pytorch 使用netron可视化
接上一篇博客,如果你没有看上一篇 ,请看上一篇,然后再继续下面的工作。
上一篇博客的地址:
(100条消息) pytorch使用tensorboard可视化(完整版)_Vertira的博客-CSDN博客
首先是保存模型,只需要在上面的代码最后加上一句,就会生成一个pt文件,然后就可以打开netron进行可视化了
# 2. 保存成pt文件后进行可视化
torch.save(modelviz, "./log/modelviz.pt")这些代码 再上一篇中都已经提供。
只需要重新安装netron,运行即可
安装netron
pip install netron -i https://pypi.tuna.tsinghua.edu.cn/simplenetron介绍
netron是一个深度学习模型可视化库,其支持以下格式的模型存储文件:
ONNX (.onnx, .pb)
Keras (.h5, .keras)
CoreML (.mlmodel)
TensorFlow Lite (.tflite)
netron并不支持pytorch通过torch.save方法导出的模型文件,因此在pytorch保存模型的时候,需要将其导出为onnx格式的模型文件,可以利用torch.onnx模块实现这一目标。
整体的流程分为两步:
第一步,pytorch导出onnx格式的模型文件。
第二步,netron载入模型文件,进行可视化。
1. pytorch导出onnx格式模型文件
pytorch导出onnx格式模型文件直接使用torch.onnx中相关方法即可,除了定义一个模型外,还需要传入一个数据样例:
import torchvision.models as models
import torch
# 定义样例数据+网络
data = torch.randn(2, 3, 256, 256)
net = models.resnet34()
# 导出为onnx格式
torch.onnx.export(
net,
data,
'model.onnx',
export_params=True,
opset_version=8,
)
导出的模型文件为model.onnx。
2. netron可视化
netron提供了两种运行方式。
(1)netron软件打开
第一种是以软件的方式安装netron,然后打开软件载入模型,下载地址见github主页。
(2)netron第三方库
第二种是将netron作为python库进行安装,在python代码调用netron库来载入模型进行可视化。 可以通过 pip install netron进行安装。
新建一个modelView.py文件,代码如下。一定要注意文件路径的问题
# 使用netron进行模型可视化
import netron
# 模型的路径
modelPath = "trained_models/simpler_CNN.01-0.32.hdf5"
# 启动模型
netron.start(modelPath)
随后运行modelView.py文件。生成如下地址

浏览器打开该地址。出现我们训练的模型可视图了

其中,输入图片是 n * h * w * c 形式,每层卷积操作的数据是 kernel_h * kernel_w * in_channels * out_channels
3)netron在线网站
- 如果你既不想安装netron软件,也不想安装netron库,netron作者很贴心地做了一个在线demo网站,可以直接上传模型文件查看可视化结果。
将刚才的model.onnx进行上传,结果如下:
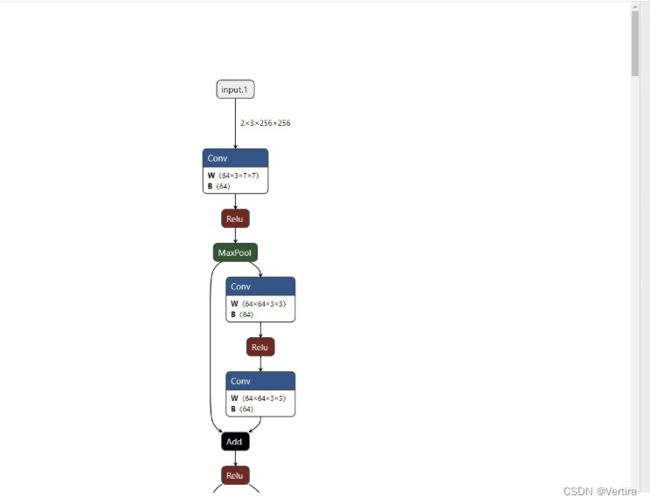
点击模块可以在右侧查看模块信息,例如卷积核的大小,卷积核的具体参数等。dilation在torch的cov2d() 里默认是1,>=2时,才是真正的空洞卷积。详见下面补充内容。
如果仔细看下结果,可以发现图中没有特征图的维度,只有输入数据的维度(3,256,256)。在netron中,如果想看到特征图的维度,需要在导出为onnx的时候,同时加上特征图维度信息。这个操作需要onnx库的帮助,可以通过pip install onnx进行安装。具体代码如下:
import torchvision.models as models
import torch
import onnx
import onnx.utils
import onnx.version_converter
# 定义数据+网络
data = torch.randn(2, 3, 256, 256)
net = models.resnet34()
# 导出
torch.onnx.export(
net,
data,
'model.onnx',
export_params=True,
opset_version=8,
)
# 增加维度信息
model_file = 'model.onnx'
onnx_model = onnx.load(model_file)
onnx.save(onnx.shape_inference.infer_shapes(onnx_model), model_file)
相比之前的代码,多了一个增加维度信息的步骤。此时可视化图中就能完整显示所有特征图的维度了。

注意:Pytorch中的Conv2d的对应函数(Tensor通道排列顺序是:[batch, channel, height, width]):
torch.nn.Conv2d(in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros')
想说的是其中的dilation这个参数,可以看到其默认值为1。先贴一段官方文档中对该参数的表述:
它有点类似于stride,实际含义为:每个点之间有空隙的过滤器,即为dilation。
例如,在一个维度上,一个大小为3的过滤器w会对输入的x进行如下计算:w[0] * x[0] + w[1] * x[1] + w[2] * x[2]。若dilation = 1,过滤器会计算:w[0] * x[0] + w[1] * x[2] + w[2] * x[4];
换句话说,在不同点之间有一个1的差距。(Pytoch中dilation默认等于1,但是实际为不膨胀,也就是说设置dilation = 2时才会真正进行膨胀操作)
这在某些情况下与0-dilated滤波器一起使用非常有用,因为它允许你用更少的层来更积极地合并整个输入的空间信息。例如,如果你把两个3 x 3的CONV层叠在一起,那么可以说,第二层的神经元是一个5x5的输入补丁的函数(我们会说这些神经元的有效感受野是5x5)。如果我们使用dilation的卷积,那么这个有效感受野会增长得更快。
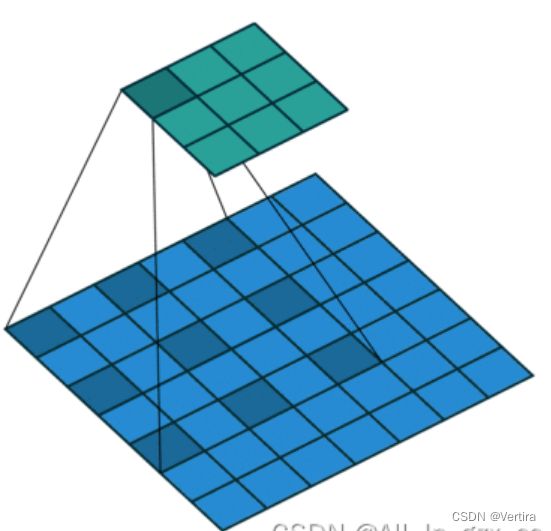
这种情况实际为Pytorch中,dilation = 2的情况。
特别注意:在Pytorch中,dilation = 1等同于没有dilation的标准卷积。参考:
PyTorch下的可视化工具 - 知乎 (zhihu.com)