【论文笔记】RRU-Net: The Ringed Residual U-Net for Image Splicing Forgery Detection
发布于CVPRW2019
原文链接:https://ieeexplore.ieee.org/document/9054068/
源码:https://github.com/yelusaleng/RRU-Net
摘要
传统的特征提取方法和基于卷积神经网络(CNN)的检测方法都是通过利用篡改和非篡改区域间的差异来完成拼接篡改检测。
本文提出了一种用于图像拼接伪造检测的环状残差U-Net(RRU-Net)。是一个端到端的图像本质属性分割网络,它独立于人类的视觉系统,无需任何预处理和后处理就可以完成伪造检测。RRU-Net的核心思想是强化CNN的学习方式,其灵感来自于人脑的回忆和巩固机制,通过CNN中的残差传播和反馈过程来实现。残差传播对输入特征信息进行回忆,以解决深层网络中的梯度退化问题;残差反馈对输入特征信息进行整合,使未被篡改和被篡改区域的图像属性差异更加明显。实验结果表明,该方法的性能达到了当时的SOTA。
方法的提出
拼接图像中,未被篡改和被篡改的区域之间存在着图像属性的差异(如光照、阴影、传感器噪声、相机反射等)可以用来识别被篡改的图像,并定位被篡改的区域。现有的拼接篡改检测方法都试图利用一些特征提取方法来探索图像属性的差异。
传统的基于特征提取的检测方法分为四类,但都具有一定的局限性(只关注一个指定的图像属性):
- 基于图像本质属性的检测方法(如果对篡改后进行一些隐藏处理(如整体模糊),可能会失败)
- 基于成像设备属性的检测方法(如果图像的设备噪声强度很弱,可能会失败)
- 基于图像压缩属性的检测方法(只能检测JPEG格式保存的图像)
- 基于哈希技术的检测方法(依赖于未被篡改的原始图像的哈希值)
基于CNN的检测方法:
- 最初只能判断图像是否被篡改,但它不能定位被篡改的区域。
- 使用非重叠的图像补丁作为CNN的输入。然而,当一个图像补丁完全来自于被篡改的区域时,这个图像补丁将被判断为未被篡改的标签。
- 利用较大的图像补丁来揭示被篡改区域的图像属性。然而,如果伪造的图像很小,检测方法可能会失败。
- 对于现有的基于CNN的检测方法,由于他们使用图像补丁作为网络的输入,上下文的空间信息被丢失,这很容易导致错误的预测。此外,当网络结构较深时,会出现梯度退化问题,对特征的辨别力变弱,这将导致拼接造假检测更加困难甚至失败。
提出了RRU-Net,它可以有效地减少错误的预测,因为它更好地利用了图像中的背景空间信息。
相关工作
U-Net
通过收缩路径(连续层)捕获上下文信息,对输出特征进行上采样,然后与通过对称扩展路径传播的高分辨率特征相结合,这减少了细节信息的损失并实现了精确定位。然而U-Net可以在网络的各层之间提取一些相对较浅的区别特征,但是只有U-Net结构的两边是相互作用的,这不足以确定被篡改的区域。此外,当网络架构更深时,梯度退化问题会出现。
ResNet
对于拼接伪造检测,梯度退化问题将导致另一个额外的严重问题。通过直接多层结构,图像本质属性特征的区分度会变弱,使得图像本质属性的差异变得难以发现。为了解决梯度退化问题并同时加强CNN的学习方式,应该更有效地利用残差映射。
RRU-Net
残差传播(Residual Propagation)
为解决梯度退化问题,在每个堆叠层添加残差传播。下图2显示了一个构建模块,它由两个卷积(扩展卷积,dconv)层和残差传播组成。
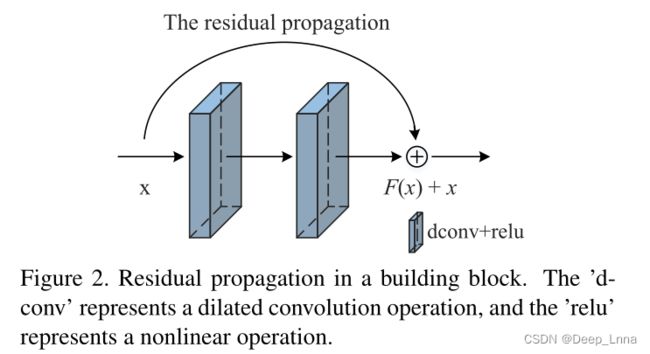
构造块的输出定义为:
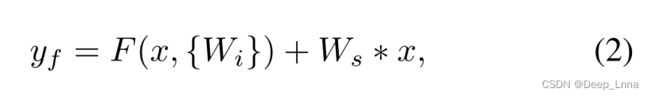

