深度学习-Tensorflow2.2-Tensorboard可视化{5}-可视化基础-17
Tensorboard可视化简介
TensorBoard是一款为了更方便 TensorFlow 程序的理解、调试与优化发布的可视化工具。你可以用 TensorBoard 来展现你的 TensorFlow 图像,绘制图像生成的定量指标图以及附加数据。
TensorBoard 通过读取 TensorFlow 的事件文件来运行。
TensorFlow 的事件文件包括了你会在 TensorFlow 运行中涉及到的主要数据。
Tensorboard随着tensorflow的安装一并被安装好
Tensorboard主要内容
一、通过 tf.keras 回调函数使用tensorboard
二、认识 tensorbaord界面
三、在 tf.keras回调函数中记录自定义变量
四、在自定义循环中使用tensorboard
import tensorflow as tf
import os
import datetime
(train_image,train_labels),(test_image,test_labels)=tf.keras.datasets.mnist.load_data()
train_image.shape,train_labels,test_image.shape,test_labels

train_image = tf.expand_dims(train_image,-1)# 扩充维度
test_image = tf.expand_dims(test_image,-1)# 扩充维度
train_image.shape,test_image.shape
![]()
# 改变数据类型
train_image = tf.cast(train_image/255,tf.float32) # 归一化并改变数据类型
train_labels = tf.cast(train_labels,tf.int64)
test_image = tf.cast(test_image/255,tf.float32) # 归一化并改变数据类型
test_labels = tf.cast(test_labels,tf.int64)
train_dataset = tf.data.Dataset.from_tensor_slices((train_image,train_labels)) # 建立数据集
test_dataset = tf.data.Dataset.from_tensor_slices((test_image,test_labels))
train_dataset,test_dataset

train_dataset = train_dataset.repeat().shuffle(60000).batch(128) # 对数据进行洗牌
test_dataset = test_dataset.repeat().batch(128) # 对数据进行洗牌
train_dataset,test_dataset

# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3],activation="relu",input_shape=(None,None,1)),
tf.keras.layers.Conv2D(32,[3,3],activation="relu"),
tf.keras.layers.GlobalMaxPool2D(),
tf.keras.layers.Dense(10,activation="softmax")
])
# 编译模型
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["acc"])
log_dir = os.path.join("logs",datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))# 图的存放路径加时间
# 可视化
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir,histogram_freq=1)
# 训练
model.fit(train_dataset,
epochs=5,
steps_per_epoch=60000//128,
validation_data=test_dataset,
validation_steps=10000//128,
callbacks=[tensorboard_callback])

