self-attention详解与计算过程
self-attention学习笔记
- 一、问题的提出
- 二、改进
- 三、问题又来了
- 四、self-attention的提出
-
- 1.self-attention的输入输出
- 2.self-attention可以叠加使用
- 五、self-attention的结构
-
- 1、大致结构
- 六、输出向量计算步骤
-
- 1、第一步:找出输入向量的关系
- 2、第二步:计算输入向量之间的关系
- 3、第三步 通过关系生成4个向量
- 4、第四步 送入soft-max函数
- 5、第五步 生成第一个输出向量b1
一、问题的提出
在NLP中词是以一个向量的形式传入的,在进行推理过程中如果单纯的一个一个推理,对于机器翻译来说这是不可取的,比如 I saw a saw 在这里两个saw就是不同的意思,当这两个词以向量的形式传入,得到的结果当然是一样的,这肯定是不行的

二、改进
为了解决这个问题,应该把前后网络之间给连接起来,增加词与词的关联性
每一个词与前后的词都具有关联性

三、问题又来了
如果某一个词要考虑整个句子,那么我们是不是要把整个范围联结起来呢,我们知道,每个句子的长度都是不一样的,而且这个联结不能太长,太长的话会带来大量的参数以及运算,于是我们提出了self-attention
四、self-attention的提出
1.self-attention的输入输出
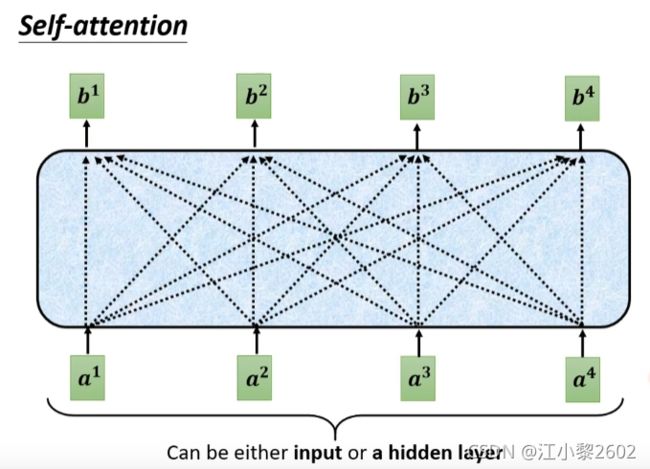
如图 输入4个向量,输出4个向量,每一个向量都是考虑4个输入向量后得到的,也就是说,输出的向量都考虑到了所有的输入向量
如图所示

2.self-attention可以叠加使用
如图所示

五、self-attention的结构
1、大致结构
输入向量:a1、a2、a3,a4
输出向量: b1、b2、b3、b4
箭头的意思就是关联性
可以看出b1是在考虑了a1、a2、a3,a4后得出来的,同理可得,b2、b3、b4也是这样
六、输出向量计算步骤
1、第一步:找出输入向量的关系
首先找出a1与其他输入向量的关系,因为在语义中前文和后文是有较强的联结性的,如图

2、第二步:计算输入向量之间的关系
在这里有两种方式进行计算
第一种叫Dot-product
按照图中的模板,输入两个向量(绿色方块)分别将两个向量乘以 W q W^{q} Wq和 W k W^{k} Wk权重然后分别得到q和k,最后两个相乘得到两者的关系参数α,这种方式也是比较常用的
第二种叫Additive
结合第一种的运算可以看出第二种的运算,相加后送入了tanh函数最后再乘以一个权重w

