Scala学习笔记
Scala介绍
官方网址:http://www.scala-lang.org
Scala既是面向对象的语言,也是面向函数的语言。scala可以为你在做大量代码重用和扩展是提供优雅的层次结构,并可以通过高阶函数来实现这样的目标。(高阶函数是函数式编程里的特性之一,允许函数作为参数传递,也允许函数作为返回值来返回)
Scala语言的特点
Scala并不适于编程的初级课程。相反,它是为专业程序员定制的强力语言。
1)它是一门现代编程语言,作者是Martin Odersky(javac之父),受到Java、Ruby、Smalltalk、ML、Haskell、Erlang等语言的影响。
2)它即是一门面向对象(OOP)语言,每个变量都是一个对象,每个“操作符”都是方法。scala语言在面向对象的方面,要比java更彻底。
它同时也是一门函数式编程(FP)语言,可以将函数作为参数传递。你可以用OOP、FP,或者两者结合的方式编写代码。
3)Scala代码通过scalac编译成.class文件,然后在JVM上运行,可以无缝使用已有的丰富的Java类库。即Scala的代码会编译成字节码,运行在Java虚拟机(JVM)上。
4)接触语言的第一天你就能编出有趣的程序,但是这门语言很深奥,随着学习的深入,你会发现更新、更好的编写代码的方式。Scala会改变你对编程的看法。针对同一任务,可以有很多种不同的实现方式,并且可读性以及性能都有不一样的体现。
Scala Windows运行环境配置及使用
实现步骤:
1)双击运行安装
![]()
2)添加scala安装目录的bin目录路径到系统环境变量中

3)通过cmd命令窗口,输入scala

交互模式
可以通过命令行直接输入scala命令,比如:
![]()
使用IDE来开发Scala
解压即可使用
![]()
创建 scala project

工程创建完毕后,创建scala object
编写代码

Scala 基础语法一



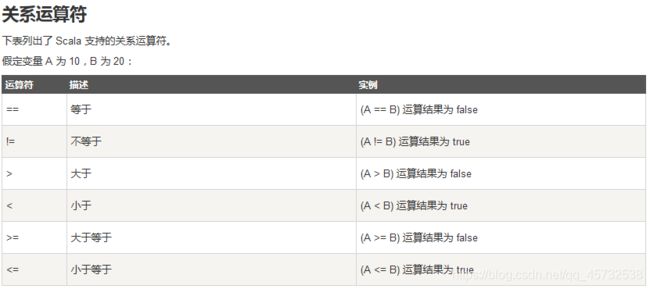



Scala 基础语法二



代码实践与知识点总结:
知识点:
1.Scala worksheet是IDE工具提供的交互式模式。左侧写代码,右侧出结果。
一般用于测试或练习
2.Eclipse更改字体:Window->Preference->color and font
->下拉basic->编辑 text font->更改即可
3.scala中的对象分为变量和常量两种
变量:var。创建后可以修改
常量:val。创建后不可以修改
4.scala以换行符为结束标识,不需要加;结束。
5.scala如果在一行中写多条语句,此时必须使用;隔开
比如:val v3=“hello” ; val v4=“world”
6.scala不需要显示的声明对象的类型。可以根据赋值结果自动推断对象类型
7.scala也可以显示的声明对象的类型。形式:
val v4:String=“world”
val v5:Int=200
8.scala中没有基本类型,都是对象。所以从这点来看,scala的面向对象比java更彻底
9.eclipse 默认的提示快捷键:alt+/
10.eclipse更改快捷键:window->preference->keys->content assist->更改键位 保存即可:
学习String常用的API
知识点
(我发现如果方法没有参数的话,小括号可以省略)
1.重点掌握String 的提取和删除方法。take drop等方法
2.scala的API手册的位置:scala安装目录/api/scala-library/index.html
3.scala的算术运算符优先级同java。此外,也可以通过调用方法的形式运算,比如:
val r13=num.+(30).*(2)=80
这种情况是以方法的调用顺序来执行。
object Demo02 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
val s1="hello world" //> s1 : String = hello world
val r1=s1.split(" ") //> r1 : Array[String] = Array(hello, world)
//重复n次
val r2=s1.*(3) //> r2 : String = hello worldhello worldhello world
//取出前n项数据并返回
val r3=s1.take(2) //> r3 : String = he
//取出后n项数据并返回
val r4=s1.takeRight(4) //> r4 : String = orld
//删除前n项数据并返回剩余数据
val r5=s1.drop(2) //> r5 : String = llo world
//删除后n项数据并返回剩余数据
val r6=s1.dropRight(2) //> r6 : String = hello wor
//练习1:提取身份证的后4位
val s2="2201232138119382" //> s2 : String = 2201232138119382
val r7=s2.takeRight(4) //> r7 : String = 9382
//练习2:提取用户手机号
val s3="tom135231313bj" //> s3 : String = tom135231313bj
val r8=s3.drop(3).dropRight(2) //> r8 : String = 135231313
val s4="12345" //> s4 : String = 12345
//翻转字符串
val r9=s4.reverse //> r9 : String = 54321
val r10=s4.toInt //> r10 : Int = 12345
val r11=s4.toDouble //> r11 : Double = 12345.0
val num=10 //> num : Int = 10
val r12=num+30*2 //> r12 : Int = 70
val r13=num.+(30).*(2) //> r13 : Int = 80
val r14=10.+(30).*(2) //> r14 : Int = 80
}
if else 的使用:
知识点:
1.scala if else的作用及结构同java
2.scala if else有返回值,可以接
3.scala的Unit类比于Java的void 空类型
4.scala的通用规则:scala会将方法体中{}最后的一行代码作为返回值返回。不需要加return关键字
5.println 打印并换行
6.print 打印不换行
7.scala的打印函数 返回值类型是Unit 空类型
8.scala的通用化简规则:如果方法体{}只有一行代码,则方法体{}可以省略
9.scala所有类的父类是Any,类比于Java的Object。当返回值类型不一致时,会返回Any。
object Demo03 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
val num=10 //> num : Int = 10
val result=if(num>5)println("big")else println("small")
//> big
//| result : Unit = ()
