CS231n-Lecture6:训练神经网络 part I
训练神经网络 part I
- 激活函数
-
-
- Sigmoid
- tanh
- ReLU —— 修正线性单元
- Leaky ReLU
- Maxout
-
- 数据预处理(Data Preprocessing)
-
-
- 均值减法
- 归一化
-
- 权重初始化(Weight Initialization)
-
-
- 陷阱:全零初始化
- 小随机数初始化
- Xavier初始化
- 对比
- 实际操作
-
- 批量归一化(Batch Normalization)
-
-
- BN总结
-
- 正则化方法
-
-
- L1和L2正则化
- Dropout
-
-
- 训练阶段和测试阶段的dropout
- 为什么dropout的效果特别好?
-
- 数据扩增(Data Augmentation)
- 早停(Early stopping)
- 常用方法
-
- reference
激活函数
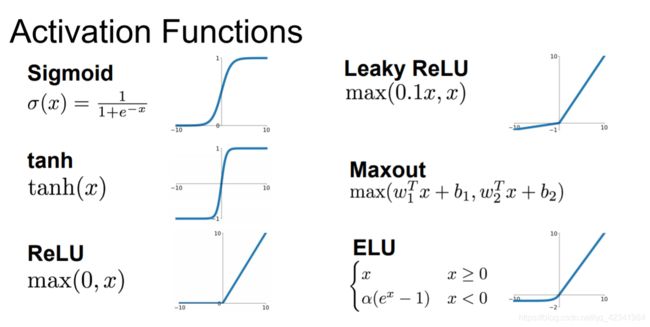
Sigmoid
sigmoid函数的导数:
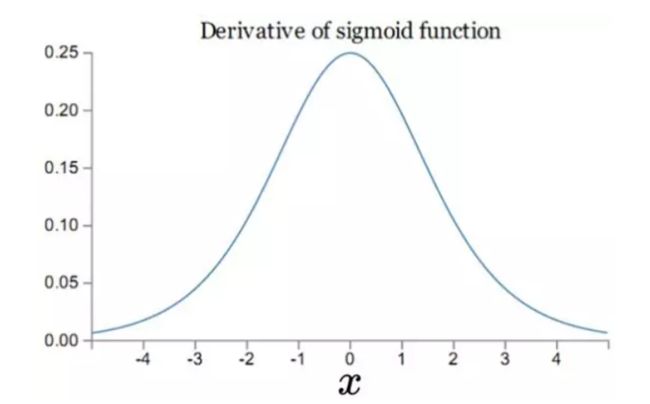
- sigmoid函数饱和使梯度消失(Sigmoid saturate and kill gradients)
我们从上图可以看到sigmoid的导数都是小于0.25的,那么在进行反向传播的时候,梯度相乘结果会慢慢的趋近于0。这样,几乎就没有梯度信号通过神经元传递到前面层的梯度更新中,因此这时前面层的权值几乎没有更新,这就叫梯度消失。除此之外,为了防止饱和,必须对于权重矩阵的初始化特别留意。如果初始化权重过大(即上图的两端),可能很多神经元得到一个比较小的梯度,致使神经元不能很好的更新权重提前饱和,神经网络就几乎不学习。 - sigmoid函数输出不是“零为中心”(zero-centered)。
一个多层的sigmoid神经网络,如果你的输入x都是正数,那么在反向传播中w的梯度传播到网络的某一处时,权值的变化是要么全正要么全负。
紫色方框恒为正,如果输入x均为正数,则w的梯度只取决于上游梯度(要么全正要么全负)。
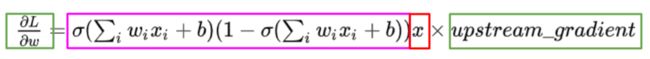
解释:当梯度从上层传播下来,w的梯度都是用x乘以f的梯度(链式法则),因此如果神经元输出的梯度是正的,那么所有w的梯度就会是正的,反之亦然。假设最优化的一个w矩阵是在上图中的第四象限(图中蓝色箭头),那么要将w优化到最优状态,就必须走“之字形”路线(图中红色曲折路线)——因为当输入一个值时,w的梯度要么都是正的要么都是负的,导致w的梯度更新方向只能是一或三象限(w要么只能往左下方向走(全负),要么只能往右上方向走(全正)),我们将会得到这种并不理想的曲折路线(zig zag path)。优化的时候效率十分低下,模型拟合的过程就会十分缓慢。
如果训练的数据并不是“零为中心”,我们将多个或正或负的梯度结合起来就会使这种情况有所缓解,但是收敛速度会非常缓慢。该问题相对于神经元饱和问题来说还是要好很多。具体可以这样解决:我们可以按batch去训练数据,那么每个batch可能得到不同的信号或正或负,这个批量的梯度加起来后可以缓解这个问题。
- 指数函数的计算是比较消耗计算资源的
tanh
优点:
- tanh解决了sigmoid的输出非“零为中心”的问题。
缺点:
- 依然有sigmoid函数过饱和的问题。
- 依然指数运算。
ReLU —— 修正线性单元
优点:
- ReLU解决了梯度消失的问题,至少x在正区间内,神经元不会饱和。
- 由于ReLU线性、非饱和的形式,在SGD中能够快速收敛。