残差块中有两层,故F的表达式如下:

残差传播看起来像人脑的回忆机制。我们在多学几个新知识的时候可能会忘记之前的知识,所以需要回忆机制来帮助我们唤起那些之前的模糊记忆。
残差反馈(Residual Feedback)
在拼接篡改检测中,如果能够进一步加强未篡改区域和篡改区域之间图像本质属性的差异,检测的性能就可以进一步提高。
RGB-N中通过使伪造图像穿过SRM过滤层来叠加噪声属性的附加差异,以增强检测结果。但是,它是一种手动选择的方法,只能用于RGB图像的伪造检测。此外,当未篡改区域和被篡改区域来自相同品牌和型号的摄像机时,SRM滤波层会急剧降低有效性,因为它们具有相同的噪声属性。
为了进一步加强图像本质属性的差异性,提出了残差反馈,这是一种自动学习的方法,而不仅仅是针对一个或几个特定的图像属性。又将attention机制添加到残差反馈中,更加关注输入信息的鉴别特征。使用一种简单的具有sigmoid激活函数的门控机制来学习区别特征通道之间的非线性相互作用,并避免特征信息的扩散,然后我们将sigmoid激活获得的响应值叠加在输入信息上以放大未篡改和篡改区域之间的图像本质属性的差异。构建模块中的残差反馈如下图3所示,

构造块的输出定义为:


残差反馈看起来像人脑的巩固机制。我们需要巩固我们已经学过的知识,获得新的特征理解。残差反馈可以放大输入中未篡改和篡改区域之间的图像本质属性的差异,如下图1所示。©通过残差反馈,篡改区域“鹰”被放大到全局最大响应值。

残差反馈的作用
- 放大输入中未篡改和篡改区域之间的图像本质属性的差异
- 区别性特征强化的同时也可以看作是对消极标签特征的压制
- 网络在训练过程中的收敛速度更快
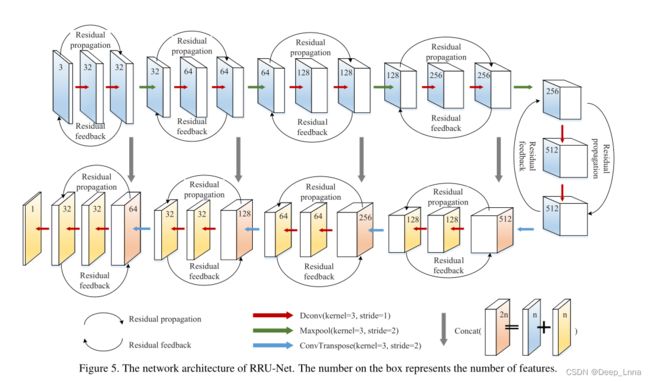
RRU-Net的网络结构
下图4结合了残差传播和残差反馈的所提出的环形残差结构。
残差传播就像人脑的回忆机制,回忆输入的特征信息来解决更深层网络中的退化问题;残差反馈整合了输入的特征信息,使得未篡改区域和篡改区域的图像本质属性差异被放大。

RRU-Net保证了在网络各层之间提取特征时,对图像本质属性特征的区分更加明显,比传统的基于特征提取的检测方法和现有的基于CNN的检测方法具有更好和稳定的检测性能。
RRU网的网络架构如下图5所示,它是一个端到端的图像本质属性分割网络,不需要任何预处理和后处理就可以直接检测出拼接伪造。
实验部分
数据集
CASIA:拼接篡改区域是体积小做工精细对象
COLUMB:拼接篡改区域是简单的、大的、无意义的区域
训练集和验证集的图像大小调整为384x256,然后通过随机高斯噪声、JPEG压缩和随机翻转等方法进行数据增强,使两个数据集的容量提高了四倍。

