RNN,LSTM,GRU解析
1. RNN
1.1 RNN的结构

对于每一个时间步 t t t而言
- a < t > = g ( W a a a < t − 1 > + W a x x < t > + b a ) a^{
}=g(W_{aa}a^{ a<t>=g(Waaa<t−1>+Waxx<t>+ba)}+W_{ax}x^{ }+b_a) - y < t > = W y a a < t > + b y y^{
}=W_{ya}a^{ y<t>=Wyaa<t>+by}+b_y
其中 W a a , W a x , W y a , b a , b y W_{aa},W_{ax},W_{ya},b_a,b_y Waa,Wax,Wya,ba,by是每个循环单元共享的参数, g g g是激活函数 T a n h Tanh Tanh
1.2 RNN的种类
-
一对一
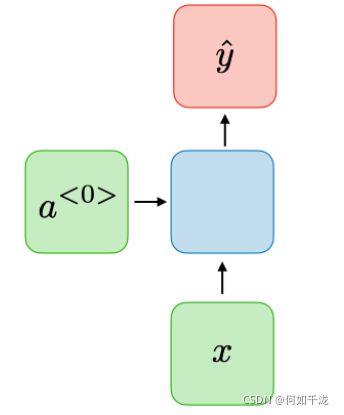
-
一对多

-
多对一

-
多对多(输入序列和输出序列长度相等)
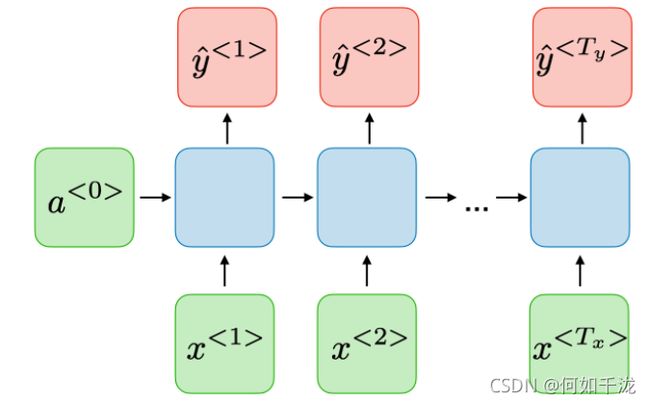
-
多对多(输入序列和输出序列长度不相等)

1.3 RNN的优缺点
- 优点
- 可以处理任何长度的输出
- 模型大小不随输入大小增加而增大
- 计算考虑了历史信息
- 权重是跨时间步共享的
- 缺点
- 计算缓慢
- 很难访问很久之前的信息
- 不能考虑当前时间步后的未来信息
1.4 RNN参数详解torch.nn.RNN

- 参数
input_size:输入序列x的特征长度hidden_size:隐藏层的特征长度num_layers:rnn层的数目。如果将其设置为2,将意味着将两个 RNN 堆叠在一起形成一个堆叠的 RNN,第二个 RNN 接收第一个 RNN 的输出并计算最终结果。默认值为1nonlinearity:非线性层,默认为tanhbias:是否使用bias,默认为Truebatch_first:如果为True,则输入和输出的tensor形状必须提供成(batch, seq, feature)而不是(seq,batch,feature),默认为Falsedropout:在除最后一层之外的每个 RNN 层的输出上引入一个 Dropout 层,dropout概率等于dropout。默认为0bidirectional:如果为True,则为双向RNN,默认为False
- 输入
input:当batch_first为False时,形状为(seq_len, batch_size, input_size),否则为(batch_size, seq_len,input_size)h_0:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 输出
output:当batch_first为False时,形状为(seq_len, batch_size,D*hidden_size),否则为(batch_size, seq_len,D*hidden_size)。其中D=2 if bidirectional==True else 1h_n:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 例子解析
import torch import torch.nn as nn rnn = nn.RNN(10, 20, 2) input = torch.randn(5, 3, 10) h_0 = torch.randn(2, 3, 20) output, h_n = rnn(input, h_0) output.shape Out[1]: torch.Size([5, 3, 20]) h_n.shape Out[2]: torch.Size([2, 3, 20])
2. LSTM
2.1 LSTM的结构
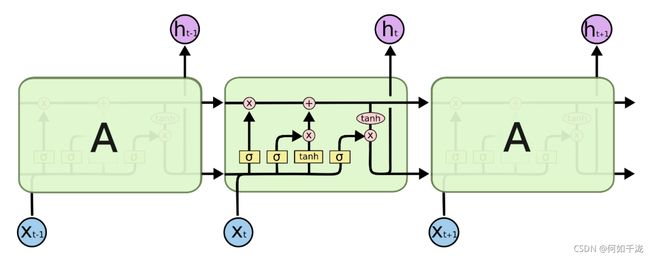
其中
- σ \sigma σ:
sigmoid gate layer(其输出是一个0-1的数,用来控制信息输出。0代表不让任何信息通过、1代表让任何信息通过) - x t x_t xt:输入
- h t h_t ht:输出
2.1.1 forget gate layer

