强化学习:PPO求解MountainCar问题通用代码(也适合其他环境)
# PPO通用代码
import sys
sys.path.append(r'D:\Anaconda3\envs\pythonProjectNewStart\Lib\site-packages')
import numpy as np
import torch
# 导入torch的各种模块
import torch.nn as nn
from torch.nn import functional as F
from torch.distributions import Categorical
import gym
import warnings
warnings.filterwarnings('ignore')
import random
from collections import deque
import matplotlib.pyplot as plt
import copy
from IPython.display import clear_output
%matplotlib inline
# avoid the warning message
gym.logger.set_level(40)
class Memory:
def __init__(self):
self.actions = []
self.states = []
self.logprobs = []
self.rewards = []
self.is_terminals = []
def clear_memory(self):
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim):
super(ActorCritic, self).__init__()
# actor
self.action_layer = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, action_dim),
nn.Softmax(dim=-1)
)
# critic
self.value_layer = nn.Sequential(
nn.Linear(state_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, hidden_dim),
nn.Tanh(),
nn.Linear(hidden_dim, 1)
)
def forward(self):
raise NotImplementedError
def select_action(self, state):
state = torch.from_numpy(state).float()
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action = dist.sample()
return state,action,dist.log_prob(action)
def evaluate(self, state, action):
action_probs = self.action_layer(state)
dist = Categorical(action_probs)
action_logprobs = dist.log_prob(action)
dist_entropy = dist.entropy()
state_value = self.value_layer(state)
return action_logprobs, torch.squeeze(state_value), dist_entropy
class PPO:
def __init__(self,state_dim, action_dim, hidden_dim, lr, gamma, K_epochs, eps_clip):
self.lr = lr
self.gamma = gamma
self.eps_clip = eps_clip
self.K_epochs = K_epochs
self.policy = ActorCritic(state_dim, action_dim, hidden_dim)
self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr)
self.policy_old = ActorCritic(state_dim, action_dim, hidden_dim)
self.policy_old.load_state_dict(self.policy.state_dict())
self.MseLoss = nn.MSELoss()
self.losses = []
# 用作缓冲区
self.memory = Memory()
def update_policy(self):
# Monte Carlo estimate of state rewards:
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(self.memory.rewards), reversed(self.memory.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
# Normalizing the rewards:
rewards = torch.tensor(rewards)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-5)
# convert list to tensor
old_states = torch.stack(self.memory.states).detach()
old_actions = torch.stack(self.memory.actions).detach()
old_logprobs = torch.stack(self.memory.logprobs).detach()
# Optimize policy for K epochs:
for _ in range(self.K_epochs):
# Evaluating old actions and values :
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# Finding the ratio (pi_theta / pi_theta__old):
ratios = torch.exp(logprobs - old_logprobs.detach())
# Finding Surrogate Loss:
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
loss = -torch.min(surr1, surr2) + 0.5*self.MseLoss(state_values, rewards) - 0.01*dist_entropy
self.losses.append(loss.mean())
# take gradient step
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# Copy new weights into old policy:
self.policy_old.load_state_dict(self.policy.state_dict())
# 下面是训练网络
# 下面网络可以改进,不用每次都更新
def train_network(self,epsiodes=500):
epsiode_rewards = []
mean_rewards = []
for epsiode in range(1,epsiodes+1):
state = env.reset()
ep_reward = 0
while True:
# Running policy_old:
state,action,log_prob = self.policy_old.select_action(state)
self.memory.logprobs.append(log_prob)
self.memory.states.append(state)
self.memory.actions.append(action)
# 下面与网络进行交互
state, reward, done, _,_ = env.step(action.item())
# Saving reward and is_terminal:
self.memory.rewards.append(reward)
self.memory.is_terminals.append(done)
ep_reward += reward
if done:
self.update_policy()
self.memory.clear_memory()
break
# logging
epsiode_rewards.append(ep_reward)
mean_rewards.append(torch.mean(torch.Tensor(epsiode_rewards[-30:])))
print("第{}回合的奖励值是{:.2f},平均奖励是{:.2f}".format(epsiode,ep_reward,mean_rewards[-1]))
return epsiode_rewards,mean_rewards
#def plot (episode, ep_rewards, running_rewards, all_losses):
# clear_output(True)
# plt.figure(figsize=(20,5))
# plt.subplot(131)
# plt.plot(ep_rewards)
# plt.plot(running_rewards)
# plt.title('episode %s. reward: %s' % (episode, running_rewards[-1]))
# plt.xlabel('Episode')
# plt.ylabel('Reward')
# plt.subplot(132)
# plt.title('loss')
# plt.plot(all_losses)
# plt.show()
if __name__ == '__main__':
############## Hyperparameters ##############
# creating environment
env = gym.make("MountainCar-v0")
env = env.unwrapped
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
max_episodes = 2000 # max training episodes
max_timesteps = 5000 # max timesteps in one episode
hidden_dim = 64 # number of variables in hidden layer
update_timestep = 1000 # update policy every n timesteps
lr = 0.002
gamma = 0.99 # discount factor
K_epochs = 4 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO
#############################################
torch.manual_seed(2)
env.seed(2)
ppo = PPO(state_dim, action_dim, hidden_dim, lr, gamma, K_epochs, eps_clip)
epsiode_rewards,mean_rewards = ppo.train_network(epsiodes=200)
plt.plot(epsiode_rewards)
plt.plot(mean_rewards)
plt.xlabel("epsiode")
plt.ylabel("rewards")
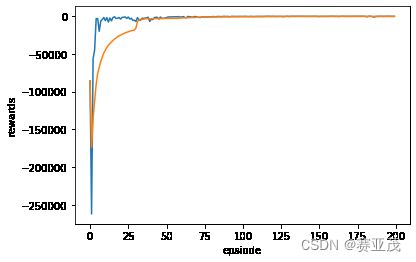
最后的结果如下图所示,可以看出PPO算法收敛效果是非常好,且非常快的。