Efficient GlobalPointer:少点参数,多点效果

©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在《GlobalPointer:用统一的方式处理嵌套和非嵌套 NER》中,我们提出了名为“GlobalPointer”的 token-pair 识别模块,当它用于 NER 时,能统一处理嵌套和非嵌套任务,并在非嵌套场景有着比 CRF 更快的速度和不逊色于 CRF 的效果。换言之,就目前的实验结果来看,至少在 NER 场景,我们可以放心地将 CRF 替换为 GlobalPointer,而不用担心效果和速度上的损失。
在这篇文章中,我们提出 GlobalPointer 的一个改进版——Efficient GlobalPointer,它主要针对原 GlobalPointer 参数利用率不高的问题进行改进,明显降低了 GlobalPointer 的参数量。更有趣的是,多个任务的实验结果显示,参数量更少的 Efficient GlobalPointer 反而还取得更好的效果。

大量的参数
这里简单回顾一下 GlobalPointer,详细介绍则请读者阅读《GlobalPointer:用统一的方式处理嵌套和非嵌套 NER》。简单来说,GlobalPointer 是基于内积的 token-pair 识别模块,它可以用于 NER 场景,因为对于 NER 来说我们只需要把每一类实体的“(首, 尾)”这样的 token-pair 识别出来就行了。
设长度为 的输入 经过编码后得到向量序列 ,原始 GlobalPointer 通过变换 和 我们得到序列向量序列 和 ,然后定义

作为从 到 的连续片段是一个类型为 的实体的打分。这里我们暂时省略了偏置项,如果觉得有必要,自行加上就好。
这样一来,有多少种类型的实体,就有多少个 和 。不妨设 ,那么每新增一种实体类型,我们就要新增 个参数;而如果用 CRF+BIO 标注的话,每新增一种实体类型,我们只需要增加 的参数(转移矩阵参数较少,忽略不计)。对于 BERT base 来说,常见的选择是 ,可见 GlobalPointer 的参数量远远大于 CRF。

识别与分类
事实上,不难想象对于任意类型 ,其打分矩阵 必然有很多相似之处,因为对于大多数 token-pair 而言,它们代表的都是“非实体”,这些非实体的正确打分都是负的。这也就意味着,我们没必要为每种实体类型都设计独立的 ,它们应当包含更多的共性。
怎么突出 的共性呢?以 NER 为例,我们知道 NER 实际上可以分解为“抽取”和“分类”两个步骤,“抽取”就是抽取出为实体的片段,“分类”则是确定每个实体的类型。这样一来,“抽取”这一步相当于只有一种实体类型的 NER,我们可以用一个打分矩阵就可以完成,即 ,而“分类”这一步,我们则可以用“特征拼接+ Dense 层”来完成,即 。于是我们可以将两项组合起来,作为新的打分函数:
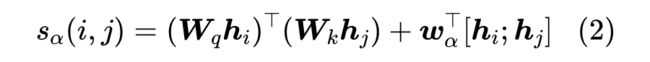
这样一来,“抽取”这部分的参数对所有实体类型都是共享的,因此每新增一种实体类型,我们只需要新增对应的 就行了,即新增一种实体类型增加的参数量也只是 。进一步地,我们记 ,然后为了进一步地减少参数量,我们可以用 来代替 ,此时
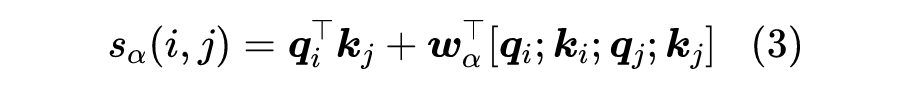
此时 ,因此每新增一种实体类型所增加的参数量为 ,由于通常 ,所以式(3)的参数量往往少于式(2),它就是 Efficient GlobalPointer 最终所用的打分函数。

