【超分辨】SRGAN详解及其pytorch代码解释
SRGAN详解
- 介绍
- 网络结构
- 损失函数
- 数据处理
- 网络训练
介绍
有任何问题欢迎联系QQ:2487429219
SRGAN是一个超分辨网络,利用生成对抗网络的方法实现图片的超分辨。
关于生成对抗网络,后面我会专门发一篇博客讲解。
论文地址:http://arxiv.org/abs/1609.04802
本文代码传送门:https://github.com/zzbdr/DL/tree/main/Super-resolution/SRGAN
以下是原论文的效果展示:
顺带解释一下超分辨是什么:通俗来讲就是将尺寸小的图片变成尺寸大的图片,但是这和普通的图片缩放不一样,超分辨放大的图片保留的细节更多
网络结构
下面介绍SRGAN的网络结构,和其他对抗生成网络一样,SRGAN有生成网络和辨别网络,我们先看生成网络:
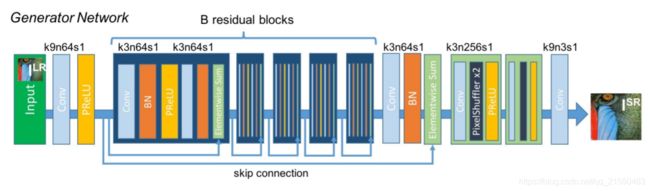
这是摘自原论文的网络结构图, 其中k代表卷积核的尺寸,n代表卷积输出的通道数,s代表步长,不同指向的箭头表示残差结构,Elementwise Sun就是残差中相加的操作。
相同颜色表示相同的操作,低分辨率图片(LR)输入网络后输出高分辨率图片(HR)。
下面来看辨别网络:
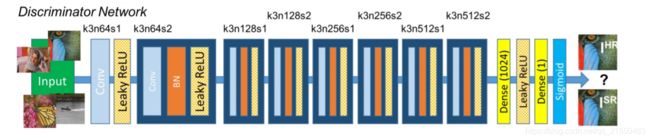
辨别网络没有残差结构,其中的符号表示的意思和上面解释的一样,辨别网络输入一张图片,判断这张图片是原始高分辨率的图片还是生成网络输出的高分辨率图片。
下面是pytorch代码:
简单实现残差结构
class Block(nn.Module):
def __init__(self, input_channel=64, output_channel=64, kernel_size=3, stride=1, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel),
nn.PReLU(),
nn.Conv2d(output_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel)
)
def forward(self, x0):
x1 = self.layer(x0)
return x0 + x1
生成网络
class Generator(nn.Module):
def __init__(self, scale=2):
"""放大倍数是scale的平方倍"""
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 9, stride=1, padding=4),
nn.PReLU()
)
self.residual_block = nn.Sequential(
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
Block(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
)
self.conv4 = nn.Conv2d(64, 3, 9, stride=1, padding=4)
def forward(self, x):
x0 = self.conv1(x)
x = self.residual_block(x0)
x = self.conv2(x)
x = self.conv3(x + x0)
x = self.conv4(x)
return x
辨别网络
class DownSalmpe(nn.Module):
def __init__(self, input_channel, output_channel, stride, kernel_size=3, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
x = self.layer(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.LeakyReLU(inplace=True),
)
self.down = nn.Sequential(
DownSalmpe(64, 64, stride=2, padding=1),
DownSalmpe(64, 128, stride=1, padding=1),
DownSalmpe(128, 128, stride=2, padding=1),
DownSalmpe(128, 256, stride=1, padding=1),
DownSalmpe(256, 256, stride=2, padding=1),
DownSalmpe(256, 512, stride=1, padding=1),
DownSalmpe(512, 512, stride=2, padding=1),
)
self.dense = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.down(x)
x = self.dense(x)
return x
运行测试
if __name__ == '__main__':
g = Generator()
a = torch.rand([1, 3, 64, 64])
print(g(a).shape)
d = Discriminator()
b = torch.rand([2, 3, 512, 512])
print(d(b).shape)
torch.Size([1, 3, 256, 256])
torch.Size([2, 1, 1, 1])
损失函数
SRGAN生成的网络损失函数为感知损失,由两部分组成content loss,和adversarial loss

content loss是生成的HR和真实的HR通过VGG网络前16层得到的特征之间的MSE损失,可以表示为:
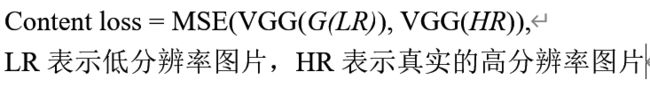
adversarial loss:
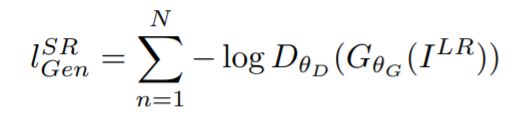
其中的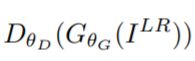 表示辨别器判断生成图片为真实的高分辨率图片的概率。
表示辨别器判断生成图片为真实的高分辨率图片的概率。
正则项:
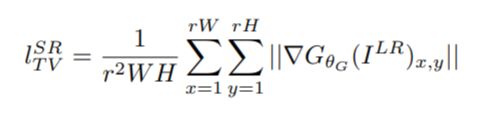
顺便一提,SRGAN目前提交了五个版本,自第三版开始,作者在论文中删除了正则项。
下面上代码:
content loss
import torch
import torch.nn as nn
import torchvision.models as models
class VGG(nn.Module):
def __init__(self, device):
super(VGG, self).__init__()
vgg = models.vgg19(True)
for pa in vgg.parameters():
pa.requires_grad = False
self.vgg = vgg.features[:16]
self.vgg = self.vgg.to(device)
def forward(self, x):
out = self.vgg(x)
return out
class ContentLoss(nn.Module):
def __init__(self, device):
super().__init__()
self.mse = nn.MSELoss()
self.vgg19 = VGG(device)
def forward(self, fake, real):
feature_fake = self.vgg19(fake)
feature_real = self.vgg19(real)
loss = self.mse(feature_fake, feature_real)
return loss
adversial loss
class AdversarialLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
