练集上,Deeper 不应该比 shallower 差,即越深的网络不会比浅层的网络效果差。但为什么会出现图 中 这样的情况呢,随着层数的增多,训练集上的效果变差?这被称为退化问题(degradation problem),原因是随着网络越来越深,训练变得原来越难,网络的优化变得越来越难。理论上,越深的网络,效果应该更好;但实际上,由于训练难度,过深的网络会产生退化问题,效果反而不如相对较浅的网络。而残差网络就可以解决这个问题的,残差网络越深,训练集上的效果会越好。(测试集上的效果可能涉及过拟合问题。过拟合问题指的是测试集上的效果和训练集上的效果之间有差距。)
网络结构
文中对比了VGG19、34-layer plain(没有residue模块)、34-layer residual模型

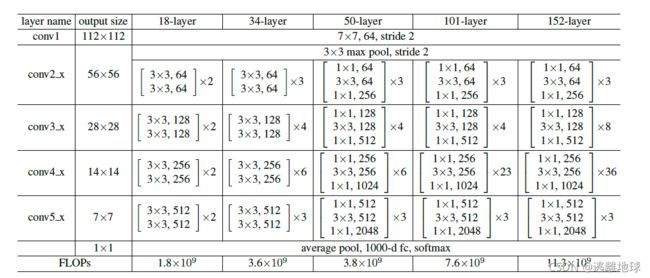
网络亮点
1.超深的网络结构
->梯度消失或梯度爆炸问题
->退化问题Degration Problem:

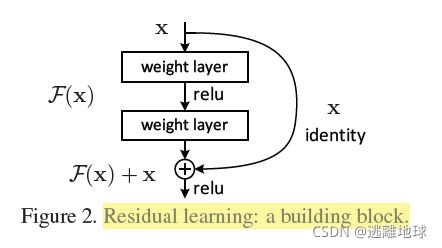
2.提出residual模块

3.Batch Normalization
目的:使一批feature map满足均值为0,方差为1的分布规律
Input: V a l u e s o f x o v e r a m i n i − b a t c h : B = { x 1... m } ; P a r a m e t e r s t o b e l e a r n e d : γ , β Output: { y i = B N γ , β ( x i ) } μ B ← 1 m ∑ i = 1 m x m / / m i n i − b a t c h m e a n σ B 2 ← 1 m ∑ i = 1 m ( x i − μ B ) 2 / / m i n i − b a t c h v a r i a n c e x i ^ ← x i − μ B σ B 2 + ϵ / / n o r m a l i z e y i ← γ x i ^ + β ≡ B N γ , β ( x i ) / / s c a l e a n d s h i f t \textbf{Input:}Values\ of\ x\ over\ a\ mini-batch:B=\{ x_{1...m}\}; \\Parameters\ to\ be\ learned:\gamma,\beta\\ \textbf{Output:}\{y_i=BN_{\gamma,\beta}(x_i)\}\\ \mu_B \leftarrow \frac {1}{m} \sum_{i=1}^m x_m \qquad //mini-batch\ mean\\ \sigma_B^2 \leftarrow \frac{1}{m} \sum_{i=1}^m(x_i-\mu_B)^2 \qquad //mini-batch\ variance\\ \hat{x_i} \leftarrow \frac {x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} \qquad //normalize \\ y_i \leftarrow \gamma \hat{x_i}+\beta \equiv BN_{\gamma,\beta}(x_i) \qquad //scale\ and\ shift Input:Values of x over a mini−batch:B={x1...m};Parameters to be learned:γ,βOutput:{yi=BNγ,β(xi)}μB←m1i=1∑mxm//mini−batch meanσB2←m1i=1∑m(xi−μB)2//mini−batch variancexi^←σB2+ϵxi−μB//normalizeyi←γxi^+β≡BNγ,β(xi)//scale and shift
为什么残差网络会work?
我们给一个网络不论在中间还是末尾加上一个残差块,并给残差块中的 weights 加上 L2 regularization(weight decay),这样F(x)=0 是很容易的。这种情况下加上一个残差块和不加之前的效果会是一样,所以加上残差块不会使得效果变得差。如果残差块中的隐藏单元学到了一些有用信息,那么它可能比 identity mapping(即 F(x)=0)表现的更好。
*Note:–迁移学习–
优势:
- 能够快速的训练出一个理想的结果
- 当数据集较小时也能训练出理想的效果
常见的迁移学习方式
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层、仅训练最后一个全连接层
5.MobileNet
6.ShuffleNet
7.EfficientNet
8.Vision Transformer
二、目标检测篇
1.RCNN->Fast_RCNN->Faster_RCNN
RCNN(mAP:53.7% of PASCAL VOC 2010)
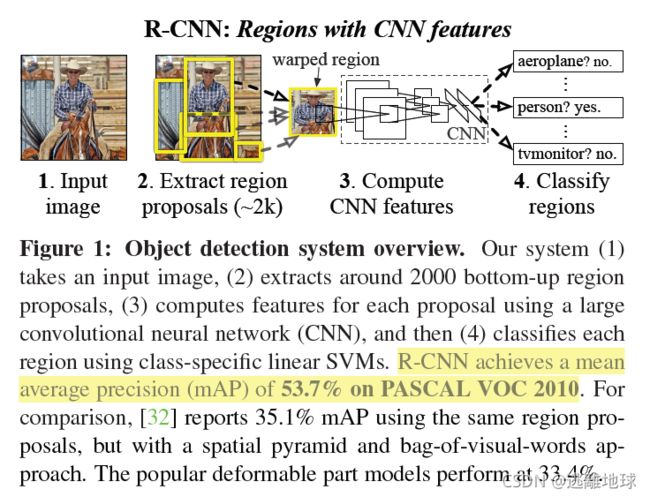
算法流程
-
一张图像生成1000~2000个候选区域(Proposals),采用Selective Search方法
-
对每个候选区域,使用深度网络提取特征
-
特征送入每一类的SVM分类器,判别是否属于该类
将2000×4096的特征矩阵与20个SVM组成的权值矩阵4096×20
相乘,获得2000×20的概率矩阵,每一行代表一个建议框归于每个
目标类别的概率。分别对上述2000×20维矩阵中每一列即每一类进
行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一
些建议框。

-
使用回归器精细修正候选框位置
Fast-RCNN(mAP:66% of PASCAL VOC 2012)
算法介绍
论文指出了R-CNN存在的问题
- Training is a multi-stage pipeline
- Training is expensive in space and time.
- Object detection is slow
测试速度慢:测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大量重叠,提取特征操作冗余;训练速度慢;训练所需空间大。
Fast_RCNN的主要贡献:
- Higher detection quality (mAP) than R-CNN, SPPnet
- Training is single-stage, using a multi-task loss
- Training can update all network layers
- No disk storage is required for feature caching
算法流程

- 一张图像生成1000~2000个候选区域(使用Selective Search方法)
- 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到
特征图上获得相应的特征矩阵 - 将每个特征矩阵通过ROI Pooling层缩放到7x7大小的特征图,接着将
特征图展平通过一系列全连接层得到预测结果
算法重点内容
-
一次性计算整张图像特征

-
训练数据的采样(计算Loss时正、负样本选取)