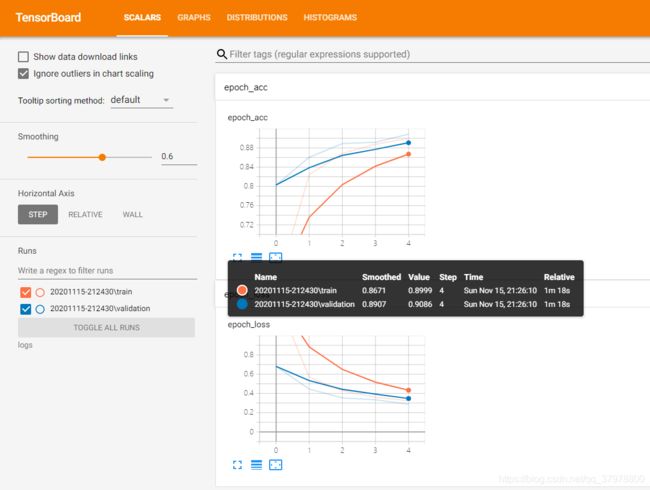
SCALARS 面板主要用于记录诸如准确率、损失和学习率等单个值的变化趋势。在代码中用 tf.summary.scalar() 来将其记录到文件中
每个图的右下角都有 3 个小图标,第一个是查看大图,第二个是是否对 y 轴对数化,第三个是如果你拖动或者缩放了坐标轴,再重新回到原始位置。
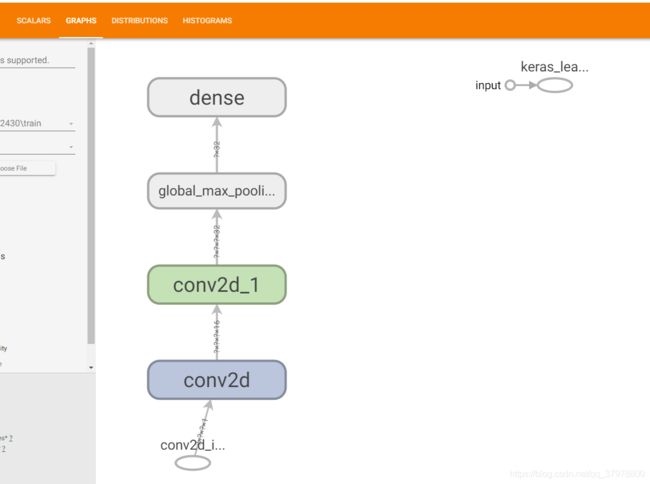
GRAPHS 面板展示出你所构建的网络整体结构,显示数据流的方向和大小,也可以显示训练时每个节点的用时、耗费的内存大小以及参数多少。默认显示的图分为两部分:主图(Main Graph)和辅助节点(Auxiliary Nodes)。其中主图显示的就是网络结构,辅助节点则显示的是初始化、训练、保存等节点。我们可以双击某个节点或者点击节点右上角的 + 来展开查看里面的情况,也可以对齐进行缩放
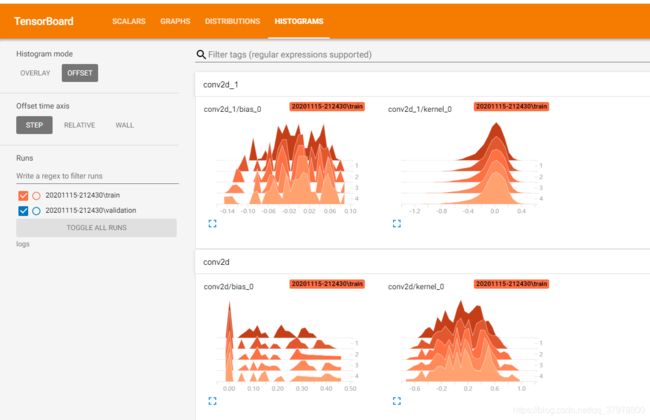
DISTRIBUTIONS 主要用来展示网络中各参数随训练步数的增加的变化情况,可以说是 多分位数折线图 的堆叠。
HISTOGRAMS 和 DISTRIBUTIONS 是对同一数据不同方式的展现。与 DISTRIBUTIONS 不同的是,HISTOGRAMS 可以说是 频数分布直方图 的堆叠。

记录自定义标量
重新调整回归模型并记录自定义学习率。这是如何做:
使用创建文件编写器tf.summary.create_file_writer()。
定义自定义学习率功能。这将被传递给Keras LearningRateScheduler回调。
在学习率功能内,用于tf.summary.scalar()记录自定义学习率。
将LearningRateScheduler回调传递给Model.fit()。
通常,要记录自定义标量,您需要使用tf.summary.scalar()文件编写器。文件编写器负责将此运行的数据写入指定的目录,并在使用时隐式使用tf.summary.scalar()。
import tensorflow as tf
import os
import datetime
(train_image,train_labels),(test_image,test_labels)=tf.keras.datasets.mnist.load_data()
print(train_image.shape,train_labels,test_image.shape,test_labels)
train_image = tf.expand_dims(train_image,-1)# 扩充维度
test_image = tf.expand_dims(test_image,-1)# 扩充维度
train_image.shape,test_image.shape
# 改变数据类型
train_image = tf.cast(train_image/255,tf.float32) # 归一化并改变数据类型
train_labels = tf.cast(train_labels,tf.int64)
test_image = tf.cast(test_image/255,tf.float32) # 归一化并改变数据类型
test_labels = tf.cast(test_labels,tf.int64)
train_dataset = tf.data.Dataset.from_tensor_slices((train_image,train_labels)) # 建立数据集
test_dataset = tf.data.Dataset.from_tensor_slices((test_image,test_labels))
print(train_dataset,test_dataset)
train_dataset = train_dataset.repeat().shuffle(60000).batch(128) # 对数据进行洗牌
test_dataset = test_dataset.repeat().batch(128) # 对数据进行洗牌
print(train_dataset,test_dataset)
# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3],activation="relu",input_shape=(None,None,1)),
tf.keras.layers.Conv2D(32,[3,3],activation="relu"),