- f t ∈ [ 0 , 1 ] f_t \in [0, 1] ft∈[0,1]:用来控制忘记多少历史信息
2.1.2 input gate layer
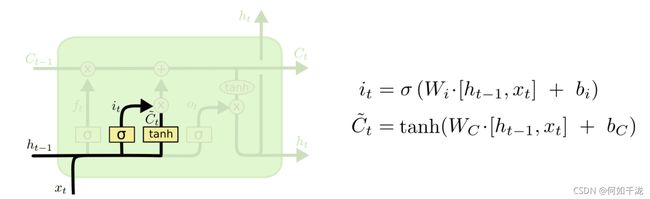
- C t ~ \widetilde{C_t} Ct :当前状态临时信息
- i t ∈ [ 0 , 1 ] i_t \in [0, 1] it∈[0,1]:用来控制保留多少历史信息
2.1.3 当前状态实际信息
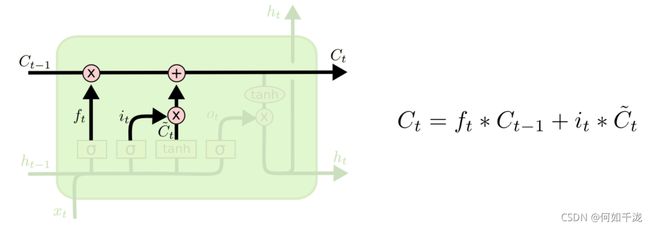
- f t f_t ft:控制让多少历史信息通过
- C t − 1 C_{t-1} Ct−1:历史信息
- i t i_t it:控制让多少当前信息通过
- C t ~ \widetilde{C_t} Ct :当前信息
2.1.4 output gate layer
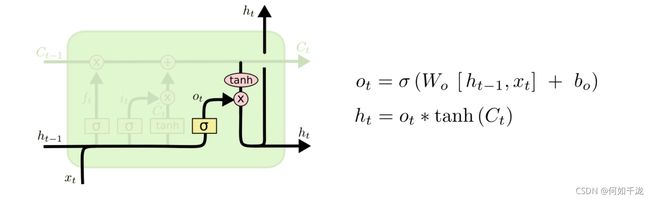
- o t o_t ot:控制最后输出多少信息
- h t h_t ht:输出
2.2 LSTM的种类
同RNN一样,只不过将RNN cell换成LSTM cell
2.3 LSTM的优缺点
- 优点
- 其结构类似于ResNet, 消除了一些梯度消失/爆炸的问题
- 缺点:
- 计算费时,每个cell有4个全连接层
2.4 LSTM参数解析torch.nn.LSTM