-
损失函数 Multi-task loss
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) p 是 分 类 器 预 测 的 s o f t m a x 概 率 分 布 p = { p 0 , . . . , p k } u 对 应 目 标 真 实 类 别 标 签 分 类 损 失 : L c l s ( p , u ) = − l o g p u 边 界 框 回 归 损 失 : L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) s m o o t h L 1 ( x ) = { 0.5 x 2 i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 o t h e r w i s e L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\ge1]L_{loc}(t^u,v) \\p是分类器预测的softmax概率分布p=\{p_0,...,p_k\} \\u对应目标真实类别标签 \\分类损失:L_{cls}(p,u)=-log\ p_u \\边界框回归损失:L_{loc}(t^u,v)=\sum_{i\in \{x,y,w,h \}}smooth_{L_1}(t_i^u-v_i) \\ smooth_{L_1}(x)= \left\{ \begin{array}{lr} 0.5x^2 \qquad if |x|<1\\ |x|-0.5 \qquad otherwise \end{array} \right. L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)p是分类器预测的softmax概率分布p={p0,...,pk}u对应目标真实类别标签分类损失:Lcls(p,u)=−log pu边界框回归损失:Lloc(tu,v)=i∈{x,y,w,h}∑smoothL1(tiu−vi)smoothL1(x)={0.5x2if∣x∣<1∣x∣−0.5otherwise
Faster R-CNN (mAP:70.4% on PASCAL VOC 2012)
算法流程

- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到
特征图上获得相应的特征矩阵 - 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图
接着将特征图展平通过一系列全连接层得到预测结果
算法重点内容
- RPN(Region Proposal Networks),anchor box


对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
-
正负样本选取


-
RPN损失函数
L ( p i , t i ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) p i 表 示 第 i 个 a n c h o r 预 测 为 真 实 标 签 的 概 率 p i ∗ 当 为 正 样 本 时 为 , 当 为 负 样 本 时 为 0 t i 表 示 预 测 第 i 个 a n c h o r 的 边 界 框 回 归 参 数 t i ∗ 表 示 第 i 个 a n c h o r 对 应 的 G T B o x 的 边 界 回 归 参 数 N c l s 表 示 一 个 m i n i − b a t c h 中 的 样 本 数 量 256 N r e g 表 示 a n c h o r 位 置 的 个 数 , 约 2400 L({p_i},{t_i})=\frac {1}{N_{cls}}\sum_i L_{cls}(p_i,p_i^*)+\lambda \frac {1}{N_{reg}}\sum_i p_i^* L_{reg}(t_i,t_i^*) \\p_i表示第i个anchor预测为真实标签的概率 \\p_i^*当为正样本时为,当为负样本时为0 \\t_i表示预测第i个anchor的边界框回归参数 \\t_i^*表示第i个anchor对应的GTBox的边界回归参数 \\N_{cls}表示一个mini-batch中的样本数量256 \\N_{reg}表示anchor位置的个数,约2400 L(pi,ti)=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)pi表示第i个anchor预测为真实标签的概率pi∗当为正样本时为,当为负样本时为0ti表示预测第i个anchor的边界框回归参数ti∗表示第i个anchor对应的GTBox的边界回归参数Ncls表示一个mini−batch中的样本数量256Nreg表示anchor位置的个数,约2400
- Fast R-CNN Multi-task loss 同(Fast R-CNN部分)
L ( p , u , t u , v ) = L c l s ( p , u ) + λ [ u ≥ 1 ] L l o c ( t u , v ) p 是 分 类 器 预 测 的 s o f t m a x 概 率 分 布 p = { p 0 , . . . , p k } u 对 应 目 标 真 实 类 别 标 签 L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\ge1]L_{loc}(t^u,v) \\p是分类器预测的softmax概率分布p=\{p_0,...,p_k\} \\u对应目标真实类别标签 L(p,u,tu,v)=Lcls(p,u)+λ[u≥1]Lloc(tu,v)p是分类器预测的softmax概率分布p={p0,...,pk}u对应目标真实类别标签
总结
Two_stages典型框架

