PaperWeekly 第53期 | 更别致的词向量模型:Simpler GloVe - Part 2
前言
本文作者在更别致的词向量模型:Simpler GloVe - Part 1一文中提出了一个新的类似 GloVe 的词向量模型 — Simpler GloVe。
本期我们将带来该系列的后半部分,包括对该词向量模型的详细求解、结果展示,以及代码和语料分享。
模型的求解
损失函数
现在,我们来定义 loss,以便把各个词向量求解出来。用 P̃ 表示 P 的频率估计值,那么我们可以直接以下式为 loss:

相比之下,无论在参数量还是模型形式上,这个做法都比 GloVe 要简单,因此称之为 Simpler GloVe。GloVe模型是:

在 GloVe 模型中,对中心词向量和上下文向量做了区分,然后最后模型建议输出的是两套词向量的求和,据说这效果会更好,这是一个比较勉强的 trick,但也不是什么毛病。最大的问题是参数 bi,b̂j 也是可训练的,这使得模型是严重不适定的。我们有:

这就是说,如果你有了一组解,那么你将所有词向量加上任意一个常数向量后,它还是一组解。这个问题就严重了,我们无法预估得到的是哪组解,一旦加上的是一个非常大的常向量,那么各种度量都没意义了(比如任意两个词的 cos 值都接近1)。
事实上,对 GloVe 生成的词向量进行验算就可以发现,GloVe 生成的词向量,停用词的模长远大于一般词的模长,也就是说一堆词放在一起时,停用词的作用还明显些,这显然是不利用后续模型的优化的。(虽然从目前的关于 GloVe 的实验结果来看,是我强迫症了一些。)
互信息估算
为了求解模型,首先要解决的第一个问题就是 P(wi,wj),P(wi),P(wj) 该怎么算呢?
P(wi),P(wj) 简单,直接统计估计就行了,但 P(wi,wj) 呢?怎样的两个词才算是共现了?
当然,事实上不同的用途可以有不同的方案,比如我们可以认为同出现在一篇文章的两个词就是碰过一次面了,这种方案通常会对主题分类很有帮助,不过这种方案计算量太大。更常用的方案是选定一个固定的整数,记为 window,每个词前后的 window 个词,都认为是跟这个词碰过面的。
一个值得留意的细节是:中心词与自身的共现要不要算进去?窗口的定义应该是跟中心词距离不超过 window 的词,那么应该要把它算上的,但如果算上,那没什么预测意义,因为这一项总是存在,如果不算上,那么会降低了词与自身的互信息。
所以我们采用了一个小 trick:不算入相同的共现项,让模型自己把这个学出来。也就是说,哪怕上下文(除中心词外)也出现了中心词,也不算进 loss中,因为数据量本身是远远大于参数量的,所以这一项总可以学习出来。
权重和降采样
GloVe 模型定义了如下的权重公式::

其中 Xij 代表词对 (wi,wj) 的共现频数,Xmax,α 是固定的常数,通常取 Xmax=100,α=3/4,也就是说,要对共现频数低的词对降权,它们更有可能是噪音,所以最后 GloVe 的 loss 是:

在本文的模型中,继续沿用这一权重,但有所选择。首先,对频数作 α 次幂,相当于提高了低频项的权重,这跟 word2vec 的做法基本一致。值得思考的是 min 这个截断操作,如果进行这个截断,那么相当于大大降低了高频词的权重,有点像 word2vec 中的对高频词进行降采样,能够提升低频词的学习效果。
但可能带来的后果是:高频词的模长没学好。我们可以在《模长的含义》这一小节中看到这一点。总的来说,不同的场景有不同的需求,因此我们在最后发布的源码中,允许用户自定义是否截断这个权重。
Adagrad
跟 GloVe 一样,我们同样使用 Adagrad 算法进行优化,使用 Adagrad 的原因是因为它大概是目前最简单的自适应学习率的算法。
但是,我发现 GloVe 源码中的 Adagrad 算法写法是错的。我不知道 GloVe 那样写是刻意的改进,还是笔误(感觉也不大可能笔误吧?)。
总之,如果我毫不改动它的迭代过程,照搬到本文的 Simpler GloVe 模型中,很容易就出现各种无解的 nan,如果写成标准的 Adagrad,nan 就不会出现了。
选定一个词对 wi,wj 我们得到 loss:

它的梯度是:
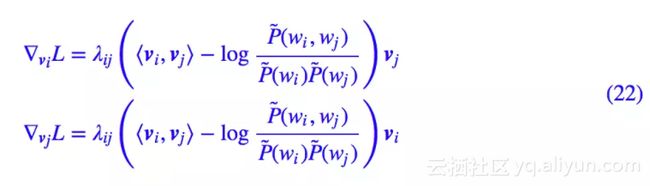
然后根据 Adagrad 算法的公式进行更新即可,默认的初始学习率选为 η=0.1,迭代公式为:

根据公式可以看出,Adagrad 算法基本上是对 loss 的缩放不敏感的,换句话说,将 loss 乘上 10 倍,最终的优化效果基本没什么变化,但如果在随机梯度下降中,将 loss 乘上 10 倍,就等价于将学习率乘以 10 了。
有趣的结果
最后,我们来看一下词向量模型(15)会有什么性质,或者说,如此煞费苦心去构造一个新的词向量模型,会得到什么回报呢?
模长的含义
似乎所有的词向量模型中,都很少会关心词向量的模长。有趣的是,我们上述词向量模型得到的词向量,其模长还能在一定程度上代表着词的重要程度。我们可以从两个角度理解这个事实。
在一个窗口内的上下文,中心词重复出现概率其实是不大的,是一个比较随机的事件,因此可以粗略地认为:

所以根据我们的模型,就有:
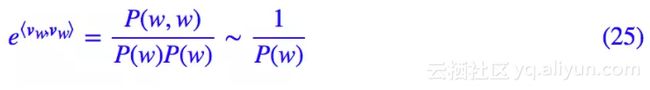
所以:
![]()
可见,词语越高频(越有可能就是停用词、虚词等),对应的词向量模长就越小,这就表明了这种词向量的模长确实可以代表词的重要性。事实上,−logP(w) 这个量类似 IDF,有个专门的名称叫 ICF,请参考论文《TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams》。
然后我们也可以从另一个角度来理解它,先把每个向量分解成模长和方向:

其中 |v| 模长是一个独立参数,方向向量 v/‖v‖ 是 n−1 个独立参数,n 是词向量维度。由于参数量差别较大,因此在求解词向量的时候,如果通过调整模长就能达到的,模型自然会选择调整模长而不是拼死拼活调整方向。因此,我们有:

对于像“的”、“了”这些几乎没有意义的词语,词向量会往哪个方向发展呢?前面已经说了,它们的出现频率很高,但本身几乎没有跟谁是固定搭配的,基本上就是自己周围逛,所以可以认为对于任意词 wi,都有

为了达到这个目的,最便捷的方法自然就是 ‖v的‖≈0 了,调整一个参数就可以达到,模型肯定乐意。也就是说对于频数高但是互信息整体都小的词语(这部分词语通常没有特别的意义),模长会自动接近于 0,所以我们说词向量的模长能在一定程度上代表词的重要程度。
在用本文的模型和百度百科语料训练的一份词向量中,不截断权重,把词向量按照模长升序排列,前 50 个的结果是:
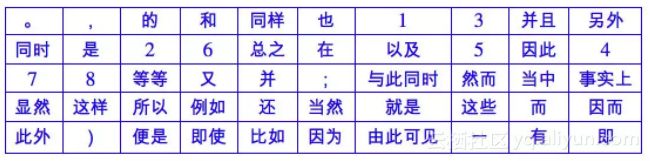
可见这些词确实是我们称为“停用词”或者“虚词”的词语,这就验证了模长确实能代表词本身的重要程度。这个结果与是否截断权重有一定关系,因为截断权重的话,得到的排序是:
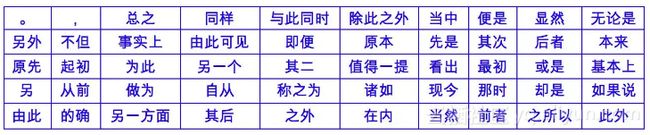
两个表的明显区别是,在第二个表中,虽然也差不多是停用词,但是一些更明显的停用词,如“的”、“是”等反而不在前面,这是因为它们的词频相当大,因此截断造成的影响也更大,因此存在拟合不充分的可能性(简单来说,更关注了低频词,对于高频词只是“言之有理即可”。)。
那为什么句号和逗号也很高频,它们又上榜了?因为一句话的一个窗口中,出现两次句号“。”的概率远小于出现两次“的”的概率,因此句号“。”的使用更加符合我们上述推导的假设,而相应地,由于一个窗口也可能出现多次“的”,因此“的”与自身的互信息应该更大,所以模长也会偏大。
词类比实验
既然我们号称词类比性质就是本模型的定义,那么该模型是否真的在词类比中表现良好?我们来看一些例子。

