pytorch-California House Prices(Kaggle竞赛)
Kaggle 竞赛:California House Prices (使用MLP解决)
Step 1: 数据处理, num 和 obj 两类数据划分
import numpy as np
import pandas as pd
import seaborn as sns
import torch
from torch import nn
from d2l import torch as d2l
import matplotlib.pyplot as plt
%matplotlib inline
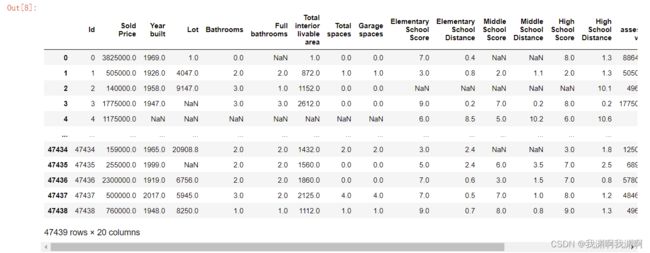
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
print(train_data.shape)
print(test_data.shape)

1.1 num数据处理
'''
将数据集分成 num 和 obj 两类
'''
numeric_features = train_data.dtypes[train_data.dtypes != 'object'].index
obj_features = train_data.dtypes[train_data.dtypes == 'object'].index
train_num = train_data[numeric_features]
train_obj = train_data[obj_features]
1.11 对数字特征的处理
相关性分析:皮尔森相关性分析 和 斯皮尔曼相关性分析
原因: 数据集特征太多,先进行相关性分析筛选出主要的特征
corrPearson = train_data.corr(method="pearson") # 两种相关系数定义方法
corrSpearman = train_data.corr(method="spearman")
figure = plt.figure(figsize=(30,25))
sns.heatmap(corrPearson,annot=True,cmap='RdYlGn', vmin=-1, vmax=+1)
plt.title("PEARSON")
plt.xlabel("COLUMNS")
plt.ylabel("COLUMNS")
figure = plt.figure(figsize=(30,25))
sns.heatmap(corrSpearman,annot=True,cmap='RdYlGn', vmin=-1, vmax=+1)
plt.title("SPEARMAN")
plt.xlabel("COLUMNS")
plt.ylabel("COLUMNS")
plt.savefig('Spearman_corr.jpg')



1.12 异常值处理
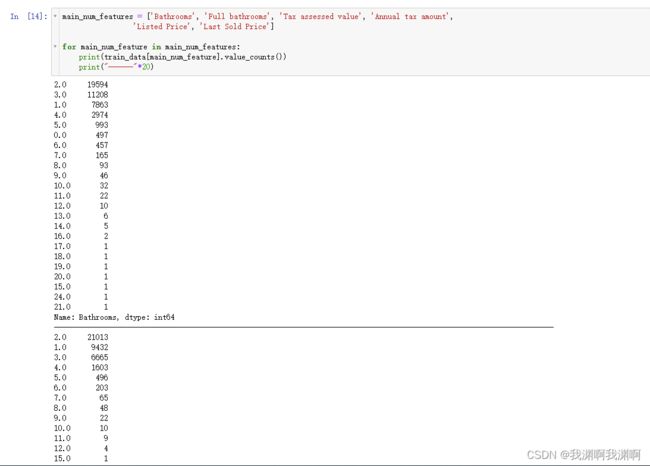
main_num_features = ['Bathrooms', 'Full bathrooms', 'Tax assessed value', 'Annual tax amount',
'Listed Price', 'Last Sold Price']
for main_num_feature in main_num_features:
print(train_data[main_num_feature].value_counts())
print("------"*20)
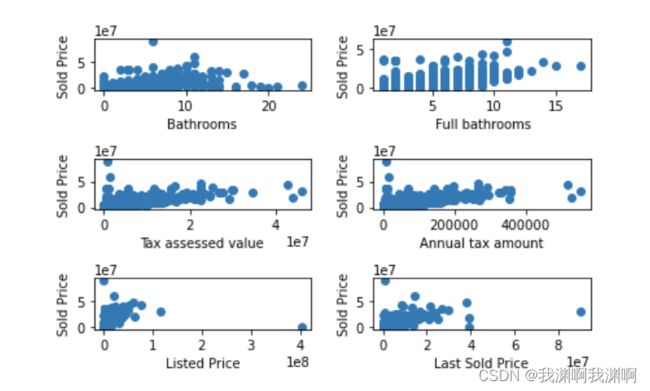
数据中存在部分异常数据,把离散点去除
train_data = train_data.drop(train_data[(train_data['Tax assessed value']>4 * 10000000) | (train_data['Sold Price']>5 * 10000000)].index)
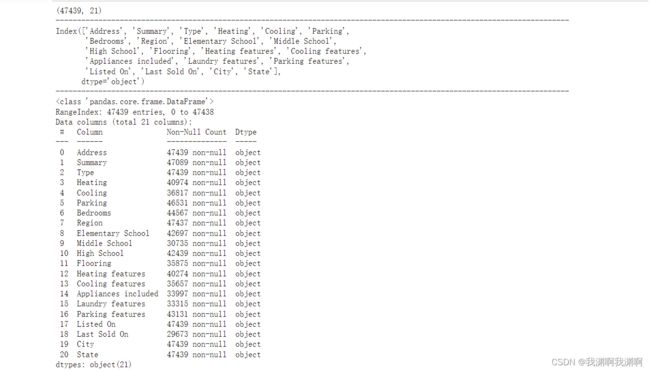
1.2 object 数据
打印离散值特征
print(train_obj.shape)
print("------"*20)
print(train_obj.columns)
print("------"*20)
print(train_obj.info())
print("------"*20)
print(train_obj.describe())
print("------"*20)
ntrain = train_data.shape[0]
ntest = test_data.shape[0]
y_train = train_data['Sold Price'].values
all_features = main_num_features + main_obj_features
train_labels = torch.tensor(train_data['Sold Price'].values.reshape(-1, 1),
dtype=torch.float32)
train_data1 = train_data[all_features]
test_data1 = test_data[all_features]
all_data = pd.concat((train_data1, test_data1)).reset_index(drop=True)
# all_data.drop(['Sold Price'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape))
# 对于字符特征,使用独热编码
all_data = pd.get_dummies(all_data, dummy_na=True)
# 对于数值特征,用均值替代空值
all_data[main_num_features] = all_data[main_num_features].fillna(all_data[main_num_features].mean())
Step 2: 建立模型MLP
n_train = train_data.shape[0]
train_features = torch.tensor(all_data[:n_train].values,
dtype=torch.float32)
test_features = torch.tensor(all_data[n_train:].values,
dtype=torch.float32)
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features, 64),
nn.ReLU(),
nn.Linear(64, 1))
return net
loss = nn.MSELoss()
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.01, 0.001, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.01, 0.001, 64
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将网络应用于测试集。
preds = net(test_features).detach().numpy()
preds = pd.Series(preds.reshape(1,-1)[0])
# 将其重新格式化以导出到Kaggle
# test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
# submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
# submission.to_csv('submission.csv', index=False)
return preds
Step 3 :模型预测,导出
preds_1 = train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
sub_file = pd.read_csv('sample_submission.csv')
sub_file['Sold Price'] = preds_1
sub_file.to_csv('submission.csv')