评价指标
- 像素水平上:F1分数
- 图像水平上:准确率
比较检测方法
- 三种传统的基于特征提取的检测方法:DCT,CFA,NOI
- 两种基于CNN的检测方法:DFNet,C2R-Net
- 两种语义分割方法:FCN,DeepLab v3
- U-Net、RU-Net(去掉残差反馈)
像素级检测
在简单剪接伪造下的检测结果
下图6是在简单剪接伪造的情况下RRU-Net和其他比较的检测方法。从主观角度来看,很明显,RRU-Net的性能优于其他八种检测方法。

为了更加客观和公平地进行比较,我们计算了两个数据集上检测结果的精确度、召回率和F-measure的平均值,如表2所示。可以看出,RRU-Net在精度、召回率和F-measure上都优于其他9种检测方法。虽然RRU-Net的召回率比DCT和DeepLab v3稍差,但从主观角度来看,我们可以发现DCT几乎失去了有效性,DeepLab v3的检测效果也远不如RRU-Net。

各种攻击下的检测结果
JPEG压缩
下图7表示JPEG压缩攻击下的比较结果。这三列分别代表精度、召回率和F1值。(a1) -(a3)表示在CASIA上的实验结果;(b1) - (b3)表示在COLUMB上的实验结果。

RRU-Net的召回率比CFA和DCT差,原因是两者几乎都将整幅图像检测为篡改区域。没有残差传播和残差反馈的U-Net的性能和鲁棒性远低于RU-Net和RRU-Net。
通过实验可以发现,在两个数据集上,RRU-Net的检测结果优于其他检测方法,并且在JPEG压缩攻击下具有较高的鲁棒性。
噪声破坏
下图8中示出了在噪声(高斯分布加性噪声)破坏攻击下的比较实验结果。
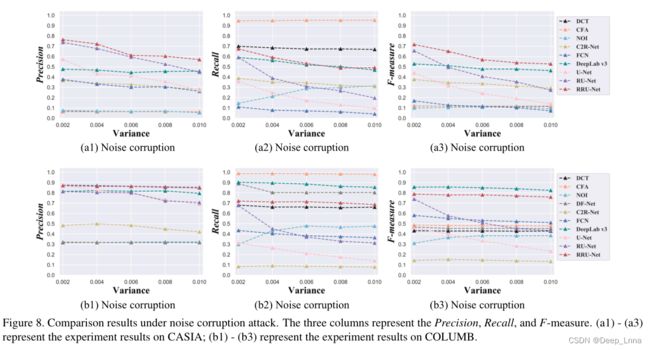
在CASIA上,RRU-Net的精度和F1值都优于其他八种检测方法。在COLUMB上,RRU-Net的精度优于其他九种检测方法,RRU-Net的F-measure略低于DeepLab v3。在噪声恶化攻击下,没有剩余反馈的RU-Net的鲁棒性在两个数据集上都表现较弱。
从上面的分析可以看出,RRU-Net在两个数据集上的噪声破坏攻击下表现出了更好和稳定的性能。
图像级检测
下表3是RRU-Net和其他九种检测方法在图像级的检测结果。

明显,RRU-Net的检测精度优于其他九种检测方法,证明了RRU-Net不仅可以定位拼接伪造图像中的篡改区域,而且可以判断图像是否被篡改。
总结
本文提出了一种用于图像拼接伪造检测的环状残差U-Net(RRU-Net)。是一个端到端的图像本质属性分割网络,它独立于人类的视觉系统,无需任何预处理和后处理就可以完成伪造检测。RRU-Net的核心思想是强化CNN的学习方式,其灵感来自于人脑的回忆和巩固机制,通过CNN中的残差传播和反馈过程来实现。同时,我们也从理论分析和实验比较的角度证明了RRU-Net中环状残差结构的有效性。
在未来的工作中,我们将进一步探索和可视化篡改区域和未篡改区域之间的潜在区别特征,以解释图像拼接伪造检测的关键问题。