tf.keras.layers.GlobalMaxPool2D(),
tf.keras.layers.Dense(10,activation="softmax")
])
# 编译模型
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["acc"])
log_dir = os.path.join("logs",datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))# 图的存放路径加时间
file_writer = tf.summary.create_file_writer(log_dir + "/lr")
file_writer.set_as_default()
def lr_sche(epoch):
learning_rate = 0.2 # 默认速率0.2
if epoch > 5 :
learning_rate = 0.02
if epoch > 10 :
learning_rate = 0.01
if epoch > 20:
learning_rate = 0.005
tf.summary.scalar("leaning_rate",data = learning_rate,step=epoch)
return learning_rate
# 可视化
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir,histogram_freq=1)
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_sche)
# 训练
model.fit(train_dataset,
epochs=25,
steps_per_epoch=60000//128,
validation_data=test_dataset,
validation_steps=10000//128,
callbacks=[tensorboard_callback,lr_callback])
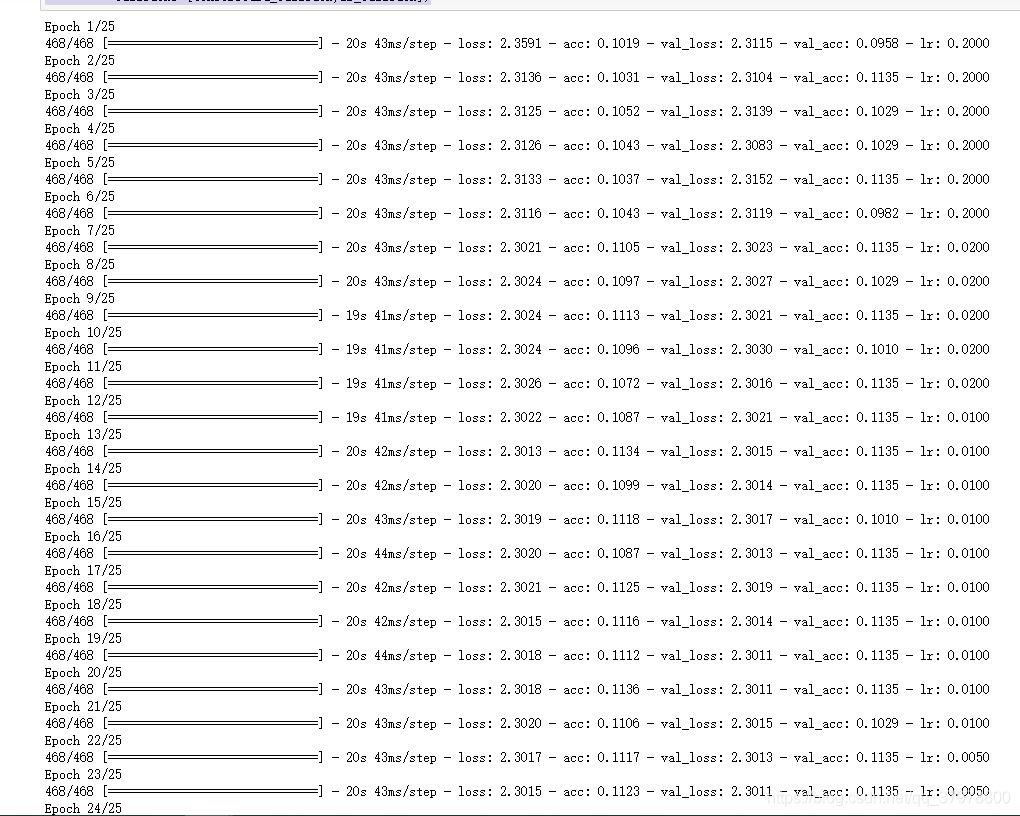
自定义训练中使用tensorboard
import tensorflow as tf
import os
import datetime
(train_image,train_labels),(test_image,test_labels)=tf.keras.datasets.mnist.load_data()# 划分数据集
train_image = tf.expand_dims(train_image,-1)# 扩充维度
test_image = tf.expand_dims(test_image,-1)# 扩充维度
# 改变数据类型
train_image = tf.cast(train_image/255,tf.float32) # 归一化并改变数据类型
train_labels = tf.cast(train_labels,tf.int64)
test_image = tf.cast(test_image/255,tf.float32) # 归一化并改变数据类型
test_labels = tf.cast(test_labels,tf.int64)
train_dataset = tf.data.Dataset.from_tensor_slices((train_image,train_labels)) # 建立数据集
test_dataset = tf.data.Dataset.from_tensor_slices((test_image,test_labels))
train_dataset = train_dataset.repeat().shuffle(60000).batch(128) # 对数据进行洗牌
test_dataset = test_dataset.repeat().batch(128) # 对数据进行洗牌
print(train_dataset,test_dataset)
# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16,[3,3],activation="relu",input_shape=(None,None,1)),
tf.keras.layers.Conv2D(32,[3,3],activation="relu"),
tf.keras.layers.GlobalMaxPool2D(),
tf.keras.layers.Dense(10) # 未激活
])
