基于AlexNet、VGGnet和GoogleNet的图像检索
卷积神经网络(CNN)基础
卷积神经网络(CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,它仿造生物的视觉神经元机制构建,能够进行监督学习和非监督学习,是深度学习网络的代表之一。卷积神经网络具有特征学习能力,能够按其阶层结构对输入信息进行平移不变分类,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的参数来进行特征处理。
一个卷积神经网络主要由以下5种结构组成:
输入层:输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。
卷积层:卷积层试图将神经网络中的每一个小块进行更加深入的分析从而得到抽象程度更高的特征。
池化层:池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而达到减少整个神经网络中的参数的目的。
线性整流层(激活层):激活层把卷积、池化层的输出结果做非线性映射。卷积神经网络采用的激活函数一般为ReLU,它的特点是收敛快,求取梯度较为简单。
全连接层:全连接层在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征映射到样本标记空间的作用。
图片检索系统设计与实现
图片检索系统结构共分为三部分,第一部分为网络训练部分,第二部分为特征提取部分,第三部分则是特征对比结果输出部分。以上三部分实现步骤如下图所示。
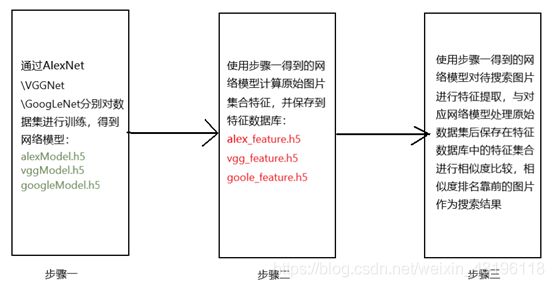
基于AlexNet的图像检索
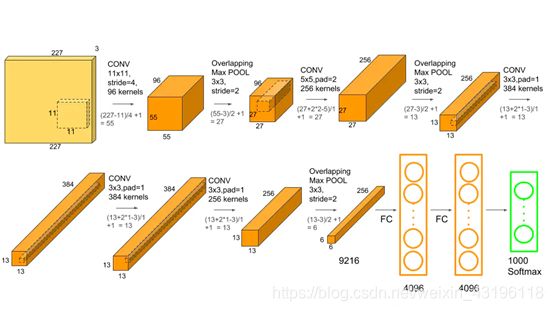
AlexNet网络结构在整体上类似于LeNet,都是先卷积然后再全连接,但与LeNet相比,AlexNet更为复杂。AlexNet使用了GPU进行运算加速,并在卷积神经网络中成功应用了ReLU、dropout和LRN等结构。总的来说,AlexNet网络包括5个卷积层和3个全连接层,在每一个卷积层中包含了激活函数RELU以及局部响应归一化(LRN)处理,然后再经过下采样(pool处理)。AlexNet网络结构如图所示。
使用Keras实现AlexNet网络架构,源码如下。
# AlexNet网络结构
model = Sequential()
model.add(Conv2D(96, (11, 11), strides=(4, 4),
input_shape=(227, 227, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2)))
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
sgd = optimizers.Adam(lr=0.00001)
model.compile(loss='sparse_categorical_crossentropy',
optimizer=sgd, metrics=['accuracy'])
在AlexNet网络训练结束并生成alexModel.h5模型后,使用命令:python index.py -database train/cat -index alex_feature.h5计算cat数据集中的图片特征并存储在alex_feature.h5中,然后使用命令:query_online.py -query cat.1.jpg -index alex_feature.h5 -result train/cat检索图片(检索路径为:train/cat),返回与目标图片train/cat/cat.1.jpg最为相似的三张图片。返回结果如图所示。

基于VGG的图像检索
VGGNet提出了相对AlexNet更深的网络模型。通过实验发现,在一定程度上网络结构的层数越深性能越好,VGGNet通过反复堆叠33的小型卷积核和22的最大池化层,成功地构筑了16~19层更深的卷积神经网络。VGGNet的网络结构(11层到19层)如图所示。
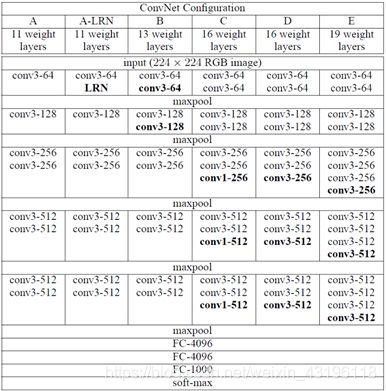
相比于AlexNet,VGGNet在AlexNet的基础上做出了如下改进:
VGGNet去掉了LRN层,因为作者发现随着深度的加深,网络中LRN层的作用逐渐变得不再明显。
VGGNet采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核,采用连续的小卷积核加深网络是优于采用大的卷积核的,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且对应的参数量还比较小。
VGGNet使用更小的2x2池化核,而Alexnet池化核大小为3x3。
