【土堆 pytorch实战】P22神经网络搭建
P22搭建CIFAR-10
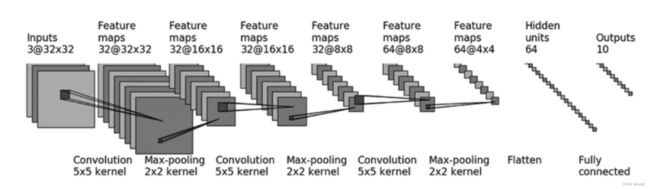
卷积层1:输入H=32,kernel_size=5,dilation=1 输出H=32,代入公式得 32 = 32 + 2 ∗ p a d d i n g − 4 − 1 s t r i d e + 1 32=\frac{32+2*padding-4-1}{stride}+1 32=stride32+2∗padding−4−1+1,所以当stride=1时,padding=2

from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1=Conv2d(3,32,5,padding=2)
self.maxpool1=MaxPool2d(2) #池化层默认的stride=kernel_size
self.conv2=Conv2d(32,32,5,1,padding=2)
self.maxpool2=MaxPool2d(2)
self.conv3=Conv2d(32,64,5,padding=2)
self.maxpool3=MaxPool2d(2)
self.flatten=Flatten()
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10)
def forward(self,x):
x=self.conv1(x)
x=self.maxpool1(x)
x=self.conv2(x)
x=self.maxpool2(x)
x=self.conv3(x)
x=self.maxpool3(x)
x=self.flatten(x)
x=self.linear1(x)
x=self.linear2(x)
return x
tudui=Tudui()
print(tudui)
- 使用Sequential 搭建网络
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,1,padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
tudui=Tudui()
print(tudui)
input=torch.ones((64,3,32,32))
output=tudui(input)
print(output.shape)
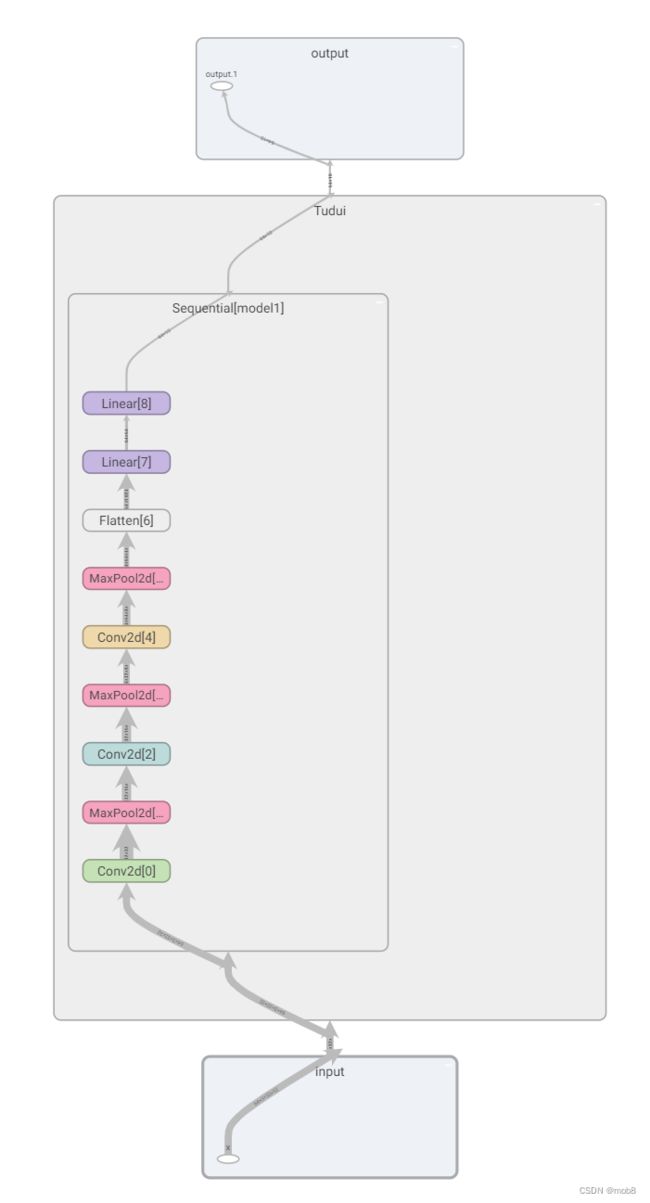
- 使用tensorboard显示
writer=SummaryWriter("logs_seq")
writer.add_graph(tudui,input)
writer.close()