//练习1:为tom评级,根据得分评级。如果score>80,返回good。score<=80,返回bad
val score=99 //> score : Int = 99
val tom=if(score>80)"good"else"bad" //> tom : String = good
val r2=if(num>5){
"big"
}else if(num==5){
"equal"
}
else{
"small"
} //> r2 : String = big
}
while和for循环
知识点:
1.scala的while用法及结构同java
2.scala通过下标操作集合类型,使用的是(index),下标从0开始。 java操作下标是[index]
3.scala中没有++ --操作
4.scala通用的化简规则:如果调用的方法,只有一个参数,则方法的 .()可以省略
object Demo04 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
val a1=Array(1,2,3,4) //> a1 : Array[Int] = Array(1, 2, 3, 4)
var index=0 //> index : Int = 0
while(index<a1.length){
println(a1(index))
index+=1
} //> 1
//| 2
//| 3
//| 4
for(i<-a1){
println(i) //> 1
//| 2
//| 3
//| 4
}
//to 方法。用于生产指定的区间集合数据
val r1=1 to 10 //> r1 : scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7
//| , 8, 9, 10)
//until 方法。 用于生产指定的区间集合数据 ,不包含最后的元素
val r2=1.until(10) //> r2 : scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
//生产区间,并指定步长
val r3=1.to(10,2) //> r3 : scala.collection.immutable.Range.Inclusive = Range(1, 3, 5, 7, 9)
val r4=1.until(10,2) //> r4 : scala.collection.immutable.Range = Range(1, 3, 5, 7, 9)
for(i<-1.to(10))println(i) //> 1
//| 2
//| 3
//| 4
//| 5
//| 6
//| 7
//| 8
//| 9
//| 10
//练习1:要求通过for打印如下的图形
//*
//**
//***
//****
for(i<-1.to(4))println("*".*(i)) //> *
//| **
//| ***
//| ****
//练习2:要求通过for打印出1~10之间的所有偶数数据
for(i<-1 to 10){
if(i%2==0){
println(i)
} //> 2
//| 4
//| 6
//| 8
//| 10
}
//练习3:要求通过for打印出99乘法表。项之间的分隔符,使用制表符 \t
//1*1=1
//1*2=2 2*2=4
//1*3=3 2*3=6 3*3=9
//....
for(a<-1 to 9){
for(b<-1 to a){
print(b+"*"+a+"="+a*b+"\t")
}
println()
} //> 1*1=1
//| 1*2=2 2*2=4
//| 1*3=3 2*3=6 3*3=9
//| 1*4=4 2*4=8 3*4=12 4*4=16
//| 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
//| 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
//| 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
//| 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
//| 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
//|
//scala的for,可以将条件语句写在for条件中
for(i<-1 to 10;if i%2==0){println(i)} //> 2
//| 4
//| 6
//| 8
//| 10
for(i<-1 to 10;if i%2==0&&i>4){println(i)} //> 6
//| 8
//| 10
for(i<-1 to 10;if i%2==0;if i>4){println(i)} //> 6
//| 8
//| 10
for(a<-1 to 9;b<-1 to a;val sep=if(a==b)"\r\n"else "\t")print(b+"*"+a+"="+b*a+sep)
//> 1*1=1
//| 1*2=2 2*2=4
//| 1*3=3 2*3=6 3*3=9
//| 1*4=4 2*4=8 3*4=12 4*4=16
//| 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
//| 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
//| 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
//| 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
//| 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
//s"$" 可以获取字符串中指定的数据
//在for()条件中赋值时,必须使用常量val来接。不能使用变量var
for(a<-1 to 9;b<-1 to a;val sep=if(a==b)"\r\n"else "\t")print(s"$b*$a=${b*a}$sep")
//> 1*1=1
//| 1*2=2 2*2=4
//| 1*3=3 2*3=6 3*3=9
//| 1*4=4 2*4=8 3*4=12 4*4=16
//| 1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
//| 1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
//| 1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
//| 1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
//| 1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
val a2=Array(1,2,3,4) //> a2 : Array[Int] = Array(1, 2, 3, 4)
//for yield:遍历一个集合,返回一个新集合
