通俗地讲讲数据降维的原理
什么是数据降维?关于这个问题,很多专家的说法都非常学术,估计很多普通人听不懂。所以,这里用通俗的语言解释一下,希望有助于更多的入门新人理解。
举一个简单的例子:假设一个小学的班级有5个学生,每个人有2们考试成绩,语文和数学。A同学的语文是100分,数学是100分;B同学的语文是90分,数学是100分;C同学的语文是80分,数学是100分;D同学的语文是70分,数学是100分;E同学的语文是60分,数学是100分。
对这个场景,我们要注意到,每位同学的数学成绩都是一样的,都是100分。
这时,如果我们提到“语文是80分,数学是100分的那个同学”,你一定知道我们指的一定是同学C。
但是,如果我们只说“语文是80分的那个同学”,你是不是也知道我们指的一定是同学C!
这就是一个将二维数据降维到一维数据的例子,因为大家的数学都是100分,所以每个同学的数学数据对区分同学之间的差异没有任何价值,仅仅使用语文数据(即一维数据)就足够了,而且用来区分同学100%够用。
所以,做数据分析时,常说的,如果一个维度的数据在各个样本之间的差异很小(用专业的话说就是方差很小)的话,这个数据维度就越没有价值。只有在各个样本之间的差异很大的数据维度(用专业的话说就是方差很大的维度),才值得保留。
这是一个非常浅显易懂的例子。稍微加入一些专业的表述,我们可以用一个二维坐标系来表示这5位同学,x轴代表语文的分数,y轴代表数学的分数,他们的坐标分别是:A(100,100), B(90,100), C(80,100), D(70,100), E(60,100)。
你看到了什么?没错,它们都位于y=100这条直线上,所不同的是x坐标值。
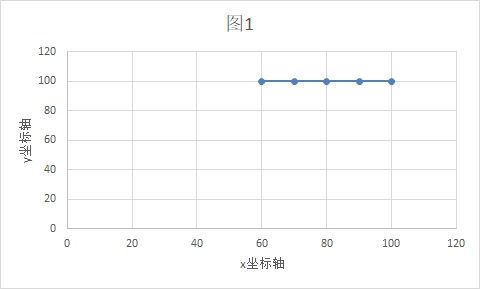
因此,在这个场景下,我们完全可以将一个含x轴和y轴的二维坐标系,转换为一个只含有x轴的一维坐标系。
懂了上面的道理,你就理解了降维的原理。
在上面的场景中,我们看到,语文分数和数学分数完全无关,因为无论语文分数多少,数学都是100分。用专业的语言讲,就是这两个特征是正交的(即相关系数为0)。因为是正交,我们很容易对这个场景进行处理,那就是直接在二维坐标系中删掉y轴,只保留x轴就够了。
在现实中,场景可就没这么简单了。通常,2个变量会有一定的相关度。即便是不相关,也不会像上面那个场景那么容易看出来。比如下面举个例子。
另一个班,还是5位同学,语文分数和数学分数转换为坐标分别是:A(100,60), B(90,70), C(80,80), D(70,90), E(60,100)。
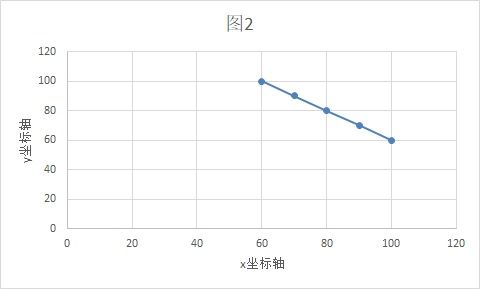
你可能觉得,这是一个完全负相关的数据啊!没错,不过,这只是一个从当前坐标系看到的现象。
实际上,从数据降维的角度讲,我们可以将x轴和y轴的两个直角坐标轴,同时绕着原点顺时针旋转45%,这时你看到的是下面的图像。
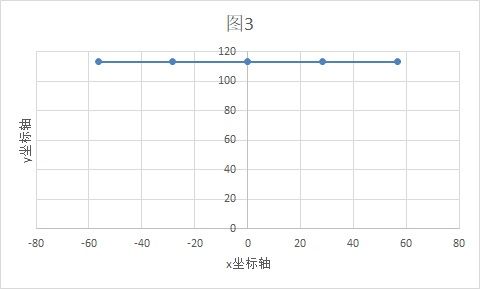
没错,坐标轴旋转后,这个场景变成了第一个班级的场景,大家的y坐标都是 80*根号2,不同的只是x坐标值。至于坐标轴的转换公式,这里就细说,在我上一篇的文章中提到过。
其实,这就是数据降维的最基本道理,无论是用于数据降维的主成分分析技术还是因子分析技术,都是这个逻辑,只是场景不再是这么简单的小学生,而是维度更多的大数据了。
复杂的模型,背后往往都是最朴素的思考方法,希望这几个例子能让新人们理解到底数据降维是怎么回事。
(An Actuary)