- 计算速度要快很多。ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
- ReLU的输出不是“零为中心”(Notzero-centered output)。
- 随着训练的进行,可能会出现神经元死亡,权重无法更新的情况。这种神经元的死亡是不可逆转的死亡。
解释:训练神经网络的时候,一旦学习率没有设置好,第一次更新权重的时候,输入是负值,那么这个含有ReLU的神经节点就会死亡,再也不会被激活。因为:ReLU的导数在x>0的时候是1,在x<=0的时候是0。如果x<=0,那么ReLU的输出是0,那么反向传播中梯度也是0,权重就不会被更新,导致神经元不再学习。
也就是说,这个ReLU激活函数在训练中将不可逆转的死亡,导致了训练数据多样化的丢失。在实际训练中,如果学习率设置的太高,可能会发现网络中40%的神经元都会死掉,且在整个训练集中这些神经元都不会被激活。所以,设置一个合适的较小的学习率,会降低这种情况的发生。为了解决神经元节点死亡的情况,有人提出了Leaky ReLU、P-ReLu、R-ReLU、ELU等激活函数。
知乎:深度学习中,使用relu存在梯度过大导致神经元“死亡”,怎么理解?
Leaky ReLU
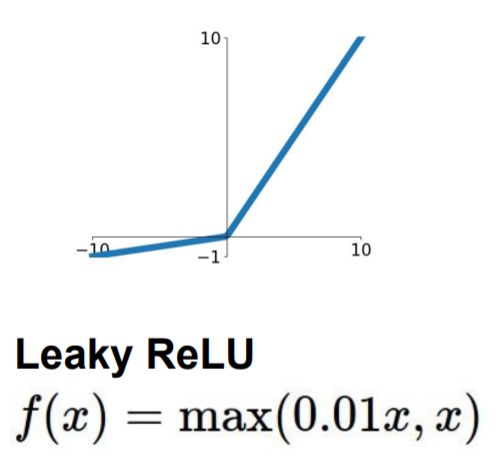
Leaky ReLU很好的解决了“dead ReLU”的问题。因为Leaky ReLU保留了x小于0时的梯度,在x小于0时,不会出现神经元死亡的问题。对于Leaky ReLU给出了一个很小的负数梯度值α,这个值是很小的常数。比如:0.01。这样即修正了数据分布,又保留了一些负轴的值,使得负轴信息不会全部丢失。但是这个α通常是通过先验知识人工赋值的。
优点:
- 神经元不会出现死亡的情况。
- 对于所有的输入,不管是大于等于0还是小于0,神经元不会饱和。
- 由于LeakyReLU线性、非饱和的形式,在SGD中能够快速收敛。
- 计算速度要快很多。Leaky ReLU函数只有线性关系,不需要指数计算,不管在前向传播还是反向传播,计算速度都比sigmoid和tanh快。
缺点:
- Leaky ReLU函数中的α,需要通过先验知识人工赋值
Maxout
max ( w 1 T x + b 1 , w 2 T x + b 2 ) \max(w_1^Tx+b_1, w_2^Tx + b_2) max(w1Tx+b1,w2Tx+b2)
是对ReLU和Leaky ReLU的一般化归纳,没有ReLU函数的缺点,不会出现激活函数饱和神经元死亡的情况。
分析公式可以注意到,ReLU和Leaky ReLU都是它的一个变形。比如 w 1 , b 1 = 0 w_1, b_1 = 0 w1,b1=0的时候,就是ReLU。Maxout的拟合能力非常强,它可以拟合任意的凸函数。
优点:
- Maxout具有ReLU的所有优点,线性、不饱和性。
- 同时没有ReLU的一些缺点。如:神经元的死亡。
缺点:
- 从这个激活函数的公式14中可以看出,每个neuron将有两组w,那么参数就增加了一倍。这就导致了整体参数的数量激增。
数据预处理(Data Preprocessing)
处理一个数据矩阵X,我们假定它的大小为 [N x D] (N是数据的数量,D是维数)。
均值减法
减去数据中每个单独特征的均值,几何解释:将数据云围绕每个维度围绕原点居中。在numpy中,此操作将实现为:X -= np.mean(X, axis = 0)。特别是对于图像,为方便起见,通常会从所有像素中减去一个值(例如X -= np.mean(X)),或者在三个颜色通道中分别这样做。
归一化
是指对数据维度进行归一化,以便它们具有大致相同的比例。有两种常见的方法:一种方法是zero-centered后将其除以标准偏差:(X /= np.std(X, axis = 0));另一种方法是对每个维度进行规格化,以使沿着该维度的最小值和最大值分别为-1和1。在图像的情况下,像素的相对比例已经近似相等(并且在0到255之间),因此不必严格地执行此附加预处理步骤。