- 参数
input_size:输入序列x的特征长度hidden_size:隐藏层的特征长度num_layers:rnn层的数目。如果将其设置为2,将意味着将两个 RNN 堆叠在一起形成一个堆叠的 RNN,第二个 RNN 接收第一个 RNN 的输出并计算最终结果。默认值为1bias:是否使用bias,默认为Truebatch_first:如果为True,则输入和输出的tensor形状必须提供成(batch, seq, feature)而不是(seq,batch,feature),默认为Falsedropout:在除最后一层之外的每个 RNN 层的输出上引入一个 Dropout 层,dropout概率等于dropout。默认为0bidirectional:如果为True,则为双向RNN,默认为Falseproj_size:如果大于0,将使用具有相应大小投影的 LSTM(简单来说就是在原有基础上的输出层后增加个全连接层,使其投影到指定大小。即 h t = W h r h t h_t=W_{hr}h_t ht=Whrht)。默认为0
- 输入
input:当batch_first为False时,形状为(seq_len, batch_size, input_size),否则为(batch_size, seq_len,input_size)h_0:形状为(D*num_layer, batch_size, output_size)。其中D=2 if bidirectional==True else 1,output_size=proj_size if proj_size>0 else hidden_sizec_0:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 输出
output:当batch_first为False时,形状为(seq_len, batch_size,D*hidden_size),否则为(batch_size, seq_len,D*hidden_size)。其中D=2 if bidirectional==True else 1h_n:形状为(D*num_layer, batch_size, output_size)。其中D=2 if bidirectional==True else 1,output_size=proj_size if proj_size>0 else hidden_sizec_n:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 例子解析
import torch import torch.nn as nn lstm = nn.LSTM(10, 20, 2, proj_size=15) input = torch.randn(5, 3, 10) h_0 = torch.randn(2, 3, 15) c_0 = torch.randn(2, 3, 20) output, (h_n, c_n) = lstm(input, (h_0, c_0)) output.shape Out[1]: torch.Size([5, 3, 15]) h_n.shape Out[2]: torch.Size([2, 3, 15]) c_n.shape Out[3]: torch.Size([2, 3, 20])
3. GRU
3.1 GRU的结构

- r t r_t rt:重置门,用来重置历史信息 h t − 1 h_{t-1} ht−1
- z t z_t zt:更新门,用来更新当前时刻的状态
- h t ~ \widetilde{h_t} ht :当前时刻的临时状态,其输入是当前时刻的输入 x t x_t xt和经过重置后的历史信息 r t ⋅ h t − 1 r_t \cdot h_{t-1} rt⋅ht−1
- h t h_t ht:当前时刻的状态
3.2 GRU的种类
同RNN一样,只不过将RNN cell更换为GRU cell
3.3 GRU与LSTM比较
- 将忘记门和输入门组合成一个更新门
- 合并了单元状态和隐藏状态
3.4 GRU详解torch.nn.GRU