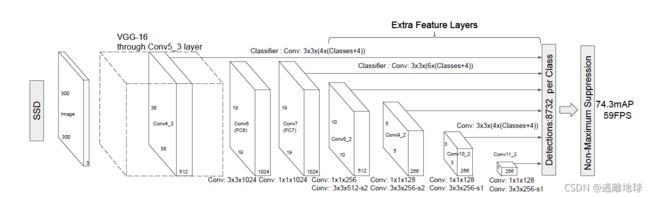
2.SSD:Single Shot MultiBox Detector
简介:SSD网络是作者Wei Liu在ECCV 2016上发表的论文。对于输入尺寸300x300的网络使用Nvidia Titan X在VOC 2007测试集上达到74.3%mAP以及59FPS,对于512x512的网络,达到了76.9%mAP超越当时最强的Faster RCNN(73.2%mAP)。真正的实时
网络结构

Faster RCNN存在的问题
- 对小目标检测效果很差
- 模型大,检测速度较慢
论文重点
-
One_stage

-
在不同特征尺度上预测不同尺度的目标
-
Default Box 的scale以及aspect设定

-
Predictor的实现



-
正负样本的选取


- 损失计算
L ( x , c , l , g ) = 1 N ( L c o n f ( x , c ) ) + α L l o c ( x , l , g ) 其 中 N 为 匹 配 到 的 正 样 本 个 数 类 别 损 失 : L c o n f ( x , c ) = − ∑ i ∈ P o s N x i j p l o g ( c i p ^ ) − ∑ i ∈ N e g l o g ( c i 0 ^ ) w h e r e c i p ^ = e x p ( c i p ) ∑ p e x p ( c i p ) c i p ^ 为 预 测 的 第 i 个 d e f a u l t b o x 对 应 的 G T B o x ( 类 别 是 P ) 的 类 别 概 率 x i j p = 0 , 1 为 第 i 个 d e f a u l t b o x 匹 配 到 的 第 j 个 G T B o x ( 类 别 是 P ) L(x,c,l,g)=\frac {1}{N}(L_{conf}(x,c))+\alpha L_{loc}(x,l,g) \\其中N为匹配到的正样本个数\\ \\类别损失:L_{conf}(x,c)=-\sum_{i \in Pos}^Nx_{ij}^p log(\hat{c_i^p})-\sum_{i \in Neg}log(\hat{c_i^0}) \quad where \quad \hat{c_i^p}=\frac {exp(c_i^p)}{\sum_p exp(c_i^p)} \\ \hat{c_i^p}为预测的第i个default\ box对应的GTBox(类别是P)的类别概率 \\ x_{ij}^p={0,1}为第i个default\ box匹配到的第j个GTBox(类别是P) L(x,c,l,g)=N1(Lconf(x,c))+αLloc(x,l,g)其中N为匹配到的正样本个数类别损失:Lconf(x,c)=−i∈Pos∑Nxijplog(cip^)−i∈Neg∑log(ci0^)wherecip^=∑pexp(cip)exp(cip)cip^为预测的第i个default box对应的GTBox(类别是P)的类别概率xijp=0,1为第i个default box匹配到的第j个GTBox(类别是P)

3.YOLOv1->YOLOv2->YOLOv3->YOLOv3 SPP
YOLOv1
表现:mAP:63.4% 45FPS 448x448
论文思想
-
将一幅图像分成SxS个网格(grid cell),如果某个object的中心落在这个网格中,则这个网格就负责预测这个object

-
每个网格要预测B个bounding box,每个bounding box除了要预测位置之外,还要附带预测一个confidence值。每个网格还要预测C个类别的分数

