强化学习gym的使用之mountaincar的训练

gym地址
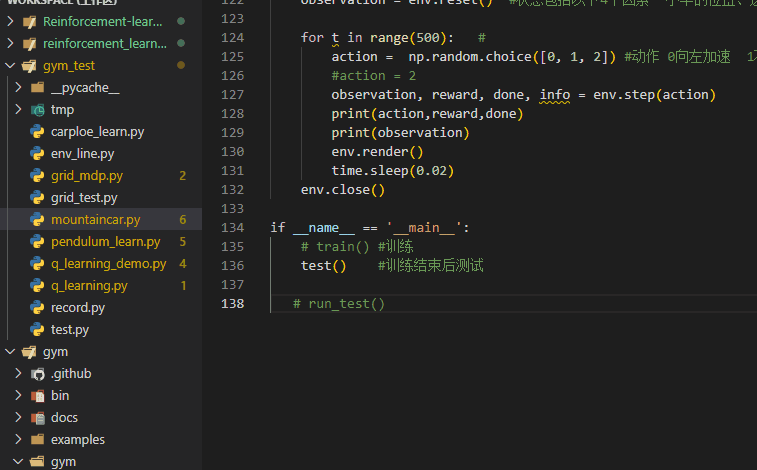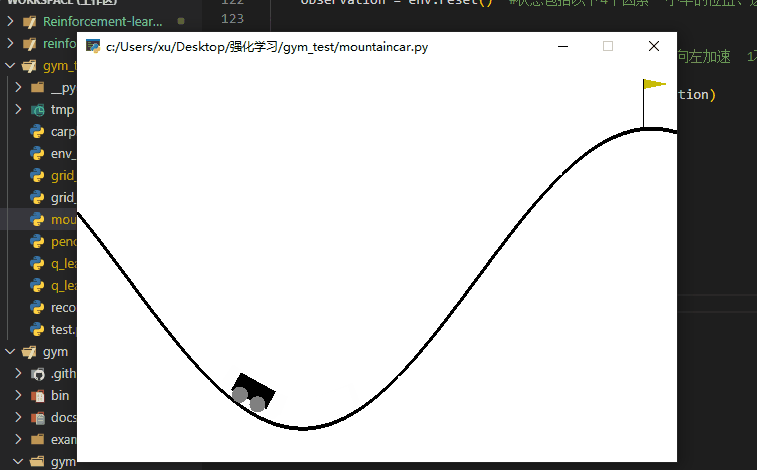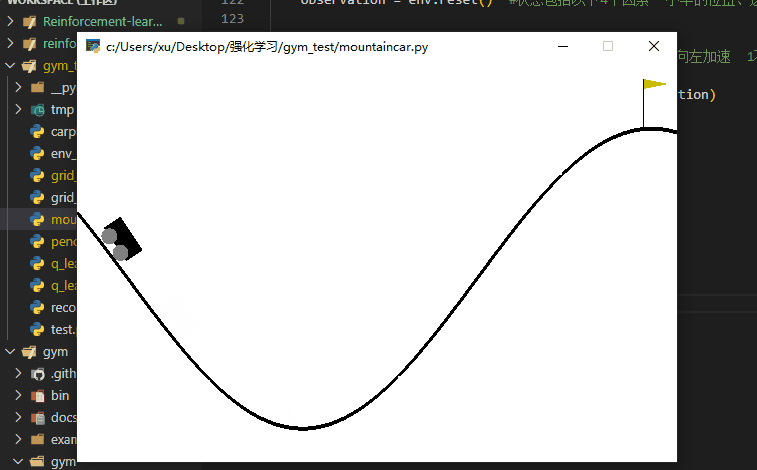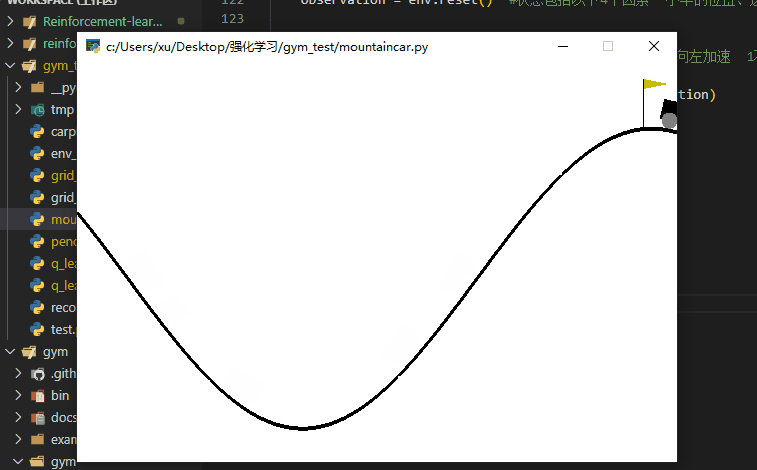
该任务是让小车跑到右侧的山顶,但是小车力不够它直接冲上去,需要让它左右荡到山顶。
在它的源文件中可以找到相关信息:
Observation:
Type: Box(2)
Num Observation Min Max
0 Car Position -1.2 0.6
1 Car Velocity -0.07 0.07
Actions:
Type: Discrete(3)
Num Action
0 Accelerate to the Left
1 Don't accelerate
2 Accelerate to the Right
Reward:
Reward of 0 is awarded if the agent reached the flag (position = 0.5)
on top of the mountain.
Reward of -1 is awarded if the position of the agent is less than 0.5.