loss = torch.sum(-torch.log(x))
return loss
上面两个加起来
class PerceptualLoss(nn.Module):
def __init__(self, device):
super().__init__()
self.vgg_loss = ContentLoss(device)
self.adversarial = AdversarialLoss()
def forward(self, fake, real, x):
vgg_loss = self.vgg_loss(fake, real)
adversarial_loss = self.adversarial(x)
return vgg_loss + 1e-3*adversarial_loss
正则项
class RegularizationLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
a = torch.square(
x[:, :, :x.shape[2]-1, :x.shape[3]-1] - x[:, :, 1:x.shape[2], :x.shape[3]-1]
)
b = torch.square(
x[:, :, :x.shape[2]-1, :x.shape[3]-1] - x[:, :, :x.shape[2]-1, 1:x.shape[3]]
)
loss = torch.sum(torch.pow(a+b, 1.25))
return loss
数据处理
将图片通过缩放操作放小作为低分辨率图片,原始图像作为真实的高分辨率图片,数据处理文件如下:
import os
from PIL import Image
from torchvision import transforms as tfs
def get_crop_size(crop_size, upscale=2):
return crop_size - (crop_size % upscale)
def input_transform(img, idx, boxes, crop_size, upscale_factor=2):
x1, y1, w, h = list(map(int, boxes[idx].strip().split()[1:]))
img = img.crop([x1, y1, x1+w, y1+h])
return tfs.Compose([
tfs.CenterCrop(crop_size),
tfs.Resize(crop_size // upscale_factor, interpolation=Image.BICUBIC)
])(img)
def target_transform(img, idx, boxes, crop_size):
x1, y1, w, h = list(map(int, boxes[idx].strip().split()[1:]))
img = img.crop([x1, y1, x1 + w, y1 + h])
return tfs.Compose([
tfs.CenterCrop(crop_size)
])(img)
def generate_data(row_path, save_path, file_path, upscale_factor=4, divide=0.95):
all_data = os.listdir(row_path)
data_length = 30000
train_stop = int(data_length * divide)
crop_size = get_crop_size(128, upscale_factor)
f = open(file_path)
boxes = f.readlines()[2:]
if not os.path.exists(os.path.join(save_path, "train")):
os.makedirs(os.path.join(save_path, "train"))
f_train = open(os.path.join(save_path, "train.txt"), "w")
if not os.path.exists(os.path.join(save_path, "val")):
os.makedirs(os.path.join(save_path, "val"))
f_val = open(os.path.join(save_path, "val.txt"), "w")
for t in range(0, train_stop):
img = Image.open(os.path.join(row_path, all_data[t].strip()))
label = img.copy()
img = input_transform(img, t, boxes, crop_size, upscale_factor)
label = target_transform(label, t, boxes, crop_size)
if not os.path.exists(os.path.join(save_path, "train", "img")):
os.makedirs(os.path.join(save_path, "train", "img"))
img.save(os.path.join(save_path, "train", "img", "{}.jpg".format(t)))
if not os.path.exists(os.path.join(save_path, "train", "label")):
os.makedirs(os.path.join(save_path, "train", "label"))
label.save(os.path.join(save_path, "train", "label", "{}.jpg".format(t)))
f_train.write(f"{t}.jpg\n")
f_train.flush()
for v in range(train_stop, data_length):
img = Image.open(os.path.join(row_path, all_data[v].strip()))
label = img.copy()
img = input_transform(img, v, boxes, crop_size, upscale_factor)
label = target_transform(label, v, boxes, crop_size)
if not os.path.exists(os.path.join(save_path, "val", "img")):
os.makedirs(os.path.join(save_path, "val", "img"))
img.save(os.path.join(save_path, "val", "img", "{}.jpg".format(v - train_stop)))
if not os.path.exists(os.path.join(save_path, "val", "label")):
os.makedirs(os.path.join(save_path, "val", "label"))
label.save(os.path.join(save_path, "val", "label", "{}.jpg".format(v - train_stop)))
f_val.write(f"{v - train_stop}.jpg\n")
f_val.flush()
处理后的目录展示:

下面是自定义的数据集:
import os
from PIL import Image
from torch.utils.data import Dataset
import torchvision.transforms as tfs
class SRGANDataset(Dataset):
def __init__(self, data_path, ty="train"):
self.dataset = []
self.path = data_path