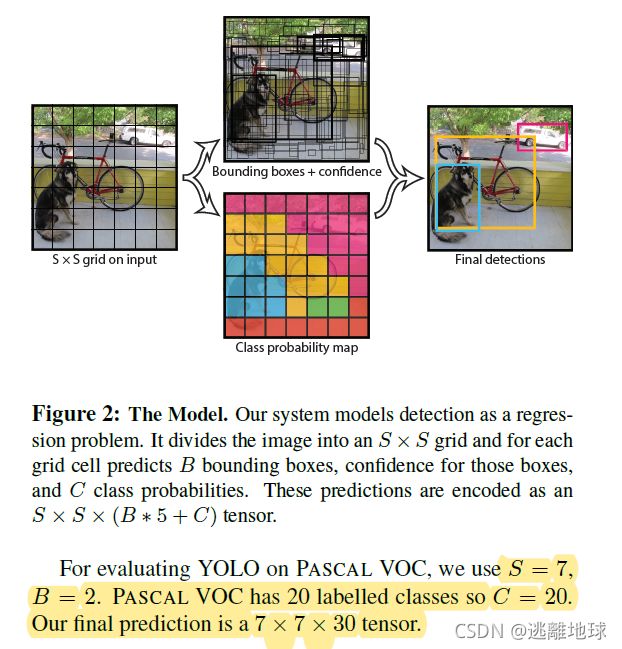
网络结构
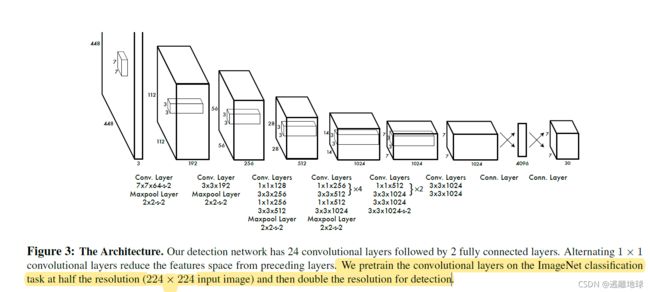
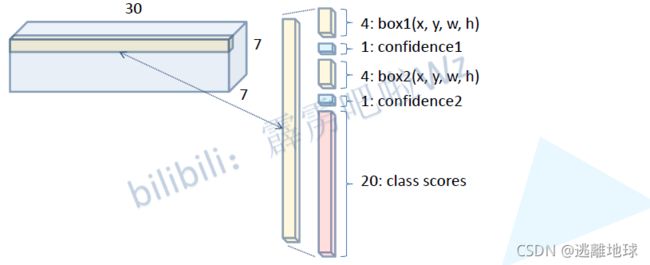
损失函数

YOLOv2
YOLOv2的尝试:
-
Batch Normalization
-
High Resolution Classifier
-
Convolutional With Anchor Boxes

-
Dimension Clusters聚类
-
Direct location prediction
-
Fine-Grained Features
引入passthrough layer,将低层的feature与高层的进行拼接
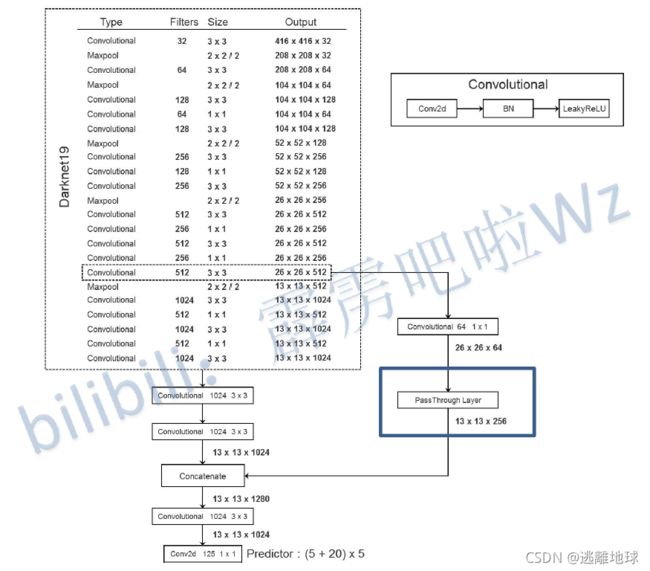
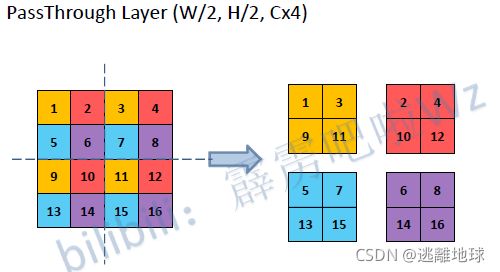
-
Multi-Scale Training
每经过10个batches网络会随机选择新的图像输入尺寸,增加了网络在处理不同尺寸大小图片时的鲁棒性。