- 参数
input_size:输入序列x的特征长度hidden_size:隐藏层的特征长度num_layers:rnn层的数目。如果将其设置为2,将意味着将两个 RNN 堆叠在一起形成一个堆叠的 RNN,第二个 RNN 接收第一个 RNN 的输出并计算最终结果。默认值为1bias:是否使用bias,默认为Truebatch_first:如果为True,则输入和输出的tensor形状必须提供成(batch, seq, feature)而不是(seq,batch,feature),默认为Falsedropout:在除最后一层之外的每个 RNN 层的输出上引入一个 Dropout 层,dropout概率等于dropout。默认为0bidirectional:如果为True,则为双向RNN,默认为False
- 输入
input:当batch_first为False时,形状为(seq_len, batch_size, input_size),否则为(batch_size, seq_len,input_size)h_0:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 输出
output:当batch_first为False时,形状为(seq_len, batch_size,D*hidden_size),否则为(batch_size, seq_len,D*hidden_size)。其中D=2 if bidirectional==True else 1h_n:形状为(D*num_layer, batch_size, hidden_size)。其中D=2 if bidirectional==True else 1
- 例子解析
import torch import torch.nn as nn rnn = nn.GRU(10, 20, 2) input = torch.randn(5, 3, 10) h_0 = torch.randn(2, 3, 20) output, h_n = rnn(input, h_0) output.shape Out[1]: torch.Size([5, 3, 20]) h_n.shape Out[2]: torch.Size([2, 3, 20])
4. RNN为啥不能学习很久的历史信息?
我们将RNN简单表示为
- 隐状态:
h t = t a n h ( W I x t + W R h t − 1 ) h_t=tanh(W_Ix_t+W_Rh_{t-1}) ht=tanh(WIxt+WRht−1) - 输出:
y t = W O h t y_t=W_Oh_t yt=WOht
假设 E = 1 2 ( y ^ t − y t ) 2 E=\frac {1} {2} (\hat y_t - y_t)^2 E=21(y^t−yt)2, 对于时间步长 t t t,我们通过链式法则计算梯度
∂ E t ∂ W R = ∑ i = 0 t ∂ E t ∂ y t ∂ y t ∂ h t ∂ h t ∂ h i ∂ h i ∂ W R \frac {\partial E_t} {\partial W_R}= \sum_{i=0}^{t}\frac{\partial E_t}{\partial y_t} \frac {\partial y_t} {\partial h_t} \frac {\partial h_t} {\partial h_i} \frac {\partial h_i} {\partial W_R} ∂WR∂Et=i=0∑t∂yt∂Et∂ht∂yt∂hi∂ht∂WR∂hi
其中
∂ E t ∂ y t = y ^ t − y t \frac {\partial E_t} {\partial y_t}=\hat y_t - y_t ∂yt∂Et=y^t−yt
∂ y t ∂ h t = W O \frac {\partial y_t} {\partial h_t} = W_O ∂ht∂yt=WO
∂ h t ∂ h i = ∂ h t ∂ h t − 1 ∂ h t − 1 ∂ h t − 2 . . . ∂ h i + 1 ∂ h i = ∏ k = i t − 1 ∂ h k + 1 ∂ h k \frac {\partial h_t} {\partial h_i}=\frac {\partial h_t} {\partial h_{t-1}} \frac {\partial h_{t-1}} {\partial h_{t-2}} ... \frac {\partial h_{i+1}} {\partial h_{i}}=\prod_{k=i}^{t-1} \frac{\partial h_{k+1}} {\partial h_{k}} ∂hi∂ht=∂ht−1∂ht∂ht−2∂ht−1...∂hi∂hi+1=k=i∏t−1∂hk∂hk+1
∂ h i ∂ W R = h i − 1 \frac {\partial h_i} {\partial W_R}=h_{i-1} ∂WR∂hi=hi−1
现在我们来计算
∂ h k + 1 ∂ h k = t a n h ′ ⋅ W R \frac {\partial h_{k+1}} {\partial h_k}=tanh' \cdot W_R ∂hk∂hk+1=tanh′⋅WR
因此,如果我们反向传播 k k k个时间步长,则梯度会变成
∂ h k ∂ h 1 = ∏ i = 1 k t a n h ′ ⋅ W R \frac {\partial h_k} {\partial h_1}=\prod_{i=1}^{k}tanh' \cdot W_R ∂h1∂hk=i=1∏ktanh′⋅WR
其中, t a n h ′ tanh' tanh′总小于1,如果 W R W_R WR大于1,则会发生梯度爆炸;如果 W R W_R WR小于1,则会发生梯度消失。所以RNN无法学习到很久的信息。
5. RNN为啥使用Tanh而不使用relu作为激活函数?
∂ h k ∂ h k − 1 = ( 1 − h k 2 ) W R \frac {\partial h_k} {\partial h_{k-1}}=(1-h^2_k) W_R ∂hk−1∂hk=(1−hk2)WR
- 当激活函数为 T a n h Tanh Tanh时
由于 T a n h ′ ( x ) = 1 − T a n h 2 ( x ) Tanh'(x) = 1-Tanh^2(x) Tanh′(x)=1−Tanh2(x),所以当 W R W_R WR很大时,则 h k h_k hk接近于 1 1 1,所以 ( 1 − h k 2 ) W R (1-h^2_k)W_R (1−hk2)WR很小,故 ∂ h k ∂ h k − 1 \frac {\partial h_k} {\partial h_{k-1}} ∂hk−1∂hk有界 - 当激活函数为 R e L U ReLU ReLU时
