55_pytorch,自定义数据集
1.55.自定义数据
1.55.1.数据传递机制
我们首先回顾识别手写数字的程序:
...
Dataset = torchvision.datasets.MNIST(root='./mnist/', train=True, transform=transform, download=True,)
dataloader = torch.utils.data.DataLoader(dataset=Dataset, batch_size=64, shuffle=True)
...
for epoch in range(EPOCH):
for i, (image, label) in enumerate(dataloader):
...
从上面的程序,我们可以知道,在PyTorch中,数据传递机制是这样的:
1.创建Dataset
2.Dataset传递给DataLoader
3.DataLoader迭代产生训练数据提供给模型。
总结这个数据传递机制就是,Dataset负责建立索引到样本的映射,DataLoader负责以特定的方式从数据集中迭代的产生一个个batch的样本集合。在enumerate过程中实际上是dataloader按照其参数sampler规定的策略调用了其dataset的getitem方法(下文中将介绍该方法)。
在上面的识别手写数字的例子中,数据集是直接下载的,但如果我们自己收集了一些数据,存在电脑文件夹里,我们该如何把这些数据变为可以在PyTorch框架下进行神经网络训练的数据集呢,即如何自定义数据集呢?
1.55.1.1.PyTorch中Dataset,DataLoader,Sample的关系
PyTorch中Dataset,DataLoader,Sampler的关系可以用下图概括:
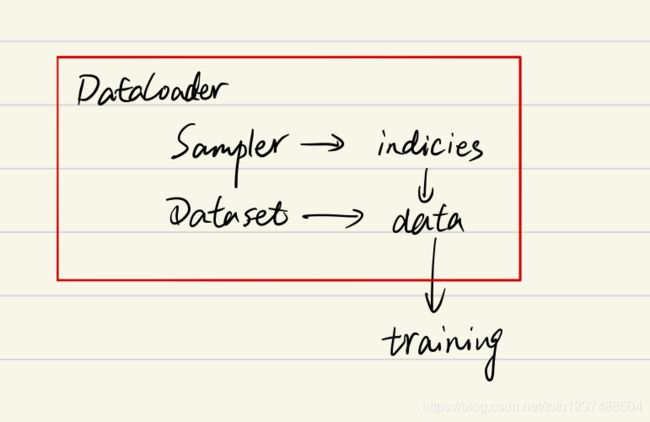
用文字表达就是:Dataloader中包含Sampler和Dataset,Sampler产生索引,Dataset拿着这个索引在数据集文件夹中找到对应的样本(每个样本对应一个索引,就像列表中每个元素对应一个索引),并给该样本配置上标签,最后返回(样本+标签)给调用方。
在enumerate过程中,Dataloader按照其参数BatchSampler规定的策略调用其Dataset的getitem方法batchsize次,得到一个batch,该batch中既包含样本,也包含相应的标签。
1.55.2.自定义数据集
torch.utils.data.Dataset 是一个表示数据集的抽象类。任何自定义的数据集都需要继承这个类并覆写相关方法。所谓数据集,其实就是一个负责处理索引(index)到样本(sample)映射的一个类(class)。Pytorch提供两种数据集: Map式数据集 Iterable式数据集。这里我们只介绍前者。
一个Map式的数据集必须要重写getitem(self, index)、 len(self) 两个内建方法,用来表示从索引到样本的映射(Map)。这样一个数据集dataset,举个例子,当使用dataset[idx]命令时,可以在你的硬盘中读取数据集中第idx张图片以及其标签(如果有的话); len(dataset)则会返回这个数据集的容量。
自定义数据集类的范式大致是这样的:
class CustomDataset(torch.utils.data.Dataset):#需要继承torch.utils.data.Dataset
def __init__(self):
# TODO
# 1. Initialize file path or list of file names.
pass
def __getitem__(self, index):