YOLOv3 SPP
-
Mosaic图像增强
-
SPP模块
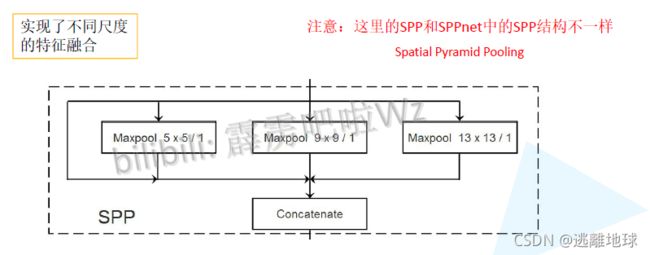
-
CIOU Loss
GIoU、DIoU、CIoU
一个优秀的回归定位损失应该考虑到3种几何参数:
重叠面积 中心点距离 长宽比
C I o U = I o U − ( ρ 2 ( b , b g t ) c 2 + α v ) v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 α = v ( 1 − I o U ) + v L C I o U = 1 − C I o U C I o U=I o U-\left(\frac{\rho^{2}\left(b, b^{g t}\right)}{c^{2}}+\alpha v\right) \\v=\frac{4}{\pi^{2}}\left(\arctan \frac{w^{g t}}{h^{gt} }-\arctan \frac{w}{h}\right)^{2} \\\alpha=\frac{v}{(1-I o U)+v} \\L_{CIoU}=1-CIoU CIoU=IoU−(c2ρ2(b,bgt)+αv)v=π24(arctanhgtwgt−arctanhw)2α=(1−IoU)+vvLCIoU=1−CIoU -
Focal Loss
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重
二 分 类 交 叉 熵 损 失 : C E ( p , y ) = { − log ( p ) if y = 1 − log ( 1 − p ) otherwise 为 了 方 便 , 用 p t 表 示 样 本 为 t r u e c l a s s 的 概 率 则 p t = { p if y = 1 1 − p otherwise C E ( p , y ) = C E ( p t ) = − log ( p t ) 引 入 调 制 系 数 ( 1 − p t ) γ F L ( p t ) = − ( 1 − p t ) γ log ( p t ) 二分类交叉熵损失:\mathrm{CE}(p, y)=\left\{\begin{array}{ll} -\log (p) & \text { if } y=1 \\ -\log (1-p) & \text { otherwise } \end{array}\right. \\为了方便,用p_t表示样本为true\ class的概率 \\则p_{\mathrm{t}}=\left\{\begin{array}{ll} p & \text { if } y=1 \\ 1-p & \text { otherwise } \end{array}\right. \\\mathrm{CE}(p, y)=\mathrm{CE}\left(p_{\mathrm{t}}\right)=-\log \left(p_{\mathrm{t}}\right) \\ 引入调制系数(1-p_t)^{\gamma} \qquad \mathrm{FL}\left(p_{\mathrm{t}}\right)=-\left(1-p_{\mathrm{t}}\right)^{\gamma} \log \left(p_{\mathrm{t}}\right) 二分类交叉熵损失:CE(p,y)={−log(p)−log(1−p) if y=1 otherwise 为了方便,用pt表示样本为true class的概率则pt={p1−p if y=1 otherwise CE(p,y)=CE(pt)=−log(pt)引入调制系数(1−pt)γFL(pt)=−(1−pt)γlog(pt)
两个重要性质:- 当一个样本被分错的时候,pt是很小的,那么调制因子(1-Pt)接近1,损失不被影响;当Pt→1,因子(1-Pt)接近0,那么分的比较好的(well-classified)样本的权值就被调低了。因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小
- 当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多