由于VGGNet基于Alexnet做出了以上改进,使得网络性能得到了提高,但VGGNet也耗费了大量的计算资源,这种资源耗费主要在于第一个全连接层使用的大量参数。
使用Keras实现VGGNet-19网络架构,VGGNet-19源码实现如下所示。
# VGGNet19网络模型
size = 224
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(size, size, 3)))
model.add(BatchNormalization())
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(Conv2D(128, (3, 3), padding='same'))
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(Conv2D(256, (3, 3), padding='same'))
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(Conv2D(512, (3, 3), padding='same'))
model.add(MaxPooling2D((2, 2), strides=2))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(1024, activation='relu'))
model.add(Dense(1000, activation='softmax'))
使用VGGNet网络结构训练并生成vggModel.h5模型后,使用命令:python index.py -database train/cat -index vgg_feature.h5计算cat数据集中的图片特征并存储在vgg_feature.h5中,然后使用命令:query_online.py -query cat.1.jpg -index vgg_feature.h5 -result train/cat检索图片,返回与目标图片cat.1.jpg最为相似的三张图片。返回结果如图所示。

基于GoogLeNet的图像检索
GoogLeNet是2014年Christian Szegedy提出的一种新的深度学习结构,在这之前的AlexNet、VGGNet等结构都是通过增大网络的深度来获得更好的训练效果,但层数的增加会带来很多负面影响,比如梯度消失、梯度爆炸等。GoogLeNet有6个经典版本:GoogLeNet-v1、GoogLeNet-v2、GoogLeNet-v3、GoogLeNet-v4、Inception-Resnet-v1和Inception-Resnet-v2。
GoogLeNet-v1基于Inception-v1,网络结构如图2-8所示。其中, Inception-v1 结构的基本组成有四个成分:11卷积核,33卷积核,55卷积核,33最大池化,如图2-9中Figure 4所示。GoogLeNet-v2将Inception-v1替换为Inception-v2,Inception-v2在Inception-v1的基础上,使用小的卷积核替代大的卷积核,这一思想受到VGGNet的启发。Inception-v2在训练达到Inception-v1的准确率时可以提速近14倍,并且模型在收敛时的准确率上限更高。Inception-v2结构如图2-9中Figure 5所示。此外,GoogLeNet-v2还在网络中加入了BN层,使每一层的输出都规范化到一个N(0, 1)的高斯分布中。相比于GoogLeNet-v1和GoogLeNet-v2版本,GoogLeNet-v3版本的最重要的改进是分解。GoogLeNet-v3引入了Factorization into small convolutions的思想,将一个较大的二维卷积拆成两个较小的一维卷积,比如将77卷积拆成17卷积和71卷积,或者将33卷积拆成13卷积和31卷积,这种分解一方面节约了大量参数,加速运算并减轻了过拟合,另一方面增加了一层非线性扩展模型表达能力。Inception-v3结构如图2-9中Figure 6所示。GoogLeNet-v4基本延续了Inception v2和v3的结构,而与v4同时发布的Inception-Resnet-v1和Inception-Resnet-v2在之前的版本基础上,吸收了ResNet的优点,并对Inception块的每个网格尺寸进行了统一。GoogLeNet-v4的整体架构如图2-10所示。Inception-Resnet-v1和Inception-Resnet-v2结构如图2-11所示。
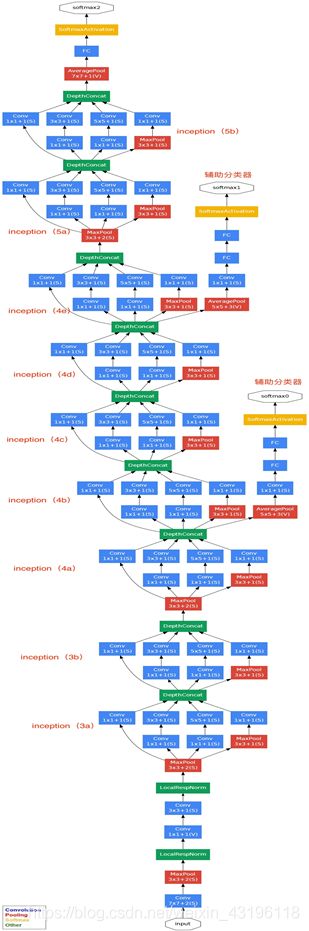
图2 8 GoogLeNet网络结构
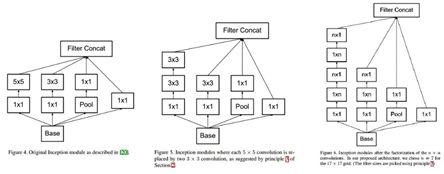
图2 9 从Inception-v1到Inception-v3
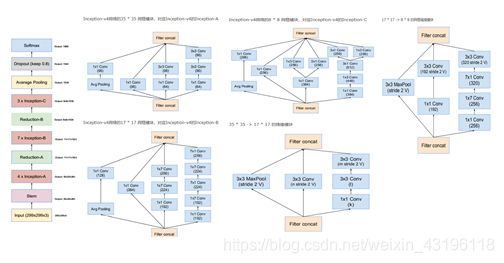