self.ty = ty
f = open(os.path.join(data_path, "{}.txt".format(ty)))
self.dataset.extend(f.readlines())
f.close()
self.tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_name = self.dataset[index].strip()
img = Image.open(os.path.join(self.path, self.ty, "img", img_name))
label = Image.open(os.path.join(self.path, self.ty, "label", img_name))
img = self.tfs(img)
label = self.tfs(label)
return img, label
网络训练
网络训练部分代码比较长,我这里不过多解释,我把代码贴在这里,有问题联系我
import torch
import dataset
import os
import argparse
from torch.utils.data import DataLoader
import models
import time
import matplotlib.pyplot as plt
import loss
class Trainer:
record = {"train_loss_d": [], "train_loss_g": [], "train_psnr": [], "val_loss": [], "val_psnr": []}
x_epoch = []
def __init__(self, args):
self.args = args
self.device = self.args.device
self.gnet = models.Generator()
self.dnet = models.Discriminator()
batch = self.args.batch
self.train_loader = DataLoader(dataset.SRGANDataset(self.args.data_path, "train"),
batch_size=batch, shuffle=True, drop_last=True)
self.val_loader = DataLoader(dataset.SRGANDataset(self.args.data_path, "val"),
batch_size=batch, shuffle=False, drop_last=True)
self.criterion_g = loss.PerceptualLoss(self.device)
self.regularization = loss.RegularizationLoss()
self.criterion_d = torch.nn.BCELoss()
self.epoch = 0
self.lr = 1e-3
self.best_psnr = 0.
if self.args.resume:
if not os.path.exists(self.args.save_path):
print("No params, start training...")
else:
param_dict = torch.load(self.args.save_path)
self.epoch = param_dict["epoch"]
self.lr = param_dict["lr"]
self.dnet.load_state_dict(param_dict["dnet_dict"])
self.gnet.load_state_dict(param_dict["gnet_dict"])
self.best_psnr = param_dict["best_psnr"]
print("Loaded params from {}\n[Epoch]: {} [lr]: {} [best_psnr]: {}".format(self.args.save_path,
self.epoch, self.lr,
self.best_psnr))
self.dnet.to(self.device)
self.gnet.to(self.device)
self.optimizer_d = torch.optim.Adam(self.dnet.parameters(), lr=self.lr)
self.optimizer_g = torch.optim.Adam(self.gnet.parameters(), lr=self.lr*0.1)
self.real_label = torch.ones([batch, 1, 1, 1]).to(self.device)
self.fake_label = torch.zeros([batch, 1, 1, 1]).to(self.device)
@staticmethod
def calculate_psnr(img1, img2):
return 10. * torch.log10(1. / torch.mean((img1 - img2) ** 2))
def train(self, epoch):
self.dnet.train()
self.gnet.train()
train_loss_d = 0.
train_loss_g = 0.
train_loss_all_d = 0.
train_loss_all_g = 0.
psnr = 0.
total = 0
start = time.time()
print("Start epoch: {}".format(epoch))
for i, (img, label) in enumerate(self.train_loader):
img = img.to(self.device)
label = label.to(self.device)
fake_img = self.gnet(img)
loss_g = self.criterion_g(fake_img, label, self.dnet(fake_img)) + 2e-8*self.regularization(fake_img)
self.optimizer_g.zero_grad()
loss_g.backward()
self.optimizer_g.step()
if i % 2 == 0:
real_out = self.dnet(label)
fake_out = self.dnet(fake_img.detach())
loss_d = self.criterion_d(real_out, self.real_label
) + self.criterion_d(fake_out, self.fake_label)
self.optimizer_d.zero_grad()
loss_d.backward()
self.optimizer_d.step()
train_loss_d += loss_d.item()
train_loss_all_d += loss_d.item()
train_loss_g += loss_g.item()
train_loss_all_g += loss_g.item()
psnr += self.calculate_psnr(fake_img, label).item()
total += 1
if (i+1) % self.args.interval == 0:
end = time.time()
print("[Epoch]: {}[Progress: {:.1f}%]time:{:.2f} dnet_loss:{:.5f} gnet_loss:{:.5f} psnr:{:.4f}".format(
epoch, (i+1)*100/len(self.train_loader), end-start,
train_loss_d/self.args.interval,
train_loss_g/self.args.interval, psnr/total
))
train_loss_d = 0.