代码测试环境,随机运动
import numpy as np
import pandas as pd
import time
import gym
import csv
import os
import pickle
from queue import Queue
import pickle
def run_test():
env = gym.make('MountainCar-v0')
observation = env.reset() #状态
for t in range(500): #
action = np.random.choice([0, 1, 2]) #动作 0向左加速 1不动 2 向右加速
#action = 2
observation, reward, done, info = env.step(action)
print(action,reward,done)
print(observation)
time.sleep(0.02)
env.close()
if __name__ == '__main__':
run_test()

接下来使用Q-learning进行训练
import numpy as np
import pandas as pd
import time
import gym
import csv
import os
import pickle
from queue import Queue
import pickle
class QLearning:
def __init__(self, actions_space, learning_rate=0.01, reward_decay=0.99, e_greedy=0.6):
self.actions = actions_space # 可以选择的动作空间
#self.target # 目标状态(终点)
self.lr = learning_rate # 学习率 决定这次的误差有多少是要被学习的
self.gamma = reward_decay # 回报衰减率 对未来reward的衰减值。gamma越接近1,机器对未来的reward越敏感
self.epsilon = e_greedy # 探索/利用 贪婪系数
self.num_pos = 20 #将位置分为num_pos份
self.num_vel = 14 #将速度分为num_vel份
# q_table是一个二维数组 # 离散化后的状态共有num_pos*num_vel中可能的取值,每种状态会对应一个行动# q_table[s][a]就是当状态为s时作出行动a的有利程度评价值
self.q_table = np.random.uniform(low=-1, high=1, size=(self.num_pos*self.num_vel, self.actions.n)) # Q值表
self.pos_bins = self.toBins(-1.2, 0.6, self.num_pos)
self.vel_bins = self.toBins(-0.07, 0.07, self.num_vel)
# 根据本次的行动及其反馈(下一个时间步的状态),返回下一次的最佳行动
def choose_action(self,state):
# 假设epsilon=0.9,下面的操作就是有0.9的概率按Q值表选择最优的,有0.1的概率随机选择动作
# 随机选动作的意义就是去探索那些可能存在的之前没有发现但是更好的方案/动作/路径
if np.random.uniform() < self.epsilon:
# 选择最佳动作(Q值最大的动作)
action = np.argmax(self.q_table[state])
else:
# 随机选择一个动作
action = self.actions.sample()
return action
# 分箱处理函数,把[clip_min,clip_max]区间平均分为num段,
def toBins(self,clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)
# 分别对各个连续特征值进行离散化 末端值-1 如[1 5 10]时 取2 为1 取5或6为2 取10为3 此时-1让其为2
def digit(self,x, bin):
n = np.digitize(x,bins = bin)
if x== bin[-1]:
n=n-1
return n
# 将观测值observation离散化处理
def digitize_state(self,observation):
# 将矢量打散回连续特征值
cart_pos, cart_v = observation
# 分别对各个连续特征值进行离散化(分箱处理)
digitized = [self.digit(cart_pos,self.pos_bins),
self.digit(cart_v,self.vel_bins),]
# 将4个离散值再组合为一个离散值,作为最终结果
return (digitized[1]-1)*self.num_pos + digitized[0]-1
# 学习,主要是更新Q值
def learn(self, state, action, r, next_state):
next_action = np.argmax(self.q_table[next_state])
q_predict = self.q_table[state, action]
q_target = r + self.gamma * self.q_table[next_state, next_action] # Q值的迭代更新公式
self.q_table[state, action] += self.lr * (q_target - q_predict) # update
def train():
env = gym.make('MountainCar-v0')
print(env.action_space)
agent = QLearning(env.action_space)
# with open(os.getcwd()+'/tmp/carmountain.model', 'rb') as f:
# agent = pickle.load(f)
# agent.actions = env.action_space #初始化
for i in range(10000): #训练次数
observation = env.reset() #状态
state = agent.digitize_state(observation) #状态标准化
for t in range(300): #一次训练最大运行次数
action = agent.choose_action(state) #动作 0向左加速 1不动 2 向右加速
observation, reward, done, info = env.step(action)
next_state = agent.digitize_state(observation)
# if done:
# reward-=200 #对于一些直接导致最终失败的错误行动,其报酬值要减200
if reward == 0: #到达山顶时reward为0
reward+=1000 #给大一点
print(action,reward,done,state,next_state)
agent.learn(state,action,reward,next_state)
state = next_state
if done: #重新加载环境
print("Episode finished after {} timesteps".format(t+1))
break
# env.render() # 更新并渲染画面
print(agent.q_table)
env.close()
#保存
with open(os.getcwd()+'/tmp/carmountain.model', 'wb') as f:
pickle.dump(agent, f)
def test():
env = gym.make('MountainCar-v0')
print(env.action_space)
with open(os.getcwd()+'/tmp/carmountain.model', 'rb') as f:
agent = pickle.load(f)
agent.actions = env.action_space #初始化
agent.epsilon = 1
observation = env.reset() #
state = agent.digitize_state(observation) #状态标准化
for t in range(500): #一次训练最大运行次数
action = agent.choose_action(state) #
observation, reward, done, info = env.step(action)
next_state = agent.digitize_state(observation)
print(action,reward,done,state,next_state)
agent.learn(state,action,reward,next_state)
state = next_state
env.render() # 更新并渲染画面
env.close()
def run_test():
env = gym.make('MountainCar-v0')
observation = env.reset() #状态包括以下4个因素 小车的位置、速度 木棒的角度、速度
for t in range(500): #
action = np.random.choice([0, 1, 2]) #动作 0向左加速 1不动 2 向右加速
#action = 2
observation, reward, done, info = env.step(action)
print(action,reward,done)
print(observation)
env.render()
time.sleep(0.02)
env.close()
if __name__ == '__main__':
train() #训练
test() #训练结束后测试
# run_test()
为了训练的快一些,训练时不加载画面
训练完成后 进行测试
可以看到小车很快啊,就冲上了山顶