由于 R e L U ′ ( x ) = { 0 , 1 } ReLU'(x)=\{0, 1\} ReLU′(x)={0,1},所以当 R e L U ′ ( x ) = 1 ReLU'(x)=1 ReLU′(x)=1,且 W R W_R WR很大,则 ∂ h k ∂ h k − 1 \frac {\partial h_k} {\partial h_{k-1}} ∂hk−1∂hk无界
6. LSTM是如何解决梯度爆炸/消失的?
我们将LSTM简单表示为
f t = σ ( W f [ h t − 1 , x t ] ) f_t=\sigma(W_f[h_{t-1}, x_t]) ft=σ(Wf[ht−1,xt])
i t = σ ( W i [ h t − 1 , x t ] ) i_t=\sigma(W_i[h_{t-1}, x_t]) it=σ(Wi[ht−1,xt])
o t = σ ( W o [ h t − 1 , x t ] ) o_t=\sigma(W_o[h_{t-1}, x_t]) ot=σ(Wo[ht−1,xt])
C t ~ = t a n h ( W C [ h t − 1 , x t ] ) \widetilde{C_t}=tanh(W_C[h_{t-1}, x_t]) Ct =tanh(WC[ht−1,xt])
C t = f ⋅ C t − 1 + i ⋅ C t ~ C_t=f \cdot C_{t-1}+i \cdot \widetilde {C_t} Ct=f⋅Ct−1+i⋅Ct
h t = o t ⋅ t a n h ( C t ) h_t=o_t \cdot tanh(C_t) ht=ot⋅tanh(Ct)
RNN之所以会导致梯度爆炸/消失,是因为隐状态求梯度时 ∂ h k + 1 ∂ h k = t a n h ′ ⋅ W R \frac {\partial h_{k+1}} {\partial h_k}=tanh' \cdot W_R ∂hk∂hk+1=tanh′⋅WR这一项会被累乘多次,所以我们来看看LSTM的隐状态的梯度变化,通过链式求导法则可知:
∂ C t ∂ C t − 1 = ∂ C t ∂ f t ∂ f t ∂ h t − 1 ∂ h t − 1 ∂ C t − 1 + ∂ C t ∂ C t − 1 + ∂ C t ∂ i t ∂ i t ∂ h t − 1 ∂ h t − 1 ∂ C t − 1 + ∂ C t ∂ C t ~ ∂ C t ~ ∂ h t − 1 ∂ h t − 1 ∂ C t − 1 \frac {\partial C_t} {\partial C_{t-1}}=\frac {\partial C_t} {\partial f_t} \frac {\partial f_t} {\partial h_{t-1}} \frac {\partial h_{t-1}} {\partial C_{t-1}}+\frac {\partial C_t} {\partial C_{t-1}} + \frac {\partial C_t} {\partial i_t} \frac {\partial i_t} {\partial h_{t-1}} \frac {\partial h_{t-1}} {\partial C_{t-1}} + \frac {\partial C_t} {\partial \widetilde{C_t}} \frac {\partial \widetilde{C_t}} {\partial h_{t-1}} \frac {\partial h_{t-1}} {\partial C_{t-1}} ∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂Ct−1∂Ct+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂Ct ∂Ct∂ht−1∂Ct ∂Ct−1∂ht−1
现在让我们明确这些导数
∂ C t ∂ C t − 1 = C t − 1 σ ′ ( ∗ ) W f ⋅ o t − 1 t a n h ′ ( C t − 1 ) + f t + C t ~ σ ( ∗ ) W i ⋅ o t − 1 t a n h ′ ( C t − 1 ) + i t t a n h ′ ( ∗ ) W C ⋅ o t − 1 t a n h ′ ( C t − 1 ) \frac {\partial C_t} {\partial C_{t-1}}=C_{t-1} \sigma'(*)W_f \cdot o_{t-1}tanh'(C_{t-1}) + f_t + \widetilde{C_t} \sigma (*)W_i \cdot o_{t-1} tanh'(C_{t-1}) + i_t tanh'(*)W_C \cdot o_{t-1}tanh'(C_{t-1}) ∂Ct−1∂Ct=Ct−1σ′(∗)Wf⋅ot−1tanh′(Ct−1)+ft+Ct σ(∗)Wi⋅ot−1tanh′(Ct−1)+ittanh′(∗)WC⋅ot−1tanh′(Ct−1)
由于RNN中, ∂ h t ∂ h t − 1 \frac {\partial h_t} {\partial h_{t-1}} ∂ht−1∂ht的值要么取大于1要么处于[0, 1]之间,所以经过连乘后会导致梯度爆炸/消失;而在LSTM中, ∂ C t ∂ C t − 1 \frac {\partial C_t} {\partial C_{t-1}} ∂Ct−1∂Ct在任何步长既可以取大于1,也可以取[0, 1]之间(因为 f t , o t , i t , C t − 1 , C t ~ f_t,o_t,i_t,C_{t-1},\widetilde{C_t} ft,ot,it,Ct−1,Ct 可以来调节。例如可以使 f t f_t ft接近1来解决梯度消失,至于梯度爆炸可以设置梯度阈值)
用ResNet的思维来理解,上面介绍LSTM时,提到了其用到了ResNet的思想,通过让 f t f_t ft趋向1, i t i_t it趋向0,让历史信息直接流向未来而忽略当前时刻的信息,这样就类似与一个残差结构。
项目实战:利用LSTM进行股票预测分析
参考链接:
- https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
- https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://weberna.github.io/blog/2017/11/15/LSTM-Vanishing-Gradients.html
- https://www.zhihu.com/question/34878706