train_loss_g = 0.
print("Save params to {}".format(self.args.save_path1))
param_dict = {
"epoch": epoch,
"lr": self.lr,
"best_psnr": self.best_psnr,
"dnet_dict": self.dnet.state_dict(),
"gnet_dict": self.gnet.state_dict()
}
torch.save(param_dict, self.args.save_path)
return train_loss_all_d/len(self.train_loader), train_loss_all_g/len(self.train_loader), psnr/total
def val(self, epoch):
self.gnet.eval()
self.dnet.eval()
print("Test start...")
val_loss = 0.
psnr = 0.
total = 0
start = time.time()
with torch.no_grad():
for i, (img, label) in enumerate(self.train_loader):
img = img.to(self.device)
label = label.to(self.device)
fake_img = self.gnet(img).clamp(0.0, 1.0)
loss = self.criterion_g(fake_img, label, self.dnet(fake_img))
val_loss += loss.item()
psnr += self.calculate_psnr(fake_img, label).item()
total += 1
mpsnr = psnr / total
end = time.time()
print("Test finished!")
print("[Epoch]: {} time:{:.2f} loss:{:.5f} psnr:{:.4f}".format(
epoch, end - start, val_loss / len(self.val_loader), mpsnr
))
if mpsnr > self.best_psnr:
self.best_psnr = mpsnr
print("Save params to {}".format(self.args.save_path))
param_dict = {
"epoch": epoch,
"lr": self.lr,
"best_psnr": self.best_psnr,
"gnet_dict": self.gnet.state_dict(),
"dnet_dict": self.dnet.state_dict()
}
torch.save(param_dict, self.args.save_path1)
return val_loss/len(self.val_loader), mpsnr
def draw_curve(self, fig, epoch, train_loss_d, train_loss_g, train_psnr, val_loss, val_psnr):
ax0 = fig.add_subplot(121, title="loss")
ax1 = fig.add_subplot(122, title="psnr")
self.record["train_loss_d"].append(train_loss_d)
self.record["train_loss_g"].append(train_loss_g)
self.record["train_psnr"].append(train_psnr)
self.record["val_loss"].append(val_loss)
self.record["val_psnr"].append(val_psnr)
self.x_epoch.append(epoch)
ax0.plot(self.x_epoch, self.record["train_loss_d"], "bo-", label="train_d")
ax0.plot(self.x_epoch, self.record["train_loss_g"], "go-", label="train_g")
ax0.plot(self.x_epoch, self.record["val_loss"], "ro-", label="val_g")
ax1.plot(self.x_epoch, self.record["train_psnr"], "bo-", label="train")
ax1.plot(self.x_epoch, self.record["val_psnr"], "ro-", label="val")
if epoch == 0:
ax0.legend()
ax1.legend()
fig.savefig(r"./train_fig/train_{}.jpg".format(epoch))
def lr_update(self):
for param_group in self.optimizer_d.param_groups:
param_group['lr'] = self.lr * 0.1
self.lr = self.optimizer_d.param_groups[0]["lr"]
for param_group in self.optimizer_g.param_groups:
param_group['lr'] = self.lr
print("===============================================")
print("Learning rate has adjusted to {}".format(self.lr))
def main(args):
t = Trainer(args)
fig = plt.figure()
for epoch in range(t.epoch, t.epoch + args.num_epochs):
train_loss_d, train_loss_g, train_psnr = t.train(epoch)
val_loss, val_psnr = t.val(epoch)
t.draw_curve(fig, epoch, train_loss_d, train_loss_g, train_psnr, val_loss, val_psnr)
# if (epoch + 1) % 10 == 0:
# t.lr_update()
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="Training SRGAN with celebA")
parser.add_argument("--device", default="cuda", type=str)
parser.add_argument("--data_path", default=r"T:\srgan", type=str)
parser.add_argument("--resume", default=False, type=bool)
parser.add_argument("--num_epochs", default=100, type=int)
parser.add_argument("--save_path", default=r"./weight01.pt", type=str)
parser.add_argument("--save_path1", default=r"./weight00.pt", type=str)
parser.add_argument("--interval", default=20, type=int)
parser.add_argument("--batch", default=8, type=int)
args1 = parser.parse_args()
main(args1)
本人水平有限,文中发现错误敬请指正。(看到这了,点个关注点个赞吧!)