//遍历什么集合类型,就会返回对应的集合类型
val a3=for(i<-a2;if i>2)yield{i} //> a3 : Array[Int] = Array(3, 4)
val l2=List(1,2,3,4) //> l2 : List[Int] = List(1, 2, 3, 4)
val l3=for(i<-l2;if i>2)yield{i} //> l3 : List[Int] = List(3, 4)
}
break、continue、try catch finally
知识点:
1.scala break 跳出循环,需要额外导包
2.scala 通过import导包,可以代码中任意位置导包。需要注意作用域问题
3.scala 没有contiune关键字的,也是需要通过break来实现。
如果breakable()在循环外,是break效果
如果breakable()在循环内,是continue效果
4.scala 的try catch finally 用法结构同java。需要注意的是
在catch中,通过case来捕获具体的异常来处理。形式:
cast t:异常类型=>{处理代码}
5.scala 的match case 类比于java 的switch case
object Demo05 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
breakable(
for(i<-1 to 10){
if(i>8){
break
}else{
println(i)
}
}
) //> 1
//| 2
//| 3
//| 4
//| 5
//| 6
//| 7
//| 8
for(i<-1 to 10){
breakable(
if(i==8){
break
}else{
println(i)
}
) //> 1
//| 2
//| 3
//| 4
//| 5
//| 6
//| 7
//| 9
//| 10
}
try{
throw new RuntimeException
}catch{
case t:NullPointerException=>{
println("null error")
}
case t:Exception=>{
println("other error")
}
}finally{
println("end")
} //> other error
//| end
val s1="hello" //> s1 : String = hello
val result=s1 match{
case "hello"=>{100}
case "world"=>{200}
} //> result : Int = 100
}
Scala函数
函数定义
知识点:
1.scala函数的声明,形式: def 函数名(参数列表):返回值类型={方法体}
2.scala会将方法体{}最后一行代码作为返回值返回,不需要加return
3.scala函数不需要写返回值类型,可以根据返回值自动推断
4.scala函数和方法体之间如果没有=,则返回值类型一律为Unit。所以注意,以后写scala函数都带有=号
5.scala的泛型声明使用的[],比如Array[String],List[Int]等。不同于java: Array
6.scala函数支持默认参数机制。形式 def 函数名(形参名:类型=默认值)={}
7.scala函数支持变长参数机制。形式 def 函数名(形参名:类型*)={}
注意:变长参数必须位于参数列表最后。
object Demo06 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
def f1(a:Int,b:Int):Int={
a+b
} //> f1: (a: Int, b: Int)Int
def f2(a:Int,b:Int)={
a+b
} //> f2: (a: Int, b: Int)Int
def f3(a:Int,b:Int){
a+b
} //> f3: (a: Int, b: Int)Unit
//练习1:编写一个函数,接受一个字符串。函数体中把字符串按空格切分并返回
def f4(a:String):Array[String]={
a.split(" ")
} //> f4: (a: String)Array[String]
def f5(a:String)={
a.split(" ")
} //> f5: (a: String)Array[String]
f5("hello world") //> res0: Array[String] = Array(hello, world)
//练习2:接收整型数组并打印所有数据
def f6(a:Array[Int])={
for(i<-a){println(i)}
} //> f6: (a: Array[Int])Unit
f6(Array(1,2,3,4,5)) //> 1
//| 2
//| 3
//| 4
//| 5
def f7(a:Int,b:Int=100)={
a+b
} //> f7: (a: Int, b: Int)Int
f7(50,80) //> res1: Int = 130
//scala 变长参数
def f8(a:Int*)={
} //> f8: (a: Int*)Unit
f8(2,3,4,5)
}
Scala函数的分类以及匿名函数、高阶函数的使用
知识点:
1.scala的函数可以分为4种:
①成员函数,定义在类内部的函数,作为类的一个成员,称为成员函数
②本地函数,定义在函数内的函数,称为本地函数
③匿名函数,特点:没有函数名;参数列表和{}之间的连接符是=>
关键是记住匿名函数的作用:
匿名函数可以作为参数赋值、作为参数传递、作为参数作为返回值返回
④
高阶函数,就是操作其他函数的函数。
Scala 中允许使用高阶函数, 高阶函数可以使用其他函数作为参数,或者使用函数作为输出结果。
高阶函数,把函数当做参数传递的函数(可以看成是对匿名函数的定义),就是高阶函数
2.scala语言,既是面向对象的语言,也是面向函数的语言。
函数是一等公民,即函数可以作为参数赋值、传递、返回值返回、类成员,以及支持高阶函数
3.scala的化简规则:
①如果{}只有一行代码,{}可以省略
②在传入匿名函数时,匿名函数的参数类型可以省略,定义匿名函数必须要有类型
③在传入匿名函数时,如果匿名函数的参数只有一个,则参数列表的()可以省略;定义匿名函数的时候也是一样
④终极化简规则:可以通过 _ 代替匿名函数的参数进行化简
object Demo07 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
def f1(a:Int,b:Int)=a+b //> f1: (a: Int, b: Int)Int
//匿名函数
(a:Int,b:Int)=>{a+b} //> res0: (Int, Int) => Int = scala的递归函数
知识点:
1.scala编写递归函数,函数的返回值类型必须显式声明。
2.编写递归函数的技巧,找出两要素:
①找出项与项之间的函数关系
②找出结束条件
3.scala编写递归函数时,结束条件的返回值加return
object Demo08 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
//给定一个斐波那契数列:2 3 5 8 13 21 ...
