Cityscapes数据集的深度完整解析
cityscapes数据集是分割模型训练时比较常用的一个数据集,他还可以用来训练GAN网络生成街景图片。
数据集下载和文件夹组成:
- 整个数据集包含50个欧洲城市,5000张精细标注图像(标注位于gtFine文件夹,2975张train(就是这部分图像用来训练),500张val,1525张test,19个分类类别),以及20000张非精细标注图像(标注位于gtCoarse文件夹),源图大小都是1024x2048(hxw)
- 数据集下载一般有2-3个包,分别对应2-3个文件夹,即如下:
- leftImg8bit(11G),放置训练源图,按城市分子文件夹,存放png图片
- gtFine(241M),放置精细标注文件,按城市分子文件夹,存放png/json文件
- gtCoarse(1.3G),放置非精细标注的文件(该文件夹不是必须,可不使用)
- cityscapesscripts,放置处理脚本(该文件夹不是必须,可不使用)
- 文件夹leftImg8bit:先分train/val/test三个文件夹,每个文件夹下又按城市分子文件夹,每个城市文件夹下就是源图png文件。
- 文件夹gtFine:先分train(18个城市)/val(3个城市)/test(6个城市)三个文件夹,每个文件夹下又按城市分子文件夹,每个城市文件夹下针对每张源图png文件对应了6张标注文件:
- xxx_gtFine_color.png 代表可视化的分割图,一般不用
- xxx_gtFine_instanceIds.png 代表实例分割标注文件
- xxx_gtFine_instanceTrainIds.png 代表实例
- xxx_gtFine_labelIds.png 代表每个实例的标签id标注
- xxx_gtFine_labelTrainIds.png
- xxx_gtFine_polygons.json
- 文件夹cityscapesscript:包含一些支持脚本/可视化脚本
标注文件解析:所有标注文件都在gtFine文件夹下
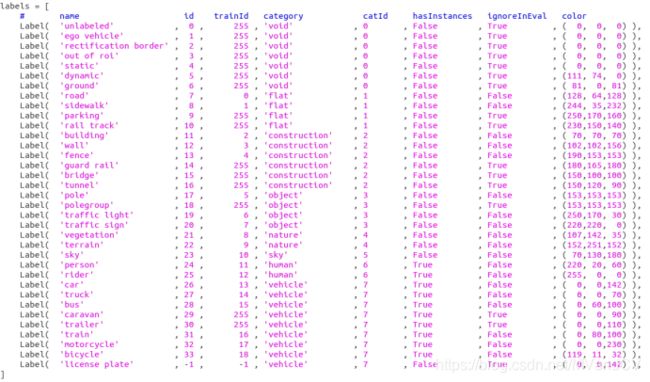
标注文件1:cityscapesscripts/helpers/label.py
该文件包含cityscapes数据集的所有类和相关label的对应关系
- 其中”id”列代表类别编号,从0-33加上-1总计有35种类型
- 其中”hasInstances”列代表是否有实例标记,如果为True则会在InstanceIds.png标记出来
标注文件2:xxx_gtFine_polygons.json
该文件是标注文件,基本结构如下所示:包含了一张图像上分割的所有对象的label/polygon,以aachen_000055_000019_gtFine_polygons.json为例,包括每个标注物体的label以及polygon通过坐标形式存放。

标注文件3:xxx_gtFine_color.json
该文件是标记可视化文件,如下图左边的图所示。对每个类别都采用一种固定的颜色进行可视化,该颜色可以根据id从label.py中查找到。
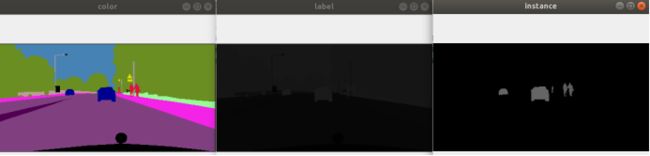
以aachen_000055_000019_gtFine_color.png为例,打开文件放大如下:
- 左下角蓝色的rgb为(0,0,142),跟label.py中对id26=’car’的颜色定义一致
- 同理绿色rgb(107,142,35)跟id21=’vegitation’的颜色定义一致,红色rgb(220,20,60)跟id24=’person’的颜色定义一致

标注文件4:xxx_gtFine_labelIds.png
该文件是类别标注文件,如下中间的图所示,他包含了所有类别”id”的标记

以aachen_000055_000019_gtFine_labelIds.png为例,打开文件放大如下:
- 其中26代表car,21代表vegitation,7代表road,8代表sidewalk,24代表person