# 自定义循环(编译)
optimizers = tf.keras.optimizers.Adam() # 优化函数
loss_func = tf.keras.losses.SparseCategoricalCrossentropy() # 损失函数
def loss(model,x,y):
y_ = model(x)
return loss_func(y,y_)
train_loss = tf.keras.metrics.Mean("train_loss")
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy("train_accuracy")
train_loss = tf.keras.metrics.Mean("test_loss")
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy("test_accuracy")
def train_step(model,images,labels):
with tf.GradientTape() as t:
pred = model(images)
loss_step = loss_func(labels,pred)
grads = t.gradient(loss_step,model.trainable_variables)
optimizers.apply_gradients(zip(grads,model.trainable_variables))
train_loss(loss_step)
train_accuracy(labels,pred)
def test_step(model,images,labels):
with tf.GradientTape() as t:
pred = model(images)
loss_step = loss_func(labels,pred)
grads = t.gradient(loss_step,model.trainable_variables)
optimizers.apply_gradients(zip(grads,model.trainable_variables))
train_loss(loss_step)
train_accuracy(labels,pred)
log_dir = os.path.join("logs",datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))# 图的存放路径加时间
train_log_dir = "logs/gradient_tape" + log_dir + "train"
test_log_dir = "logs/gradient_tape" + log_dir + "test"
train_writer = tf.summary.create_file_writer(train_log_dir)
test_writer = tf.summary.create_file_writer(test_log_dir)
def train():
for epoch in range(10):
for (batch, (images, labels)) in enumerate(train_dataset):
train_step(model, images, labels)
print('.', end='')
with train_writer.as_default():
tf.summary.scalar('loss', train_loss.result(), step=epoch)
tf.summary.scalar('accuracy', train_accuracy.result(), step=epoch)
for (batch, (images, labels)) in enumerate(test_dataset):
test_step(model, images, labels)
print('*', end='')
with test_writer.as_default():
tf.summary.scalar('loss', test_loss.result(), step=epoch)
tf.summary.scalar('accuracy', test_accuracy.result(), step=epoch)
template = 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
train()