//编写一个递归函数f1(n:Int)
//传入一个整型n,返回第n项对应的数字。比如:f1(0)=2 f(1)=3
//函数关系:f(n)=f(n-1)+f(n-2)
//结束条件:f(0)=2 f(1)=3
def f1(n:Int):Int={
if(n==0) return 2
if(n==1) return 3
else f1(n-1)+f1(n-2)
} //> f1: (n: Int)Int
f1(6) //> res0: Int = 34
//练习1: 2 3 4 9 16 81 ...
//编写一个递归函数f2(n:Int),传入一个整型n,返回第n项对应的数字
//函数关系:f(n)=f(n-2)*f(n-2)
//结束条件:f(0)=2 f(1)=3
def f2(n:Int):Int={
if(n==0) return 2
if(n==1) return 3
else f2(n-2)*f2(n-2)
} //> f2: (n: Int)Int
f2(6) //> res1: Int = 256
//练习2: 2 3 4 9 8 27 16 81 ...
// 0 1 2 3 4 5 6 7
//如果n是偶数项, f(n)=2*f(n-2)
//如果n是奇数项, f(n)=3*f(n-2)
//结束条件:f(0)=2 f(1)=3
def f3(n:Int):Int={
if(n==0) return 2
if(n==1) return 3
if(n%2==0) 2*f3(n-2)
else 3*f3(n-2)
} //> f3: (n: Int)Int
f3(8) //> res2: Int = 32
}
柯里化技术
知识点:
1.scala支持柯里化技术。允许将接受多个参数的函数转变为接受单一参数的函数
2.通过柯里化技术,可以自建控制结构,使得调用层次更加清晰明确
def f3(a:Int,b:Int,f:(Int,Int)=>Int)={f(a,b)} //> f3: (a: Int, b: Int, f: (Int, Int) => Int)Int
//练习2:写出f3等价的柯里化形式
def f31(a:Int)(b:Int)(f:(Int,Int)=>Int)={f(a,b)}//> f31: (a: Int)(b: Int)(f: (Int, Int) => Int)Int
def f32(a:Int)(b:Int,f:(Int,Int)=>Int)={f(a,b)} //> f32: (a: Int)(b: Int, f: (Int, Int) => Int)Int
//留意这种形式,一部分是普通参数,另一部分是匿名函数。这种结构称为自建控制结构
def f33(a:Int,b:Int)(f:(Int,Int)=>Int)={f(a,b)} //> f33: (a: Int, b: Int)(f: (Int, Int) => Int)Int
Collection 集合类型
学习Scala的Collection 集合类型以及相关的API。Scala的集合类型包含:Array,List,Set,Map,Tuple等
Array数组
object Demo02 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
//创建一个定长数组并赋值。
val a1=Array(1,2,3,4) //> a1 : Array[Int] = Array(1, 2, 3, 4)
//创建一个定长数组,自动根据指定的泛型赋值
val a2=new Array[Int](3) //> a2 : Array[Int] = Array(0, 0, 0)
//创建一个变成数组并赋值。变长数组可以追加元素
val a3=scala.collection.mutable.ArrayBuffer(1,2,3)
//> a3 : scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer(1, 2, 3)
//通过下标操作Array。下标从0开始
a1.apply(0) //> res0: Int = 1
//apply方法可以省略,形式如下。
a1(0) //> res1: Int = 1
//通过下标修改数据
a1(0)=10
a1 //> res2: Array[Int] = Array(10, 2, 3, 4)
//变长数组追加元素
a3.append(4,5,6)
val a4=Array(2,1,5,3,4) //> a4 : Array[Int] = Array(2, 1, 5, 3, 4)
//最大值
val r1=a4.max //> r1 : Int = 5
//最小值
val r2=a4.min //> r2 : Int = 1
//求和
val r3=a4.sum //> r3 : Int = 15
//练习1:求出a4这一组数据的均值
val r4=a4.sum.toDouble/a4.length //> r4 : Double = 3.0
//取出前n项数据并返回到新的集合中
val r5=a4.take(3) //> r5 : Array[Int] = Array(2, 1, 5)
//取出后n项数据并返回到新的集合中
val r6=a4.takeRight(2) //> r6 : Array[Int] = Array(3, 4)
//练习2:求出a4前4项数据的极差(极大值-极小值)
val r7=a4.take(4) //> r7 : Array[Int] = Array(2, 1, 5, 3)
val r8=r7.max-r7.min //> r8 : Int = 4
//删除前n个元素,并将剩余元素返回到新的集合中
val r9=a4.drop(2) //> r9 : Array[Int] = Array(5, 3, 4)
//删除后n个元素,并将剩余元素返回到新的集合中
val r10=a4.dropRight(2) //> r10 : Array[Int] = Array(2, 1, 5)
//练习3:求出a4中间项的均值(1,5,3)
val r11=a4.drop(1).dropRight(1) //> r11 : Array[Int] = Array(1, 5, 3)
val r12=r11.sum.toDouble/r11.length //> r12 : Double = 3.0
val a5=Array(1,2,3) //> a5 : Array[Int] = Array(1, 2, 3)
val a6=Array(3,4,5) //> a6 : Array[Int] = Array(3, 4, 5)
//并集
val r13=a5.union(a6) //> r13 : Array[Int] = Array(1, 2, 3, 3, 4, 5)
//交集,将相同的数据返回到新的集合中
val r14=a5.intersect(a6) //> r14 : Array[Int] = Array(3)
//差集,将相异的数据返回到集合中。注意取差集有方向
val r15=a5.diff(a6) //> r15 : Array[Int] = Array(1, 2)
val r16=a6.diff(a5) //> r16 : Array[Int] = Array(4, 5)
//去重