# TODO
# 1. Read one data from file (e.g. using numpy.fromfile, PIL.Image.open).
# 2. Preprocess the data (e.g. torchvision.Transform).
# 3. Return a data pair (e.g. image and label).
#这里需要注意的是,第一步:read one data,是一个data point
pass
def __len__(self):
# You should change 0 to the total size of your dataset.
return 0
关于Dataset API的官网介绍https://pytorch.org/docs/stable/data.html#dataset-types:
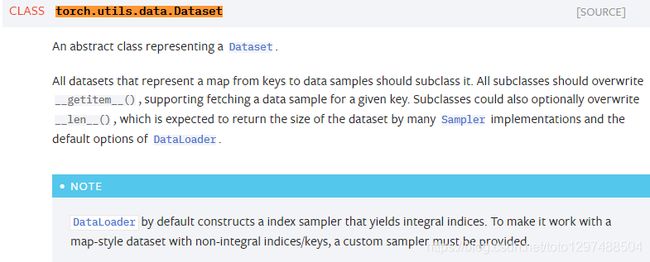
Dataset类的使用:所有的类都应该是此类的子类(也就是说应该继承该类)。所有的子类都要重写(override) len(), getitem()。
__len()__ : 此方法应该提供数据集的大小(容量)
__getitem()__ : 此方法应该提供支持下标索引方式访问数据集。
DataLoader类的使用如下:

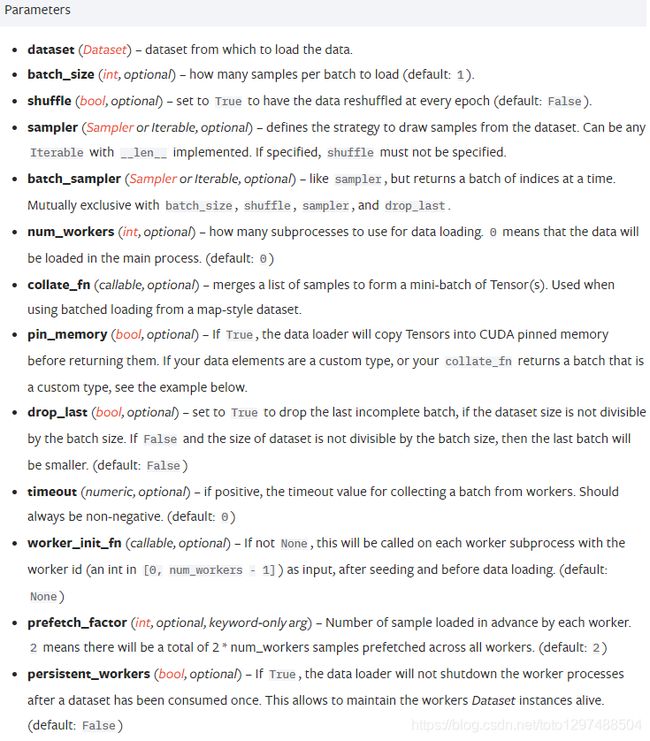
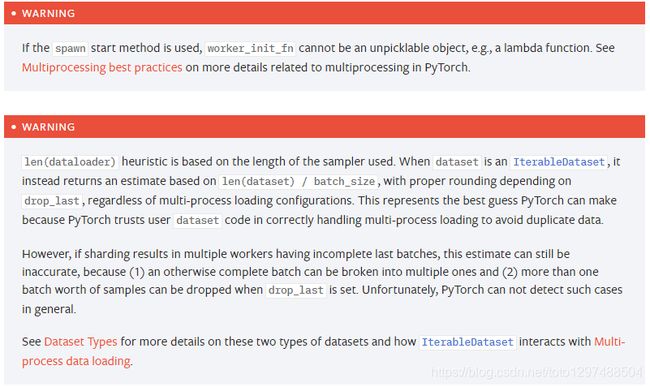
根据这个方式,我们举一个例子。
1.55.3.实例1
从kaggle官网下载dogsVScats的数据集(百度网盘下载链接见文末),该数据集包含test1文件夹和train文件夹,train文件夹中包含12500张猫的图片和12500张狗的图片,图片的文件名中带序号:
sampleSubmission.csv中的内容如下:

我们把其中前10000张猫的图片和10000张狗的图片作为训练集,把后面的2500张猫的图片和2500张狗的图片作为验证集。猫的label记为0,狗的label记为1。因为图片大小不一,所以,我们需要对图像进行transform。
# -*- coding: UTF-8 -*-
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
"""
如果代码执行的时候出现:
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program.
That is dangerous, since it can degrade performance or cause incorrect results. The best thing
to do is to ensure that only a single OpenMP runtime is linked into the process, e.g.
by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported,
undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow
the program to continue to execute, but that may cause crashes or silently produce incorrect results.
For more information, please see http://www.intel.com/software/products/support/.
解决办法是加上:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
"""
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
image_transform = transforms.Compose([
transforms.Resize(256), # 把图片resize为256*256
transforms.RandomCrop(224), # 随机裁剪224*224
transforms.RandomHorizontalFlip(), # 水平翻转
transforms.ToTensor(), # 将图像转为Tensor
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 创建一个叫做DogVsCatDataset的Dataset,继承自父类torch.utils.data.Dataset
class DogVsCatDataset(Dataset):
def __init__(self, root_dir, train=True, transform=None):
"""
Args:
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied on a sample.