图2 10 GoogLeNet-v4整体结构
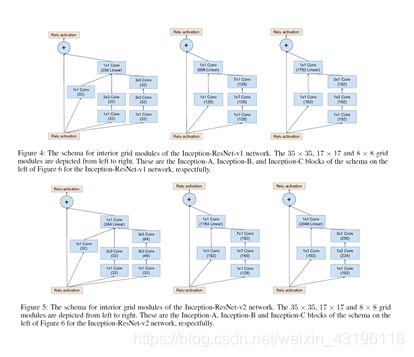
图2 11 Inception-Resnet-v1和Inception-Resnet-v2基本模块
GoogLeNet-v1具有以下特点:
采用模块化结构(Inception模块),方便网络的修改,并且,Inception结构能够提取图像不同尺度的信息并融合,从而得到图像中更好的特征。
采用Network in Network中用Average pool来代替全连接层的思想。事实证明,Average pool来代替全连接层可以将准确率提高0.6%左右。
增加了两个辅助的softmax分支,这两个辅助的softmax分支作用有两点,一是为了避免梯度消失,用于向前传导梯度。二是将中间某一层输出用作分类,起到模型融合的作用。
GoogLeNet-v2具有以下特点:
汲取VGGNet的优点,用两个33卷积代替55卷积,降低了参数量。
提出BN算法。BN算法是一个正则化方法,可以提高大网络的收敛速度。简单介绍一下BN算法。就是对输入层信息分布标准化处理,使得规范化为N(0,1)的高斯分布,收敛速度大大提高。
GoogLeNet-v3具有以下特点:
学习Factorization into small convolutions的思想,将一个二维卷积拆分成两个较小卷积,例如将77卷积拆成17卷积和7*1卷积。这样做的好处是降低参数量。并且,这种非对称的卷积拆分比对称的拆分为几个相同的卷积效果更好,可以处理更多,更丰富的空间特征。
Inception-ResNet-v1和Inception-ResNet-v2具有以下特点:
结合了ResNet和GoogLeNet的优点,使网络在识别精度和训练速度上都有了很大的提升。
使用Keras实现GoogLeNet-v2网络架构,GoogLeNet-v2源码实现如下所示。
class GoogLeNet:
@staticmethod
def conv_module(x, K, kX, kY, stride, chanDim, padding="same"):
# x表示输入数据,K表示conv的filter的数量,KX,KY表示kernel_size
x = Conv2D(K, (kX, kY), strides=stride, padding=padding)(x)
x = BatchNormalization(axis=chanDim)(x)
x = Activation("relu")(x)
# return the block
return x
@staticmethod
def inception_module(x, numK1_1, numK3_3, chanDim):
# x表示输入数据,numK1_1,numK3_3表示kernel的filter的数量
conv1_1 = GoogLeNet.conv_module(x, numK1_1, 1, 1, (1, 1), chanDim)
conv3_3 = GoogLeNet.conv_module(x, numK3_3, 3, 3, (1, 1), chanDim)
# 将conv1_1和conv3_3串联到一起
x = concatenate([conv1_1, conv3_3], axis=chanDim)
return x
@staticmethod
def downsample_module(x, K, chanDim): # K表示conv的filter的数量
conv3_3 = GoogLeNet.conv_module(x, K, 3, 3, (2, 2), chanDim,
padding='valid')
pool = MaxPooling2D((3, 3), strides=(2, 2))(x)
# 将conv3_3和maxPooling串到一起
x = concatenate([conv3_3, pool], axis=chanDim)
return x
@staticmethod
def build(width, height, depth, classes):
inputShape = (height, width, depth) # keras默认channel last,tf作为backend
chanDim = -1
# if we are using "channels first", update the input shape
# and channels dimension
if K.image_data_format() == "channels_first":
inputShape = (depth, height, width)
chanDim = 1
# define the model input and first CONV module
inputs = Input(shape=inputShape)
x = GoogLeNet.conv_module(inputs, 96, 3, 3, (1, 1), chanDim)