val r17=r13.distinct //> r17 : Array[Int] = Array(1, 2, 3, 4, 5)
//返回集合的头元素,有别与take(1)
val r18=a5.head //> r18 : Int = 1
val r19=a5.take(1) //> r19 : Array[Int] = Array(1)
//返回集合的尾元素,有别与takeRight(1)
val r20=a5.last //> r20 : Int = 3
val r21=a5.takeRight(1) //> r21 : Array[Int] = Array(3)
val a7=Array(1,2,3,4,5) //> a7 : Array[Int] = Array(1, 2, 3, 4, 5)
//将集合中的所有元素返回为一个String,可以指定分隔符
val r22=a7.mkString //> r22 : String = 12345
val r23=a7.mkString("|") //> r23 : String = 1|2|3|4|5
//翻转集合
val r24=a7.reverse //> r24 : Array[Int] = Array(5, 4, 3, 2, 1)
//filter:根据指定的匿名函数规则做过滤。将过滤后的数据返回到新的集合中
//过滤a7中偶数元素并且大于2的元素
val r25=a7.filter {x=>x%2==0&&x>2} //> r25 : Array[Int] = Array(4)
//练习4:过滤出男性数据
val a8=Array("tom M 23","rose F 18","jim M 30") //> a8 : Array[String] = Array(tom M 23, rose F 18, jim M 30)
val r26=a8.filter { line => line.contains("M") }//> r26 : Array[String] = Array(tom M 23, jim M 30)
val r27=a8.filter { line => line.split(" ")(1).equals("M") }
//> r27 : Array[String] = Array(tom M 23, jim M 30)
//练习5:过滤a8中大于18岁的数据
val r28=a8.filter { line => line.split(" ")(2).toInt>18 }
//> r28 : Array[String] = Array(tom M 23, jim M 30)
val a9=Array(1,2,3,3,5,5,4,7,9) //> a9 : Array[Int] = Array(1, 2, 3, 3, 5, 5, 4, 7, 9)
//练习6:求出a9中所有不同的奇数的总和
val r29=a9.filter { num => num%2==1 }.distinct.sum
//> r29 : Int = 25
}
List集合
object Demo03 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
//创建一个定长List并赋值
val l1=List(1,2,3,4) //> l1 : List[Int] = List(1, 2, 3, 4)
//创建一个变长List并赋值
val l2=scala.collection.mutable.ListBuffer(1,2,3,4)
//> l2 : scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3, 4)
//通过下标操作List
l1(0) //> res0: Int = 1
//List转Array
val a1=l1.toArray //> a1 : Array[Int] = Array(1, 2, 3, 4)
//map:映射方法。根据匿名函数规则,将元素从一个形式映射(改变)到另外一个形式
//并将映射后的数据返回到一个新的集合中
val r1=l1.map { num => num*2 } //> r1 : List[Int] = List(2, 4, 6, 8)
val r2=l1.map { num => num.toString } //> r2 : List[String] = List(1, 2, 3, 4)
val l3=List("tom 23","rose 18","jim 30") //> l3 : List[String] = List(tom 23, rose 18, jim 30)
//练习1:对l3映射,返回的新集合 List("tom","rose","jim")
val r3=l3.map { line => line.split(" ")(0) } //> r3 : List[String] = List(tom, rose, jim)
//练习2:计算出l3中所有人的年龄的均值
val r4=l3.map { line => line.split(" ")(1).toInt }
//> r4 : List[Int] = List(23, 18, 30)
val r5=r4.sum.toDouble/r4.length //> r5 : Double = 23.666666666666668
val l4=List("hello world","hello 2005","hello world")
//> l4 : List[String] = List(hello world, hello 2005, hello world)
val r6=l4.map { line => line.split(" ") } //> r6 : List[Array[String]] = List(Array(hello, world), Array(hello, 2005), A
//| rray(hello, world))
//扁平化映射
val r7=l4.flatMap{ line => line.split(" ")} //> r7 : List[String] = List(hello, world, hello, 2005, hello, world)
val l5=List(2,1,5,3,4) //> l5 : List[Int] = List(2, 1, 5, 3, 4)
//sortBy:根据指定的匿名函数规则实现排序。下面表示按数字做升序排序
//将排序后的结果返回到新的集合中
val r8=l5.sortBy { num => num } //> r8 : List[Int] = List(1, 2, 3, 4, 5)
//通过翻转实现降序排序
val r9=l5.sortBy { num => num }.reverse //> r9 : List[Int] = List(5, 4, 3, 2, 1)
//使用负号,仅限于数值类型,不能作用于String。注意前面留空格
val r10=l5.sortBy { num => -num } //> r10 : List[Int] = List(5, 4, 3, 2, 1)
val l6=List("tom","rose","smith") //> l6 : List[String] = List(tom, rose, smith)