"""
self.root_dir = root_dir
self.img_path = os.listdir(self.root_dir)
if train:
# 图片数据中有类似:dog.12499.jpg的图片共12499张。
# x.split('.')[1] 就是文件名dog.12473.jpg中的序号部分,也是图片的编号
self.img_path = list(filter(lambda x: int(x.split('.')[1]) < 10000, self.img_path)) # 划分训练集和验证集
else:
# 序号大于10000的编号
self.img_path = list(filter(lambda x: int(x.split('.')[1]) >= 10000, self.img_path))
self.transform = transform
def __len__(self):
return len(self.img_path)
def __getitem__(self, idx):
image = Image.open(os.path.join(self.root_dir, self.img_path[idx]))
label = 0 if self.img_path[idx].split('.')[0] == 'cat' else 1 # label, 猫为0,狗为1
if self.transform:
image = self.transform(image)
label = torch.from_numpy(np.array([label]))
return image, label
# 来测试一下
if __name__ == '__main__':
catanddog_dataset = DogVsCatDataset(root_dir='E:/BaiduNetdiskDownload/kaggle/train',
train=False,
transform=image_transform)
# num_workers=4表示用4个线程读取数据
train_loader = DataLoader(catanddog_dataset, batch_size=8, shuffle=True, num_workers=4)
# iter()函数把train_loader变为迭代器,然后调用迭代器的next()方法
image, label = iter(train_loader).next()
sample = image[0].squeeze()
sample = sample.permute((1, 2, 0)).numpy()
sample *= [0.229, 0.224, 0.225]
sample += [0.485, 0.456, 0.406]
sample = np.clip(sample, 0, 1)
plt.imshow(sample)
plt.show()
print('Label is: {}'.format(label[0].numpy()))
运行结果:
1.55.4.实例2
1.55.4.1.收集图像样本
以简单的猫狗二分类为例,可以在网上下载一些猫狗图片。创建以下目录:
data -----------------根目录
data/test -----------------测试集
data/train -----------------训练集
data/val ------------------验证集

在test/train/val之下在校分别创建2个文件夹,dog,cat
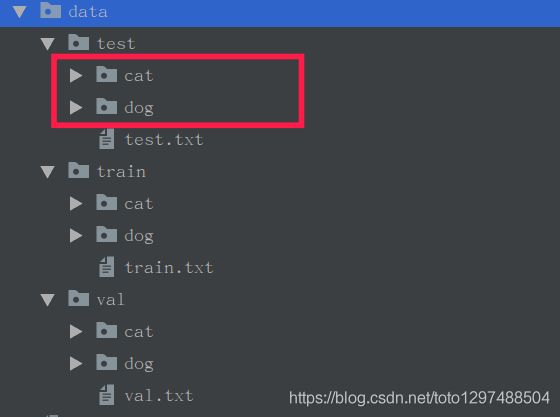
cat,dog文件夹下分别存放2类图像:
之后写一个简单的python脚本,生成txt文件,用于指明每个图像和标签的对应关系。
格式:
/cat/1.jpg 0
/dog/1.jpg 1
…
如图:
至此,样本集的收集以及简单归类完成。
1.55.4.2.实现
使用到python package
| python package | 目录 |
|---|---|
| numpy | 矩阵操作,对图像进行转置 |
| skimage | 图像处理,图像I/O,图像变换 |
| matplotlib | 图像的显示,可视化 |
| os | 一些文件查找操作 |
| torch | pytorch |
| torchvision | pytorch |
1.55.4.3.代码
# -*- coding: UTF-8 -*-
"""
本案例来自:https://www.jb51.net/article/199360.htm
"""
import numpy as np
from skimage import io
from skimage import transform
import matplotlib.pyplot as plt
import os
import torch
import torchvision
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from torchvision.utils import make_grid
"""
第一步:
定义一个子类,继承Dataset类,重写__len()__,__getitem()__方法。
细节:
1、数据集中一个一样的表示:采用字典的形式sample = {'image': image, 'label': label}。
2、图像的读取:采用skimage.io进行读取,读取之后的结果为numpy.ndarray形式。
3、图像变换:transform参数
"""
class MyDataset(Dataset):
def __init__(self, root_dir, names_file, transform=None):
self.root_dir = root_dir
self.names_file = names_file
self.transform = transform
self.size = 0
self.names_list = []
if not os.path.isfile(self.names_file):
print(self.names_file + 'does not exist!')