标注文件5:xxx_gtFine_instanceIds.png
该文件是实例标注文件,如下右图所示,他只包含了在label.py中’hasInstances’=True的物体,也就是总计标记了10类。

以aachen_000055_000019_gtFine_instanceIds.png为例,打开文件放大如下:

注意:如果直接用opencv的常规方式打开图像,放大后显示的像素值如上图所示,但该像素值并不是真实的instanceIds的像素值,而是被opencv默认截取到[0,255]的像素值(也就是自动把图形的数据类型从uint转为uchar了)。但实际上instanceIds的像素值是通过计算方式val=id*1000+i,数据类型为uint,其中id默认是等于”id”列的值,i则默认从0开始计数的整数,从而instanceIds.png才能作为一个实例分割的标记图像。我们需要通过cv2.imread(path, cv2.IMREA_UNCHANGED)才能无损的读取到实例的uint图像数据。
如下所示方法获取实际的实例分割图像的值:
其中24000/24001代表id=24的person,26000/26001代表id=26的car,且编号从0开始按顺序递增,同类型不同物体被区分开来。
instance = cv2.imread(instance_path, cv2.IMREAD_UNCHANGED)
print(np.unique(instance)) # 此时才能看到实际数值范围[0, 1, 3, ..24000, 24001, 26000, 26001]
标注文件6:xxx_gtFine_labelTrainIds.png
该文件是类别标注文件,如下右图所示。
- 跟label.png的区别在于:
- labelIds.png是按照’id’列标记,而labelTrainIds.png则可以自定义按哪一列标记,默认是按照’trainId’列标记,也可以按照’id’列/’trainId’列/’color’列来标记
- label.png中是把所有像素全都标记了,不存在255的像素,而labelTrainIds.png则只标记了18类(trainid列的值不为255的类别),其他类别都设置为255,所以labelTrainIds.png中会有很多白色色块,就是代表了所谓非18类之外的背景色块
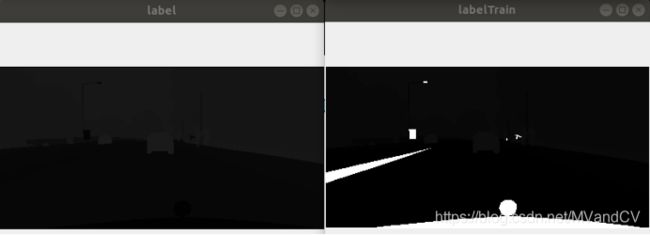
如下所示在右边labelTrainIds.png图像中:
- 其中所有类别标记都是按照trainId列的值标注的,所以11代表person,8代表vegitation,5代表pole,255代表background

- labelTrainIds.png的图像可以根据自己的需求修改labels.py中trainIds/ids/colors列的内容,从而体现在labelTrainIds.py的内容,而生成labelTrainIds.png的方法参考cityscapesscripts/preparation/json2labelImg.py/createLabelImage()
- 形参encoding决定用哪种编码列:可选择’id’,’trainId’,’color’
- 循环提取每一个annotation.objects中的val=name2label[label].id并绘制
drawer.plygon(polygon, fill=val) # 也就是用编码查找的val填入。
标注文件7:xxx_gtFine_instanceTrainIds.png
该文件是实例标注文件,如下右图所示,他只包含了在label.py中’hasInstances’=True的物体。
跟instanceIds的区别在于:
- instanceTrainIds.png文件标注的值是用id*1000+i,其中id可以设置为”ids”列或者”trainIds”列的值,i为从0开始的整数,也就是每个同类别不同物体会被区分开来。而instanceIds.png则是默认用”ids”列填充的,一般不能修改。
- 通过cv2.imread(path, cv2.IMREAD_UNCHANGED)可读取到无损的uint值,可看到默认的instanceTrainIds.png的值为[0,1,2,...11000, 11001, 13000, 13001],也就是默认用trainid*1000+i进行填充的。

如何自定义生成xxx_labelTrainIds.png和xxx_instanceTrainIds.png文件
- 可以通过cityscapesscripts/preparation里边的createTrainidInstanceImgs.py和createTrainIdLabelImgs.py来生成,函数底层是调用json2instanceImg.py和json2labelImg.py两个函数来实现的。生成的图像会自动替换掉原本cityscapse数据集中的labelTrainIds.png和instanceTrainIds.png文件,并生成一个额外的json文件供调用。