//如果是String类型,则按字典序排序
val r11=l6.sortBy { name => name } //> r11 : List[String] = List(rose, smith, tom)
//练习3:对l7按年龄做升序排序
val l7=List("tom M 23","rose F 18","jim M 30","jary M 25")
//> l7 : List[String] = List(tom M 23, rose F 18, jim M 30, jary M 25)
val r12=l7.sortBy { line => line.split(" ")(2).toInt }
//> r12 : List[String] = List(rose F 18, tom M 23, jary M 25, jim M 30)
//练习4:求出l7男性年龄最大的前两个人的年龄差
val r13=l7.filter { line=>line.split(" ")(1).equals("M") }
.sortBy { line => -line.split(" ")(2).toInt }
.take(2)
.map { line => line.split(" ")(2).toInt }
//> r13 : List[Int] = List(30, 25)
val r14=r13.max-r13.min //> r14 : Int = 5
}
Array和List 通用且重要的方法
0.reverse
1.max
2.min
3.sum
4.length
5.take
6.takeRight
7.drop
8.dropRight
9.head
10.last
11.union
12.intersect
13.diff
14.distinct
15.mkString 我发现如果调用的方法只有一个参数,则小括号可以用大括号代替
16.filter 就是在方法体中通过匿名函数告诉该方法哪些数据该要(返回true的)哪些数据不该要(返回false的)
17.map 就是在方法体中通过匿名函数告诉该方法每一个数据要转变成什么样子
18.flatMap
19.sortBy 就是想办法在方法体中告诉该方法这些数据该怎么排序
20.groupBy
21.foreach
**重点掌握:**①filter ②map ③flatMap ④sortBy ⑤groupBy
Map映射
其实遍历出来的每一个元素都可以看作是是一个元组,只不过该元组有两个元素,一个是key,一个是value
/**
我发现如果匿名函数中使用到了case,就必须要用{}不能用(),而且如果调用的函数的参数有多个参数,是不能用{}的
*/
object Demo04 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
//创建一个定长Set
val s1=Set(1,1,2,2,3) //> s1 : scala.collection.immutable.Set[Int] = Set(1, 2, 3)
//创建一个变长Set
val s2=scala.collection.mutable.Set(1,2,3) //> s2 : scala.collection.mutable.Set[Int] = Set(1, 2, 3)
//创建一个定长Map
val m1=Map("tom"->18,"rose"->23) //> m1 : scala.collection.immutable.Map[String,Int] = Map(tom -> 18, rose -> 23
//| )
//创建一个变长Map,可以追加kv对
val m2=scala.collection.mutable.Map("tom"->18)
//> m2 : scala.collection.mutable.Map[String,Int] = Map(tom -> 18)
//通过key获取对应的value,apply方法可以省略
m1.apply("tom") //> res0: Int = 18
m1("tom") //> res1: Int = 18
//获取所有key,可以转变为Array或List进行后续的操作
m1.keys.toList //> res2: List[String] = List(tom, rose)
//获取所有value
m1.values.toList //> res3: List[Int] = List(18, 23)
//通过for循环遍历map
for(i<-m1){
println(i) //> (tom,18)
//| (rose,23)
}
for((k,v)<-m1){
println(k) //> tom
//| rose
}
//练习1:通过for yield构建满足要求的新Map。
val m3=Map("book"->10,"gun"->100,"ipad"->1000)
//> m3 : scala.collection.immutable.Map[String,Int] = Map(book -> 10, gun -> 10
//| 0, ipad -> 1000)
val m4=for((k,v)<-m3)yield{(k,v*0.9)} //> m4 : scala.collection.immutable.Map[String,Double] = Map(book -> 9.0, gun -
//| > 90.0, ipad -> 900.0)
//对变长Map追加kv对
m2+=("jim"->20,"jary"->25) //> res4: Demo04.m2.type = Map(jary -> 25, jim -> 20, tom -> 18)
val m5=Map("bj"->12000,"sh"->8000,"gz"->9000,"sz"->11000)
//> m5 : scala.collection.immutable.Map[String,Int] = Map(bj -> 12000, sh -> 80
//| 00, gz -> 9000, sz -> 11000)
//使用filter:过滤出m5薪资大于10000的数据
val r1=m5.filter{case(k,v)=>v>10000} //> r1 : scala.collection.immutable.Map[String,Int] = Map(bj -> 12000, sz -> 11
//| 000)
//使用map:对薪资映射,每个地区的薪资+5000
val r2=m5.map{case(k,v)=>(k,v+5000)} //> r2 : scala.collection.immutable.Map[String,Int] = Map(bj -> 17000, sh -> 13
//| 000, gz -> 14000, sz -> 16000)
//如果对Map类型,只对Map的value做映射,可以使用mapValues方法
val r3=m5.mapValues { value => value+5000 }
//> r3 : scala.collection.immutable.Map[String,Int] = Map(bj -> 17000, sh -> 1