这里还想说明一点,词类比实验,有些看起来很漂亮,有些看起来不靠谱,但事实上,词向量反映的是语料的统计规律,是客观的。而恰恰相反,人类所定义的一些关系,反而才是不客观的。
对于词向量模型来说,词相近就意味着它们具有相似的上下文分布,而不是我们人为去定义它相似。所以效果好不好,就看“相似的上下文分布 ⇆ 词相近”这一观点(跟语料有关),跟人类对相近的定义(跟语料无关,人的主观想法)有多大差别。当发现实验效果不好时,不妨就往这个点想想。
相关词排序
留意式(15),也就是两个词的互信息等于它们词向量的内积。互信息越大,表明两个词成对出现的几率越大,互信息越小,表明两个词几乎不会在一起使用。因此,可以用内积排序来找给定词的相关词。
当然,内积是把模长也算进去了,而刚才我们说了模长代表的是词的重要程度,如果我们不管重要程度,而是纯粹地考虑词义,那么我们会把向量的范数归一后再求内积,这样的方案更加稳定:

根据概率论的知识,我们知道如果互信息为 0,也就是两个词的联合概率刚好就是它们随机组合的概率,这表明它们是无关的两个词。对应到式(15),也就是两个词的内积为 0。
而根据词向量的知识,两个向量的内积为 0,表明两个向量是相互垂直的,而我们通常说两个向量垂直,表明它们就是无关的。所以很巧妙,两个词统计上的无关,正好对应着几何上的无关。这是模型形式上的美妙之一。
需要指出的是,前面已经提到,停用词会倾向于缩小模长而非调整方向,所以它的方向就没有什么意义了,我们可以认为停用词的方向是随机的。这时候我们通过余弦值来查找相关词时,就有可能出现让我们意外的停用词了。
重新定义相似
注意上面我们说的是相关词排序,相关词跟相似词不是一回事。比如“单身”、“冻成”都跟“狗”很相关,但是它们并不是近义词;“科学”和“发展观”也很相关,但它们也不是近义词。
那么如何找近义词?事实上这个问题是本末倒置的,因为相似的定义是人为的,比如“喜欢”和“喜爱”相似,那“喜欢”和“讨厌”呢?如果在一般的主题分类任务中它们应当是相似的,但是在情感分类任务中它们是相反的。再比如“跑”和“抓”,一般情况下我们认为它们不相似,但如果在词性分类中它们是相似的,因为它们具有相同的词性。
回归到我们做词向量模型的假设,就是词的上下文分布来揭示词义。所以说,两个相近的词语应该具有相近的上下文分布,前面我们讨论的“机场-飞机+火车=火车站”也是基于同样原理,但那里要求了上下文单词一一严格对应,而这里只需要近似对应,条件有所放宽,而且为了适应不同层次的相似需求,这里的上下文也可以由我们自行选择。
具体来讲,对于给定的两个词 wi,wj 以及对应的词向量 vi,vj,我们要算它们的相似度,首先我们写出它们与预先指定的 N 个词的互信息,即:

和:

这里的 N 是词表中词的总数。如果这两个词是相似的,那么它们的上下文分布应该也相似,所以上述两个序列应该具有线性相关性,所以我们不妨比较它们的皮尔逊积矩相关系数:

其中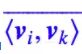 是 ⟨vi,vk⟩ 的均值,即:
是 ⟨vi,vk⟩ 的均值,即:

所以相关系数公式可以简化为:

用矩阵的写法(假设这里的向量都是行向量),我们有:
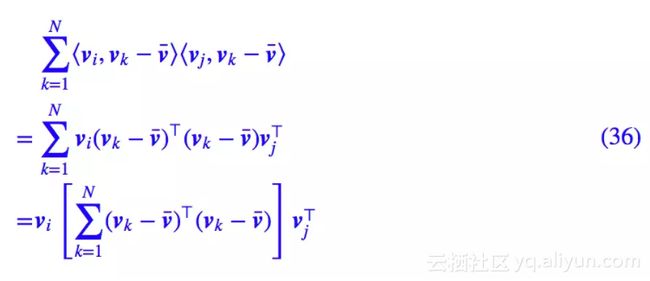
方括号这一块又是什么操作呢?事实上它就是:

也就是将词向量减去均值后排成一个矩阵 V,然后算 V⊤V,这是一个 n×n 的实对称矩阵,n 是词向量维度,它可以分解(Cholesky分解)为:

其中 U 是 n×n 的实矩阵,所以相关系数的公式可以写为:

我们发现,相似度还是用向量的余弦值来衡量,只不过要经过矩阵 U 的变换之后再求余弦值。
最后,该怎么选择这 N 个词呢?我们可以按照词频降序排列,然后选择前 N 个。
如果 N 选择比较大(比如 N=10000),那么得到的是一般场景下语义上的相关词,也就是跟前一节的结果差不多;如果 N 选择比较小,如 N=500,那么得到的是语法上的相似词,比如这时候“爬”跟“掏”、“捡”、“摸”都比较接近。
关键词提取
所谓关键词,就是能概括句子意思的词语,也就是说只看关键词也大概能猜出句子的整体内容。假设句子具有 k 个词 w1,w2,…,wk,那么关键词应该要使得:

最大,说白了,就是用词来猜句子的概率最大,而因为句子是预先给定的,因此 P(w1,w2,…,wk) 是常数,所以最大化上式左边等价于最大化右边。继续使用朴素假设:

代入我们的词向量模型,就得到:

所以最后等价于最大化:

现在问题就简单了,进来一个句子,把所有词的词向量求和得到句向量,然后句向量跟句子中的每一个词向量做一下内积(也可以考虑算 cos 得到归一化的结果),降序排列即可。简单粗暴,而且将原来应该是 ?(k2) 效率的算法降到了 ?(k)。效果呢?下面是一些例子。

可以发现,哪怕是对于长句,这个方案还是挺靠谱的。值得注意的是,虽然简单粗暴,但这种关键词提取方案可不是每种词向量都适用的,GloVe 词向量就不行,因为它的停用词模长更大,所以 GloVe 的结果刚刚是相反的:内积(或 cos)越小才越可能是关键词。
句子的相似度
让我们再看一例,这是很多读者都会关心的句子相似度问题,事实上它跟关键词提取是类似的。
两个句子什么时候是相似的甚至是语义等价的?简单来说就是看了第一个句子我就能知道第二个句子说什么了,反之亦然。这种情况下,两个句子的相关度必然会很大。设句子 S1 有 k 个词w1,w2,…,wk,句子 S2 有 l 个词 wk+1,wk+2,…,wk+l,利用朴素假设得到:

代入我们的词向量模型,得到:

所以最后等价于排序:

最终的结果也简单,只需要将两个句子的所有词相加,得到各自的句向量,然后做一下内积(同样的,也可以考虑用 cos 得到归一化的结果),就得到了两个句子的相关性了。
句向量
前面两节都暗示了,通过直接对词向量求和就可以得到句向量,那么这种句向量质量如何呢?
我们做了个简单的实验,通过词向量(不截断版)求和得到的句向量+线性分类器(逻辑回归),可以在情感分类问题上得到 81% 左右的准确率,如果中间再加一个隐层,结构为输入 128(这是词向量维度,句向量是词向量的求和,自然也是同样维度)、隐层 64(relu 激活)、输出 1(而分类),可以得到 88% 左右的准确率。
相比之下,LSTM 的准确率是 90% 左右,可见这种句向量是可圈可点的。要知道,用于实验的这份词向量是用百度百科的语料训练的,也就是说,本身是没有体现情感倾向在里边的,但它依然成功地、简明地挖掘了词语的情感倾向。
同时,为了求证截断与否对此向量质量的影响,我们用截断版的词向量重复上述实验,结果是逻辑回归最高准确率为 82%,同样的三层神经网络,最高准确率为 89%,可见,截断(也就是对高频词大大降权),确实能更好地捕捉语义。

代码、分享与结语
代码I
本文的实现位于:
https://github.com/bojone/simpler_glove
源码修改自斯坦福的 GloVe 原版,笔者仅仅是小修改,因为主要的难度是在统计共现词频这里,感谢斯坦福的前辈们提供了这一个经典的、优秀的统计实现案例。事实上,笔者不熟悉 C 语言,因此所作的修改可能难登大雅之台,万望高手斧正。
此外,为了实现上一节的“有趣的结果”,在 github 中我还补充了 simpler_glove.py,里边封装了一个类,可以直接读取 C 版的 simpler glove 所导出的模型文件(txt 格式),并且附带了一些常用函数,方便调用。
代码II
这里有一份利用本文的模型训练好的中文词向量,预料训练自百科百科,共 100 万篇文章,约 30w 词,词向量维度为 128。其中分词时做了一个特殊的处理:把所有数字和英文都拆成单个的数字和字母了。如果需要实验的朋友可以下载:
链接:http://pan.baidu.com/s/1jIb3yr8
密码:1ogw
结语
本文算是一次对词向量模型比较完整的探索,也算是笔者的理论强迫症的结果,幸好最后也得到了一个理论上比较好看的模型,初步治愈了我这个强迫症。而至于实验效果、应用等等,则有待日后进一步使用验证了。
本文的大多数推导,都可以模仿地去解释 word2vec 的 skip gram 模型的实验结果,读者可以尝试。事实上,word2vec 的 skip gram 模型确实跟本文的模型有着类似的表现,包括词向量的模型性质等。
原文发布时间为:2017-11-30
本文作者:苏剑林
本文来自云栖社区合作伙伴“PaperWeekly”,了解相关信息可以关注“PaperWeekly”微信公众号