惊喜的实验
Efficient GlobalPointer 已经内置在 bert4keras>=0.10.9 中,读者只需要更改一行代码,就可以切换 Efficient GlobalPointer 了。
1# from bert4keras.layers import GlobalPointer
2from bert4keras.layers import EfficientGlobalPointer as GlobalPointer下面我们来对比一下 GlobalPointer 和 Efficient GlobalPointer 的结果:
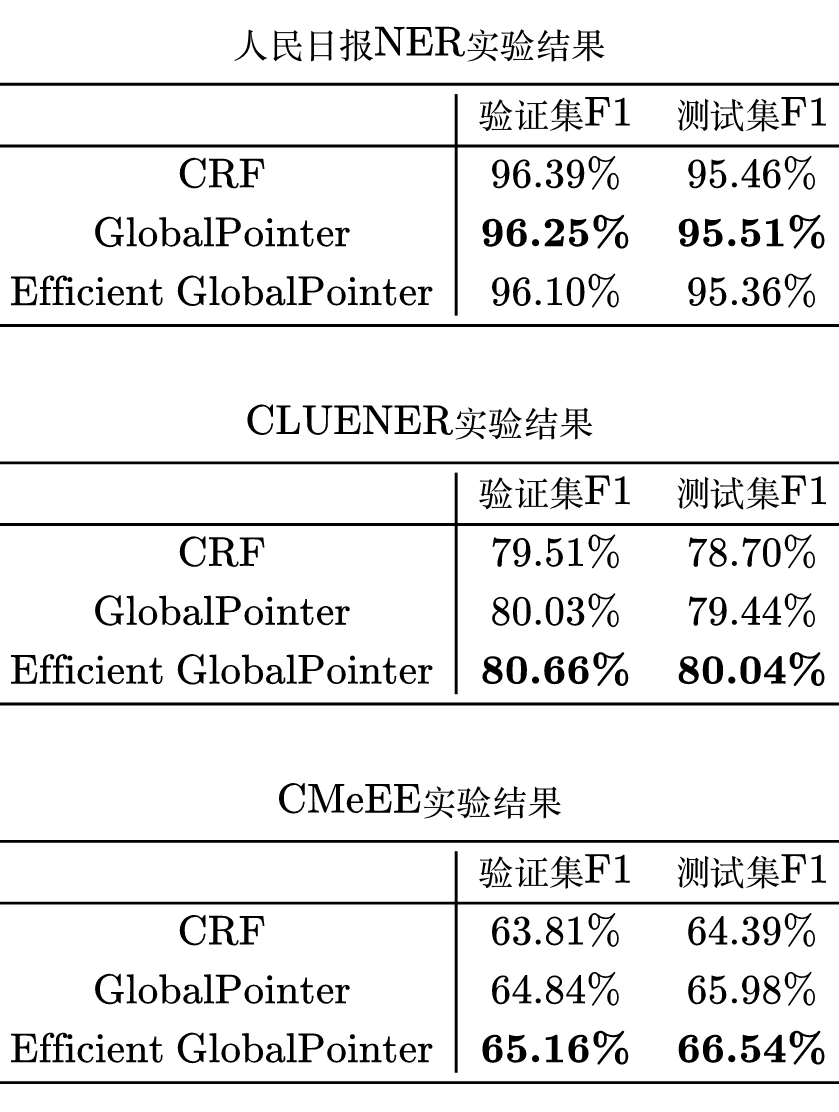
可以看到,Efficient GlobalPointer 的实验结果还是很不错的,除了在人民日报任务上有轻微下降外,其他两个任务都获得了一定提升,并且整体而言提升的幅度大于下降的幅度,所以 Efficient GlobalPointer 不单单是节省了参数量,还提升了效果。而在速度上,Efficient GlobalPointer 与原始的 GlobalPointer 几乎没有差别。

分析与评述
考虑到人民日报 NER 只有 3 种实体类型,CLUENER 和 CMeEE 分别有 10 种和 9 种实体类型,从分数来看也是人民日报比其他两种要高,这说明 CLUENER 和 CMeEE 的难度更大。另一方面,在 CLUENER 和 CMeEE 上 Efficient GlobalPointer 都取得了提升,所以我们可以初步推断:实体类别越多、任务越难时,Efficient GlobalPointer 越有效。
这也不难理解,原版 GlobalPointer 参数过大,那么平均起来每个参数更新越稀疏,相对来说也越容易过拟合;而 Efficient GlobalPointer 共享了“抽取”这一部分参数,仅通过“分类”参数区分不同的实体类型,那么实体抽取这一步的学习就会比较充分,而实体分类这一步由于参数比较少,学起来也比较容易。反过来,Efficient GlobalPointer 的实验效果好也间接证明了式(3)的分解是合理的。
当然,不排除在训练数据足够多的时候,原版 GlobalPointer 会取得更好的效果。但即便如此,在类别数目较多时,原版 GlobalPointer 可能会占用较多显存以至于难以使用,还是以 base 版 为例,如果类别数有 100 个,那么原版 GlobalPointer 的参数量为 ,接近千万,不得不说确实是不够友好了。

最后的总结
本文指出了原版 GlobalPointer 的参数利用率不高问题,并提出了相应的改进版 Efficient GlobalPointer。实验结果显示,Efficient GlobalPointer 在降低参数量的同时,基本不会损失性能,甚至还可能获得提升。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