接下来看看再整体网络上的计算
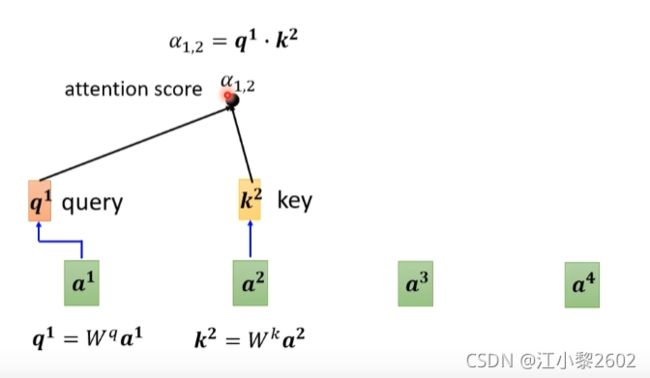
在计算a1和其他部分的关系的时候
a1叫做 query
a2叫做 key
在上文中提到的计算
q1 = W q a 1 W^{q}a^{1} Wqa1
k2 = W k a 2 W^{k}a^{2} Wka2
最后得到 a 1 , 2 a_{1,2} a1,2 = q1*k2
a 1 , 2 a_{1,2} a1,2又称为attention score
3、第三步 通过关系生成4个向量
由上文可以可得到4个attention score
值得注意的是这里有一个求自己关联度的出现了a1和a1计算关系参数
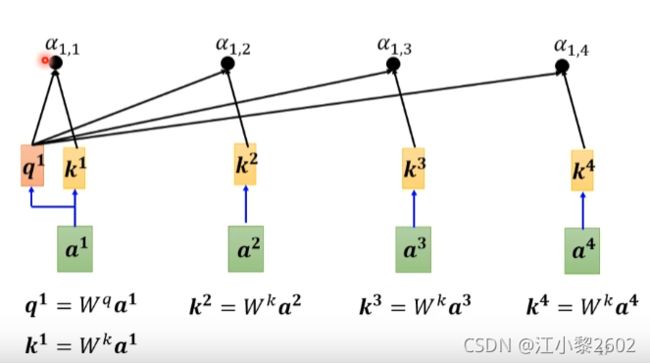
得到了这4个向量
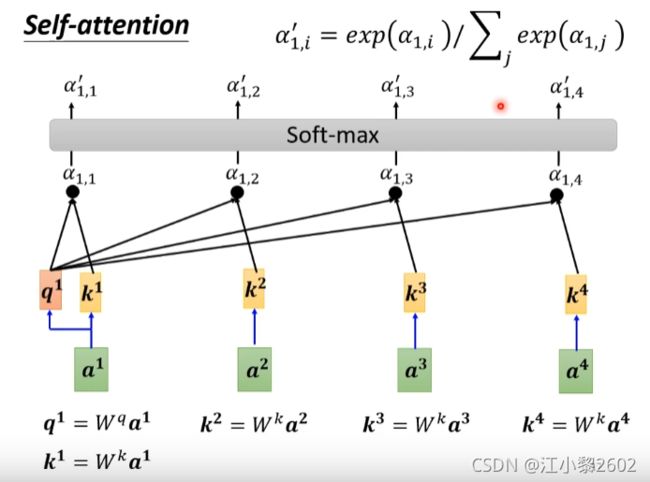
4、第四步 送入soft-max函数
接下来把4个向量送入softmax函数,当然也不是说一定要softmax函数,也可以是其他函数,如果你发现更好的函数可以代替,效果更好也是可以的。
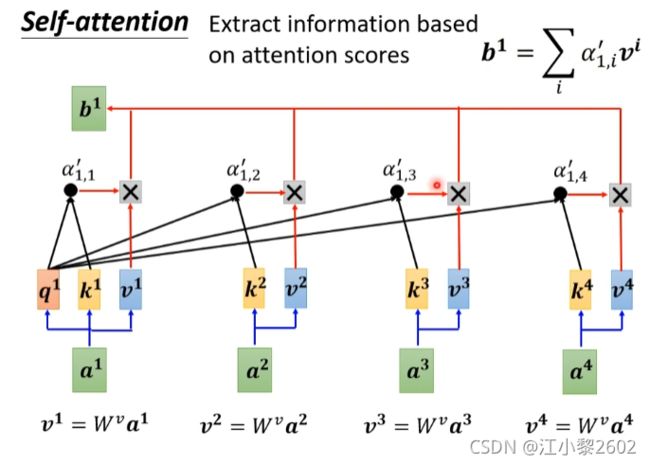
5、第五步 生成第一个输出向量b1
如图,经过soft-max函数后生成 a 1 , 1 ‘ , a 1 , 2 ‘ , a 1 , 3 ‘ , a 1 , 4 ‘ a_{1,1}^{`} , a_{1,2}^{`},a_{1,3}^{`},a_{1,4}^{`} a1,1‘,a1,2‘,a1,3‘,a1,4‘ 4个向量
引入权重 W v W^{v} Wv
构建新的向量v1,v2,v3,v4
v1 = W v a 1 W^{v}a^{1} Wva1
分别将v1、v2,v3,v4与 a 1 , 1 a_{1,1} a1,1 a 1 , 2 a_{1,2} a1,2 a 1 , 3 a_{1,3} a1,3 a 1 , 4 a_{1,4} a1,4相乘
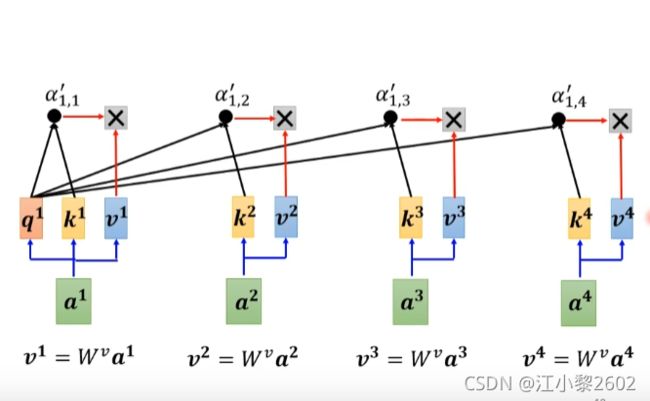
最后相加就得到了b1