通用数据预处理流程。左:原始toy,二维输入数据。中:通过减去每个维度的平均值,数据以零为中心。现在,数据云以原点为中心。右:每个维度通过其标准偏差进行缩放。

权重初始化(Weight Initialization)
陷阱:全零初始化
所有初始权重设置为零,导致网络中的每个神经元都计算出相同的输出,那么它们在反向传播期间也将计算出相同的梯度,并进行完全相同的参数更新。换句话说,如果神经元的权重初始化为相同,则它们之间就没有不对称的来源。
小随机数初始化
一个权重矩阵的实现可能类似于W = 0.01* np.random.randn(D,H),其中randn样本均值为零,单位标准偏差为高斯。通过这种公式,每个神经元的权重向量都被初始化为从多维高斯采样的随机向量,因此神经元指向输入空间中的随机方向。
警告:较小的数字不一定会严格地更好地工作。例如,权重非常小的神经网络层将在反向传播期间对其数据计算出非常小的梯度(因为该梯度与权重的值成比例)。这可能会大大减少通过网络反向流动的“梯度信号”,在深层的神经网络中将成为问题:
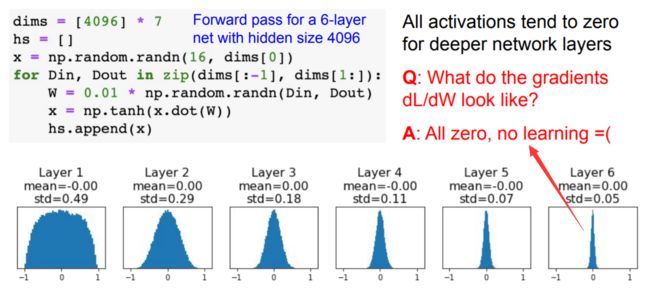
Xavier初始化
上述建议的一个问题是,随机初始化神经元的输出的分布有一个随输入量增加而变化的方差。结果证明,我们可以通过将其权重向量按其输入的平方根(即输入的数量)进行缩放,从而将每个神经元的输出的方差标准化到1。也就是将每个神经元的权重向量按下面的方法进行初始化:w=np.random.randn(n)/sqrt(n),其中n表示输入的数量。这保证了网络中所有的神经元最初的输出分布大致相同,并在经验上提高了收敛速度。
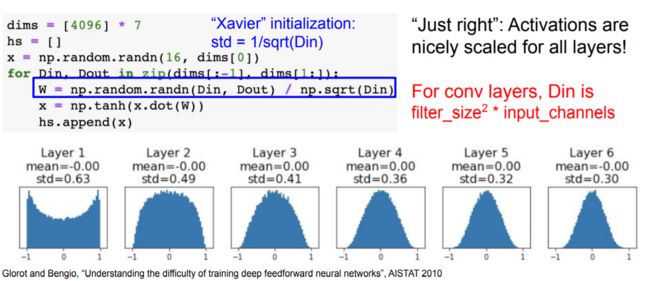
对比
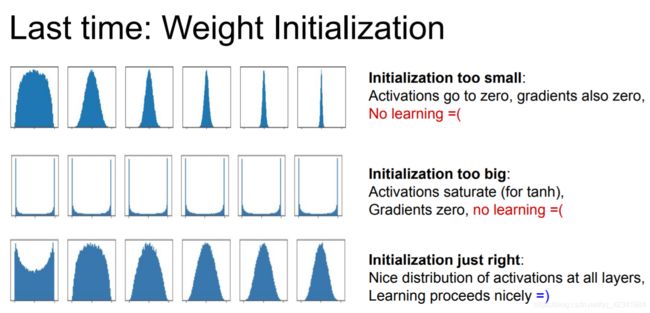
实际操作
通常的建议是使用ReLU单元以及 He等人 推荐的公式: w = n p . r a n d o m . r a n d n ( n ) ∗ s q r t ( 2.0 / n ) w = np.random.randn(n) * sqrt(2.0/n) w=np.random.randn(n)∗sqrt(2.0/n)
批量归一化(Batch Normalization)
本质思想:因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
BN总结
BN层的位置:
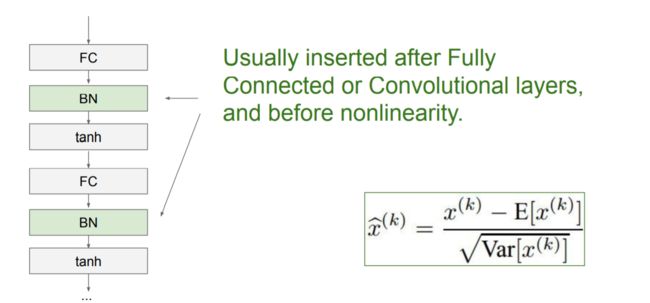
对于Mini-Batch SGD来说,一次训练过程里面包含m个训练实例,其具体BN操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
x ^ ( k ) = x ( k ) − E [ x ( k ) ] Var [ x ( k ) ] \widehat{x}^{(k)}=\frac{x^{(k)}-\mathrm{E}\left[x^{(k)}\right]}{\sqrt{\operatorname{Var}\left[x^{(k)}\right]}} x (k)=Var[x(k)]x(k)−E[x(k)]
变换后某个神经元的激活x形成了均值为0,方差为1的正态分布,目的是把值往后续要进行的非线性变换的线性区拉动,增大导数值,增强反向传播信息流动性,加快训练收敛速度。但是这样会导致网络表达能力下降,为了防止这一点,每个神经元增加两个调节参数(scale和shift),这两个参数是通过训练来学习到的,用来对变换后的激活反变换,使得网络表达能力增强,即对变换后的激活进行如下的scale和shift操作,这其实是变换的反操作:
y ( k ) = γ ( k ) x ^ ( k ) + β ( k ) y^{(k)}=\gamma^{(k)} \hat{x}^{(k)}+\beta^{(k)} y(k)=γ(k)x^(k)+β(k)
BN总的具体操作流程:

正则化方法
L1和L2正则化
一般选择L2正则化,或者同时加入L1正则化和L2正则化。
Dropout
深层神经网络的学习过程中,通过随机丢弃一部分神经元(同时丢弃其对应的连接边)来避免过拟合的做法,称为dropout。dropout一般是在神经网络的隐含层中使用,实现dropout的方式是设置一个固定的概率p,对于每一个神经元都以一个概率p来判断要不要保留。注意,dropout在训练阶段和测试阶段的做法不一样。

对于一个神经网络层 y = f ( W x + b ) y=f(Wx+b) y=f(Wx+b),引入一个丢弃函数 d ( • ) d(•) d(•),使得 y = f ( W d ( x ) + b ) y=f(Wd(x)+b) y=f(Wd(x)+b)。丢弃函数定义为:
d ( x ) = { m ⊙ x 当训练阶段时 p x 当测试阶段时 d(x)=\left\{\begin{array}{ll} m \odot x & \text { 当训练阶段时 } \\ p x & \text { 当测试阶段时 } \end{array}\right. d(x)={m⊙xpx 当训练阶段时 当测试阶段时
训练阶段和测试阶段的dropout
在训练阶段中, m ∈ { 0 , 1 } d m∈\left\{ 0,1 \right\}^d m∈{0,1}d是丢弃掩码,通过概率为p的 0-1 分布(伯努利分布)来随机生成。p值一般设置为0.5就能产生比较好的效果,复杂点也可以通过验证集来选取一个最优值,那么训练时激活神经元的平均数量是原来的p倍。举个例子就是神经元有5个,p=0.6,然后随机生成m=[1, 0, 1, 1, 0],于是训练过程中这一层中的第2和第5个神经元就会被丢弃,也就是神经元的数量变成了原理的0.6倍。
部分隐含层神经元被丢弃的结果就是,在反向传播时,和被丢弃神经元相关的权重的梯度为0。而在训练中每个隐含层神经元都有可能被以p的概率丢弃,这样就减少了神经元之间的依赖性,输出层的计算也无法过度依赖任何一个隐含层神经元,从而减少过拟合。
而在测试阶段,为了得到更确定的结果,一般不丢弃神经元。所有神经元都可以激活,这会造成训练和测试时的网络输出不一致,因此在测试时将每一个神经元的输出都乘以概率p,相当于把不同的神经网络做平均,从而在网络输出上和训练阶段保持一致。
""" 原版 Dropout: Not recommended implementation """
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
""" X contains the data """
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3
上述方案的劣势在于,必须以概率p在test time缩放激活。由于test time性能很关键,因此始终优选使用Inverted Dropout,它在train time执行缩放,而保持在test time的forward pass不变。此外,另一个好处是,当您决定调整应用dropout的位置时,预测代码可以保持不变。Inverted Dropout是这样的:
"""
Inverted Dropout: Recommended implementation example.