//| 3000, gz -> 14000, sz -> 16000)
}
Tuple元组
object Demo05 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
//创建一个元组 Tuple
val t1=(5,2,1) //> t1 : (Int, Int, Int) = (5,2,1)
val t2=("hello",1,Array(1,2,3),List(3,4)) //> t2 : (String, Int, Array[Int], List[Int]) = (hello,1,Array(1, 2, 3),List(3,
//| 4))
//元组的取值: ._下标 元组的下标从1开始
t1._1 //> res0: Int = 5
t2._3 //> res1: Array[Int] = Array(1, 2, 3)
val t3=(1,2,(3,4)) //> t3 : (Int, Int, (Int, Int)) = (1,2,(3,4))
//取出t3中的数字4
t3._3._2 //> res2: Int = 4
val t4=(1,2,(3,4),(5,(Array(6,7)))) //> t4 : (Int, Int, (Int, Int), (Int, Array[Int])) = (1,2,(3,4),(5,Array(6, 7))
//| )
//取出t4中的数字6
t4._4._2.head //> res3: Int = 6
t4._4._2(0) //> res4: Int = 6
val m1=Map("tom"->23,"rose"->18) //> m1 : scala.collection.immutable.Map[String,Int] = Map(tom -> 23, rose -> 18
//| )
val r1=m1.filter{case(k,v)=>v>20} //> r1 : scala.collection.immutable.Map[String,Int] = Map(tom -> 23)
val r2=m1.filter{x=>x._2>20} //将每一个看成一个元组 //> r2 : scala.collection.immutable.Map[String,Int] = Map(tom -> 23)
//练习:m1 使用map映射。 key不变,value+10岁。使用元组的操作形式来完成
val r3=m1.map{case(k,v)=>(k,v+10)} //> r3 : scala.collection.immutable.Map[String,Int] = Map(tom -> 33, rose -> 28
//| )
val r4=m1.map{x=>(x._1,x._2+10)} //> r4 : scala.collection.immutable.Map[String,Int] = Map(tom -> 33, rose -> 28
//| )
}
综合练习
object Demo06 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
val l1=List(("tom",23,"M"),("rose",18,"F"),("jim",30,"M"),("jary",25,"M"))
//> l1 : List[(String, Int, String)] = List((tom,23,M), (rose,18,F), (jim,30,M)
//| , (jary,25,M))
//练习1:操作l1,返回一个新的集合 List("tom","rose","jim","jary")
val r1=l1.map{x=>x._1} //> r1 : List[String] = List(tom, rose, jim, jary)
//练习2:操作l1,按年龄做降序排序
val r2=l1.sortBy{x=> -x._2} //> r2 : List[(String, Int, String)] = List((jim,30,M), (jary,25,M), (tom,23,M)
//| , (rose,18,F))
val r3=l1.sortBy{case(name,age,gender)=> -age} //> r3 : List[(String, Int, String)] = List((jim,30,M), (jary,25,M), (tom,23,M)
//| , (rose,18,F))
//练习3:求出男性最大年龄与最小年龄的差
val r4=l1.filter{x=>x._3.equals("M")}
.map{x=>x._2} //> r4 : List[Int] = List(23, 30, 25)
val r5=r4.max-r4.min //> r5 : Int = 7
val l2=List("hello","hello","world","2005","world")
//> l2 : List[String] = List(hello, hello, world, 2005, world)
//groupBy 按照指定匿名函数规则分组
val r6=l2.groupBy { word => word } //> r6 : scala.collection.immutable.Map[String,List[String]] = Map(2005 -> List
//| (2005), world -> List(world, world), hello -> List(hello, hello))
val l3=List(("bj",1),("sh",2),("bj",3),("sh",4))//> l3 : List[(String, Int)] = List((bj,1), (sh,2), (bj,3), (sh,4))
//练习4:操作l3,按地区分组
val r7=l3.groupBy{x=>x._1} //> r7 : scala.collection.immutable.Map[String,List[(String, Int)]] = Map(bj ->
//| List((bj,1), (bj,3)), sh -> List((sh,2), (sh,4)))
//练习5:统计l4中的单词频次
//Map(hello->3,world->2,scala->1)
val l4=List("hello world","hello scala","hello world")
//> l4 : List[String] = List(hello world, hello scala, hello world)
val r8=l4.flatMap{line=>line.split(" ")}
.groupBy{word=>word}
.map{case(k,v)=>(k,v.length)}
.toList //> r8 : List[(String, Int)] = List((scala,1), (world,2), (hello,3))
}
类
知识点:
- 1.scala 通过class来声明类。可以拥有成员变量和成员方法