# two Inception modules followed by a downsample module
x = GoogLeNet.inception_module(x, 32, 32, chanDim) # 第一个分叉
x = GoogLeNet.inception_module(x, 32, 48, chanDim) # 第二个分叉
x = GoogLeNet.downsample_module(x, 80, chanDim) # 第三个分叉,含有maxpooling
# four Inception modules followed by a downsample module
x = GoogLeNet.inception_module(x, 112, 48, chanDim)
x = GoogLeNet.inception_module(x, 96, 64, chanDim)
x = GoogLeNet.inception_module(x, 80, 80, chanDim)
x = GoogLeNet.inception_module(x, 48, 96, chanDim)
x = GoogLeNet.downsample_module(x, 96, chanDim)
# two Inception modules followed by global POOL and dropout
x = GoogLeNet.inception_module(x, 176, 160, chanDim)
x = GoogLeNet.inception_module(x, 176, 160, chanDim)
x = AveragePooling2D((7, 7))(x)
x = Dropout(0.5)(x)
# classifier
x = Flatten()(x) # 特征扁平化
x = Dense(classes)(x)
x = Activation("sigmoid")(x)
# create the model
model = Model(inputs, x, name="googlenet")
# return the constructed network architecture
return model
在GoogLeNet网络训练结束并生成googleModel.h5模型后,使用命令:python index.py -database train/cat -index goole_feature.h5计算cat数据集中的图片特征并存储在goole_feature.h5中,然后使用命令:query_online.py -query cat.28.jpg -index goole_feature.h5 -result train/cat检索图片(检索路径为:train/cat),返回与目标图片train/cat/cat.28.jpg最为相似的三张图片。返回结果如图所示。

总结
本次实验使用AlexNet网络模型的第14层进行特征提取得到的搜索效果最好,不论是使用图像翻转、移位还是尺寸变化后的图片进行检索,都可以将原始图片检索出来。其次,VggNet的检索效果也比较好,本次课题研究使用VggNet第24层进行特征提取,没有达到imagenet-vgg-verydeep-19.mat的效果,但也能在相似度排名前三的位置检索到原始图片。然后,使用GoogleNet网络模型第73层进行特征提取,使用图像移位和尺寸变化后的图片进行图片检索,能够检索到原始图片,但对翻转图片的检索效果有待提升。
由于神经网络结构中每一层提取的特征都具有一定的差异,想要将检索效果达到最好,需要基于理论不断尝试。在本次课题研究基础上,通过优化特征提取方式,可以进一步优化检索系统,不仅如此,在更为复杂的视频检索等领域,进行高速、可靠的检索也是可行的。
参考文献
[1] 张俊. 基于AlexNet融合特征的图像检索研究[D]. 2016.
[2] Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
[3] Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning[J]. 2016.
[4] Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the Inception Architecture for Computer Vision[C]// IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 2016:2818-2826.
[5] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[6] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. 2016