2021-Channel and spatial attention based deep object co-segmentation论文阅读笔记
Introduction
输入任意大小;
孪生网络
编码器:DeeplabV3+resnet-50
通道注意操作对于增强包含公共对象特征的通道是必要的。平均池化+最大池化
高层特征提取语义,低层特征提取细节信息;
本文贡献:平均池化和最大池化都用于注意力机制;
将注意力机制也用于低层特征;
Related work
基于深度学习的协同分割论文
[34] P. Mukherjee, B. Lall, S. Lattupally, Object co-segmentation using deep siamese network, 2018, arxiv:1803.02555.
[21] W. Li, O.H. Jafari, C. Rother, Deep object co-segmentation, in: Asian Conference on Computer Vision, 2018, pp. 638–653.
[22] H. Chen, Y. Huang, H. Nakayama, Semantic aware attention based deep object co-segmentation, in: Asian Conference on Computer Vision, 2018, pp. 435–450.
[23] C. Wang, Z. Zha, D. Liu, H. Xie, Robust deep co-saliency detection with group semantic, in: Proc. AAAI Conf. on Artificial Intelligence, 2019, pp. 8917-8924.
[24] S. Banerjee, A. Hati, S. Chaudhuri, R. Velmurugan, CoSegNet: image co-segmentation using a conditional siamese convolutional network, in: Proc. Int. Joint Conf. Artif. Intell., 2019, pp. 673–679.
[25] B. Li, Z. Sun, Q. Li, Y. Wu, A. Hu, Group-wise deep object co-segmentation with co-attention recurrent neural network, in: Proc. Int. Conf. Comput. Vis., 2019, pp. 8519–8528.
[26] B. Li, Z. Sun, L. Tang, Y. Sun, J. Shi, Detecting robust co-saliency with recurrent co-attention neural network, in: Proc. Int. Joint Conf. Artif. Intell., 2019, pp. 818–825.
方法
方法包括三个主要部分:
(1)给定两个输入图像IA、IB,使用孪生Deeplab v3网络[28]作为主干架构,该架构基于ResNet-50网络。通过该网络,可以提取f high A、f high B的高级特征图。同时,还可以获得低层特征映射f low A、f low B。
(2)通道和空间注意模块对这些特征图进行处理,得到增强的特征图。相应的高级特征用F高A、F高B表示。相应的低级特征用F低A、F低B表示。
(3)增强的高级特征映射向前传播到解码器模块。通过向上采样,将它们恢复到与低级特征图相同的大小。我们将高级特征图和低级特征图中的上采样特征图连接起来,以弥补详细信息,并保持上采样操作以达到输入图像的原始大小。该模型为两幅图像输出两个掩码。
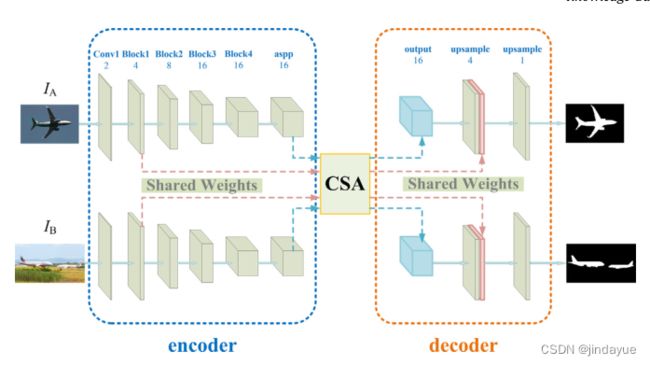
编码器
高层次特征图的分辨率降低到原来的1/16,而低层次特征图的分辨率降低到1/4。
注意力机制
在输入图像对中,相同类别的对象通过相同的编码网络在相同的特征通道中具有激活值。通道注意子模块关注两个特征映射的哪些公共通道被激活,并用相同的语义增强这些公共特征通道,并抑制其他通道。
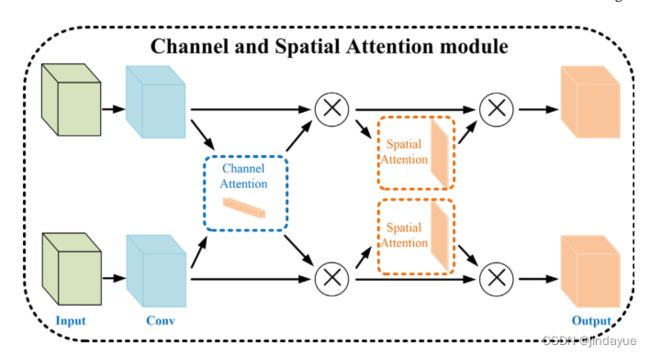
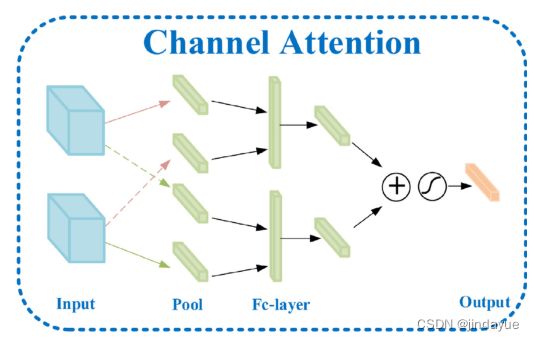
通道注意力机制原理

其中,AvgPch表示每个通道上的平均池操作,而MaxPch表示最大池。⊕ 表示通道轴上的串联操作。⊙ 表示第一项与第二项的每个通道进行元素乘法。σ是sigmoid函数。ν1和ν2表示完全连接层。
解码器
损失函数
标准的交叉熵损失函数
实验
数据:PASCAL VOC 2012
网络框架:tensorflow
指标:两个
精度(P)用于计算正确分割的前景和背景遮罩中所有像素的百分比。
Jaccard(J)是我们的联合分割结果和地面真值分割之间的交集。