- 2.scala class 通过new来创建类的对象
- 3.可以通过private 或 protected来修饰成员变量。什么都不加,默认是public
- 4.scala class 有一个主构造器和多个辅助构造器
- 5.主构造器只有一个,在类上声明
- 6.辅助构造器可以有多个,在类里声明。辅助器方法体中必须调用本类的其他构造器(一般都是调用主构造器)
- 7.scala class 支持类的继承以及方法的重写。通过extends 关键字来继承
- 重写方法时,如果是一个普通方法,则需要加override关键字
- 如果重写的是抽象方法,则不需要加override关键字
- 8.scala也有抽象类,通过abstract关键字来定义
- 9.抽象方法没有方法体
- 10.scala也有接口,称为trait(特质)
- 11.scala使用with关键字来混入特质
- 12.scala是单继承多混入
- 13.scala的trait 既可以写抽象方法,也可以写普通方法。这种机制可以使得scala的class实现多继承的效果
- 14.scala的class在继承或混入时,必须有且仅有一个extends关键字
- 15.scala没有static关键字。如果要实现静态机制,需要使用Object 单例对象类
- 16.在Object中的成员变量和成员方法都是静态的。
- 17.object单例对象类不能new
- 18.如果要为一个class添加静态成员或静态方法,规则:在class的同文件下,
- 写一个同名的object。然后在object中添加静态成员或方法即可
- 则此时,class和object之间产生了伴生关系。
- class是object的伴生类
- object是class的伴生对象
- 19.因为main方法是静态方法,所以main必须写在object中才能启动运行
创建一个普通类
class People(v1:String,v2:Int) {
private var name=v1
private var age=v2
/*
* 一个辅助构造器,只接受姓名
*/
def this(v1:String){
this(v1,0)
}
/*
* 再写两个辅助构造器,一个是只接受年龄的。另一个是空构造器
*
*/
def this(v2:Int){
this("",v2)
}
def this(){
this("",0)
}
def setName(name:String)={
this.name=name
}
def getName()={
this.name
}
def setAge(age:Int)={
this.age=age
}
def getAge()={
this.age
}
def speak()={
println("hello")
}
}
object People{
def say()={
}
}
样例类
- 知识点
- 1.case class 样例类。要求必须显式的声明主构造器
- 2.case class 直接通过主构造器传参。不需要额外写get和set方法
- 3.case class 不需要new就可以创建类的对象
- 4.case class 默认会构造一个空的辅助构造器
- 5.case class 默认会生成字段toString方法,便于打印输出
- 6.case class 默认混入了序列化特质
- 综上,后续封装bean习惯上使用case class
case class Item(title:String,price:Double) {}
实现继承
class Student extends People{
//重写普通方法,必须加override
override def speak()={
println("1234")
}
}
抽象类
abstract class Teacher {
//抽象方法
def makeNote(note:String):String
//抽象方法
def teach():Unit
//普通方法
def say()={
}
}
Object 单例对象类
//Object 单例对象类 里边的成员变量和成员方法都是静态的
object Util {
def sleep()={
}
//alt+/
def main(args: Array[String]): Unit = {//必须要在Object类里边
val a1=Array(1,2,3,4)
a1.foreach { num => println(num) }
}
}
定义特质 trait
trait Dance {
def balei():String
def tita():Int
}
-----------------------------------------
trait Drive {
//包含抽象方法
def start():Int
def piaopi():String
//可以有普通方法
def stop()={
}
}
混入特质
//ctrl+1 混入特质
class ZhangTeacher extends Dance with Drive with Serializable{
def makeNote(note: String): String = {
println("make Note")
"note"
}
def teach(): Unit = {
println("hello")
}
def balei(): String = {
???
}
def tita(): Int = {
???
}
def piaopi(): String = {
???
}
def start(): Int = {
???
}
}
对上述定义的类中的方法和变量进行综合调用
object Demo07 {
println("Welcome to the Scala worksheet") //> Welcome to the Scala worksheet
val p1=new People("tom",23) //> p1 : People = People@3b6eb2ec
p1.getName() //> res0: String = tom
p1.getAge() //> res1: Int = 23
p1.speak() //> hello
val p2=new People("rose") //> p2 : People = People@3f3afe78
val p3=new People(23) //> p3 : People = People@7f63425a
val p4=new People //调用无参的可以不加() //> p4 : People = People@36d64342
Util.sleep()
People.say()
val item1=Item("huawei",2000) //不需要new就可以创建类的对象 //> item1 : Item = Item(huawei,2000.0)
item1.title //> res2: String = huawei
item1.price //> res3: Double = 2000.0
println(item1) //> Item(huawei,2000.0)
val item2=Item //> item2 : Item.type = Item
}
懒值 demo09中
scala懒值及使用lazy关键字来修饰。