We drop and scale at train time and don't do anything at test time.
"""
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = (np.random.rand(*H1.shape) < p) / p # first dropout mask. Notice /p!
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = (np.random.rand(*H2.shape) < p) / p # second dropout mask. Notice /p!
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) # no scaling necessary
H2 = np.maximum(0, np.dot(W2, H1) + b2)
out = np.dot(W3, H2) + b3
为什么dropout的效果特别好?
dropout不仅能减少过拟合,而且能提高预测的准确性,这可以从集成学习的角度来解释。在迭代过程中,每做一次丢弃,就相当于从原始网络中采样一个不同的子网络,并进行训练。那么通过dropout,相当于在结构多样性的多个神经网络模型上进行训练,最终的神经网络可以看做是不同结构的神经网络的集成模型。
数据扩增(Data Augmentation)
减少过拟合的一种思路是增加训练集中的样本数量,尤其在训练深层神经网络的过程中,需要大量的训练数据才能得到比较理想的结果。但是增加样本是需要花费较多资源去搜集和标注更多的样本,因此可以基于现有的有限样本,可以通过数据增强(Data Augmentation)来增强数据,避免过拟合。
目前数据增强主要应用在图像数据上,在文本等其他类型的数据上还没有比较好的应用。
图形数据的增强主要是通过对图像进行转变、引入噪声等方法来增加数据的多样性,生成的假训练数据虽然无法包含像全新数据那么多的信息,但是代价几乎为零。增强的方法有:
- 旋转:将图像按顺时针或者逆时针方向随机旋转一定角度;
- 翻转:将图像沿水平或垂直方向随机翻转一定角度;
- 缩放:将图像沿水平或垂直方向平移一定步长;
- 颜色抖动(Color Jittering):图像亮度、饱和度、对比度变化;
- 加噪声:加入随机噪声。
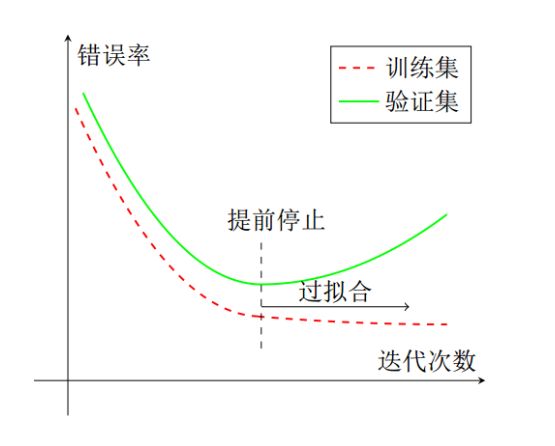
早停(Early stopping)
早停就是当迭代了多轮之后,验证集上的错误率仍然没有下降时,就停止迭代。
也就是说,在使用梯度下降法进行优化时,可以使用一个和训练集独立的样本集合,称为验证集,在每次迭代时,把新学习到的模型f(x, θ)在验证集上进行测试,并计算错误率,用验证集上的错误来代替期望错误。验证集上的误差率通常会先下降后上升,而在拐点处就预示着开始过拟合了。
当验证集的错误率在经过多轮迭代后不再下降时(甚至还升高),就停止迭代。因此在使用早停来解决过拟合时,训练和验证要同时进行,或者交叉进行。
常用方法
- Dropout
- Batch Normalization
- Data Augmentation
- DropConnect
- Fractional Max Pooling
- Stochastic Depth
- Cutout / Random Crop
- Mixup
reference
[1]神经网络梯度消失和梯度爆炸及解决办法
[2]【深度学习】深入理解Batch Normalization批标准化
[3]深度学习之正则化方法