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.root_dir + self.names_list[idx].split(' ')[0]
if not os.path.isfile(image_path):
print(image_path + 'does not exists!')
return None
image = io.imread(image_path) # use skitimage
label = int(self.names_list[idx].split(' ')[1])
sample = {'image': image, 'label': label}
if self.transform:
sample = self.transform(sample)
return sample
"""
第二步
实例化一个对象,并读取和显示数据集
"""
train_dataset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=None)
plt.figure()
for (cnt, i) in enumerate(train_dataset):
image = i['image']
label = i['label']
ax = plt.subplot(4, 4, cnt + 1)
ax.axis('off')
ax.imshow(image)
ax.set_title('label {}'.format(label))
plt.pause(0.001)
if cnt == 15:
break
"""
第三步(可选optional)
对数据集进行变换:一般收集到的图像大小尺寸,亮度等存在差异,变换的目的就是使得数据归一化。另一方面,可
以通过变换进行数据增加data argument
关于pytorch中的变换transforms,请参考该系列之前的文章。
由于数据集中样本采用字典dicts形式表示。 因此不能直接调用torchvision.transofrms中的方法。
本实验只进行尺寸归一化Resize, 数据类型变换ToTensor操作。
Resize
"""
# 变换Resize
class Resize(object):
def __init__(self, output_size: tuple):
self.output_size = output_size
def __call__(self, sample):
# 图像
image = sample['image']
# 使用skitimage.transform对图像进行缩放
image_new = transform.resize(image, self.output_size)
return {'image': image_new, 'label': sample['label']}
# ToTensor
## 变换ToTensor
class ToTensor(object):
def __call__(self, sample):
image = sample['image']
image_new = np.transpose(image, (2, 0, 1))
return {'image': torch.from_numpy(image_new), 'label': sample['label']}
"""
第四步:对整个数据集应用变换
细节:transformers.Compose()将不同的几个组合起来。先进行Resize,再进行ToTensor
"""
# 对原始的训练数据集进行变换
transformed_trainset = MyDataset(root_dir='./data/train',
names_file='./data/train/train.txt',
transform=transforms.Compose([
Resize((224, 224)),
ToTensor()]))
"""
第五步:使用DataLoader进行包装
为何要使用DataLoader?
1、深度学习的输入是mini_batch形式
2、样本加载时候可能需要随机打乱顺序,shuffle操作
3、样本加载需要采用多线程
pytorch提供的DataLoader封装了上述的功能,这样使用起来更方便。
"""
# 使用DataLoader可以利用多线程,batch,shuffle等
# 使用DataLoader可以利用多线程,batch,shuffle等
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=4)
# 可视化
def show_images_batch(sample_batched):
images_batch, labels_batch = \
sample_batched['image'], sample_batched['label']
grid = make_grid(images_batch)
plt.imshow(grid.numpy().transpose(1, 2, 0))
# sample_batch: Tensor , NxCxHxW
plt.figure()
for i_batch, sample_batch in enumerate(trainset_dataloader):
show_images_batch(sample_batch)
plt.axis('off')
plt.ioff()
plt.show()
plt.show()
"""
通过DataLoader包装之后,样本以min_batch形式输出,而且进行了随机打乱顺序。
至此,自定义数据集的完整流程已经实现,test, val集只需要改路径即可。
"""
输出类似:




补充:
更简单的方法
上述继承Dataset,重写__len()__,__getitem()是通用的方法,过程相对繁琐。对于简单的分类数据集,pytorch中提供了更简便的方式----ImageFolder。
如果每种类别的样本放在各自的文件夹中,则可以直接使用ImageFolder。仍然以cat, dog二分类数据集为例:
文件结构:

Code
import torch
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import numpy as np
# https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
# data_transform = transforms.Compose([
# transforms.RandomResizedCrop(224),
# transforms.RandomHorizontalFlip(),
# transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
# ])
data_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
train_dataset = datasets.ImageFolder(root='./data/train',transform=data_transform)
train_dataloader = DataLoader(dataset=train_dataset,
batch_size=4,
shuffle=True,
num_workers=4)
def show_batch_images(sample_batch):
labels_batch = sample_batch[1]
images_batch = sample_batch[0]
for i in range(4):
label_ = labels_batch[i].item()
image_ = np.transpose(images_batch[i], (1, 2, 0))
ax = plt.subplot(1, 4, i + 1)
ax.imshow(image_)
ax.set_title(str(label_))
ax.axis('off')
plt.pause(0.01)
plt.figure()
for i_batch, sample_batch in enumerate(train_dataloader):
show_batch_images(sample_batch)
plt.show()
由于 train 目录下只有2个文件夹,分别为cat, dog, 因此ImageFolder安装顺序对cat使用标签0, dog使用标签1。(输出类似:)

1.55.5.参考文章
https://www.cnblogs.com/picassooo/p/12846617.html
https://www.jb51.net/article/199360.htm