BERT 论文解读
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
论文地址:https://arxiv.org/abs/1810.04805
代码地址:https://github.com/google-research/bert
Abstract
BERT (Bidirectional Encoder Representations from Transformers) 在未标记的文本上进行预训练,调节各个层的参数,学习上下文表示。因此只需要增加一个输出层进行微调,就能在多个任务上达到 SOTA 水平。
1 简介
将预训练语言模型应用在下游任务中,一般有两种策略:feature-based 和 fine-tuning。feature-based 例子是 ELMo,fine-tuning 例子是 GPT。作者认为影响当前预训练语言模型的瓶颈是——“模型是单向的”。如 GPT 选择从左到右的架构,这使得每个 token 只能注意到它前面的 token,这对 sentence 级的任务影响还是次要的,但对于 token 级的任务来说影响就很巨大。
BERT 通过使用受完形填空任务启发的 Mask Language Model (MLM)缓解了先前模型的单向性约束问题。MLM 随机 mask 掉一些输入文本中的 token,然后根据剩下的上下文预测 masked 的 token。除了 Mask Language Model,作者还提出了 Next Sequence Predict 任务,来联合训练文本对表示。
BERT 贡献在于:
- 证明了双向预训练对于语言表示模型的重要性
- 减少了为特定任务精心设计网络架构的必要性
- BERT 在11个 NLP 任务上达到了 SOTA 水平
2 BERT
BERT 模型有两个步骤:预训练、微调。预训练时,模型在不同的预训练任务中基于未标记数据进行训练;微调时,先使用预训练模型的参数初始化 BERT 模型,再在特定任务的标注数据上对参数进行微调。以问答为例,如下图所示:

[CLS] 是每个输入示例开头的特殊标记;[SEP] 是一个特殊的标记用于区分 question/answer
模型架构
BERT 的模型架构是一种多层的双向 transformer encoder,BERT 在实现上与 transformer encoder 几乎完全相同。
定义:transformer block 的个数为 L L L ; hidden 大小为 H H H ; self-attentions head 的个数为 A A A. 作者主要展示了两种规模的 BERT 模型:
| model | L L L | H H H | A A A |
|---|---|---|---|
| B E R T B A S E BERT_{BASE} BERTBASE | 12 | 768 | 12 |
| B E R T L A R G E BERT_{LARGE} BERTLARGE | 24 | 1024 | 16 |
输入输出表示
为了使 BERT 能处理大量不同的下游任务,作者将模型的输入设计成可以输入单个句子或句子对,这两种输入被建模成同一个 token 序列。作者使用了有 30000 个 token 的 vocabulary 词嵌入。
输入序列:第一个 token 都是一个特殊标记 [CLS],该标记的最终隐藏状态用来聚合句子的表征,从而实现分类任务。对于 sentence 对,作者使用特殊标记 [SEP] 来区分不同的句子。
输出序列:用 E E E 来表示输入的 embedding,[CLS] 的最终隐藏状态为 C ∈ R H C \in \R^H C∈RH,输入序列的第 i i i 个 token 的隐藏向量为 T i ∈ R H T_i \in \R^H Ti∈RH 。对于 T i T_i Ti ,都是通过 token embedding、segment embedding、position embedding 加和构造出来的。如下图所示:
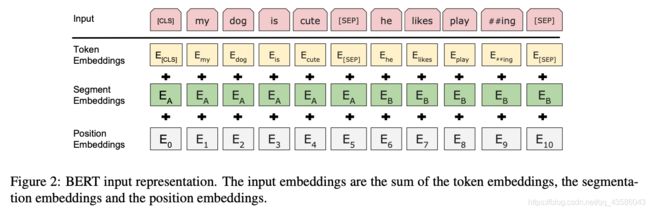
2.1 Pre-training BERT
Task #1: Masked LM
标准的语言模型只能实现从左到右或从右到左的训练,不能实现真正的双向训练,这是因为双向的条件是每个单词能直接“看到自己”,并且模型可以在多层上下文中轻松的预测出目标词。
为了能够实现双向的深度预训练,作者选择随机 mask 掉一些比例的 token,然后预测这些被 masked 的 token,在这种设置下,被 masked 的 token 的隐藏向量表示被输出到词汇表的 softmax 上,这就与标准语言模型设置相同。作者将这个过程称为“Masked LM”,也被称为“完形填空”。
Masked LM 预训练任务的缺点在于由于 [MASK] 标记不会出现在微调阶段,这就造成了预训练和微调阶段的不一致。为了解决该问题,作者提出了一种折中的方案:随机选择 15% 的 token,这些要被 masked 的 token 并不会真的全替换成 [MASK],而是从这些 token 中,随机选择 80% 替换成 [MASK] ;随机选择 10% 替换成随机 token;随机选择 10% 不改变原 token。然后 T i T_i Ti 使用交叉熵损失来预测原始的 token。
Task #2: Next Sentence Prediction (NSP)
很多下游任务都是基于对两句话之间的关系的理解,语言模型不能直接捕获这种信息。为了训练模型理解这种句间关系,作者设计了 next sentence prediction 的二分类任务。具体来说,就是选择两个句子作为一个训练样本,有 50% 的概率是下一句关系,有 50% 的概率是随机选择的句子对,预测将 [CLS] 的最终隐状态 C C C 输入 sigmoid 实现。
Pre-training data
作者选用了BooksCorpus (800M words) 和 English Wikipedia (2,500M words) 作为预训练的语料库,作者只选取了 Wikipedia 中的文本段落,忽略了表格、标题等。为了获取长的连续文本序列,作者选用了 BIllion Word Benchmark 这样的文档级语料库,而非打乱的句子级语料库。
2.2 Fine-tuning BERT
因为 transformer 中的 self-attention 机制适用于很多下游任务,所以可以直接对模型进行微调。对于涉及文本对的任务,一般的做法是独立 encode 文本对,然后再应用双向的 cross attention 进行交互。Bert 使用 self-attention 机制统一了这两个阶段,该机制直接能够实现两个串联句子的交叉编码。
对于不同的任务,只需要简单地将特定于该任务的输入输出插入到 Bert 中,然后进行 end2end 的fine-tuning。
- 对于输入,预训练中的 sentence A 和 sentence B 能够替换成:1)同义关系中的句子对;2)蕴含关系中的“假设-前提对”;3)问答中的“段落-问题对”;4)文本分类或序列标注中的“文本-null”
- 对于输出,对于 token-level 的任务,如序列标注、问答,将 Bert 输出的 token 编码输入到输出层;对于 sentence-level 的任务,如句子的蕴含关系、情感分析等,将
[CLS]作为输入序列的聚合编码,输入到输出层。
3 实验
3.1 GLUE
GLUE (General Language Understanding Evaluation) 是多个 NLP 任务的集合。作者设置 batch size 为 32;训练 3 个 epochs;在验证集上从(5e-5, 4e-5, 3e-5, 2e-5)中选择最优的学习率。结果如下:

其他实验略…
4 消融实验
4.1 预训练任务的影响
进行了如下消融测试:
- “No NSP” :不进行 nsp 任务,只进行 Masked LM task;
- “LTR & No NSP” :不进行 nsp 任务,且使用标准语言模型采用的 Left-to-Right 训练方法。
结果如下:

如果采用像 ELMo 那样训练 LTR 和 RTL 模型,再对结果进行拼接,有以下缺点:
- 相对于单个双向模型来说,表征长度翻倍,代价相对提高
- 这种拼接不直观,因为对于 QA 任务来说,RTL 任务做的事实际上是 “根据答案推导问题” 这是不靠谱的。
- 与深度双向模型相比,这种在上下文上的双向交互的能力较弱,因为双向模型在每层都能进行双向的上下文交互。
4.2 模型大小的影响
结果如下:
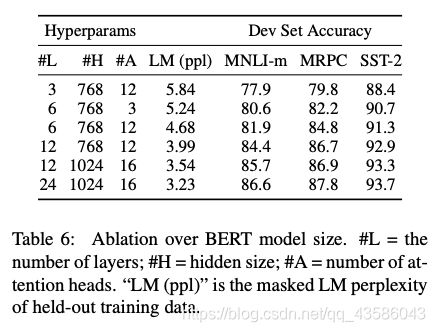
作者证明了:如果模型经过充分的预训练,即使模型尺寸扩展到很大,也能极大改进训练数据规模较小的下游任务。
4.3 将 Bert 应用于 Feature-based 的方法
feature-based 的方法是从预训练模型中提取固定的特征,不对具体任务进行微调。这样的方法也有一定的有点:1. 并非所有任务都能用 transformer 架构简单表示,因此这些任务都需要添加特定的架构;2. feature-based 的方法还有一定的计算成本优势。
作者进行了如下实验:在 CoNLL-2003 数据集上完成 NER 任务,不使用 CRF 输出,而是从一到多个层中提取出激活值,输入到 2 层 768 维的 BiLSTM 中,再直接分类。结果如下:
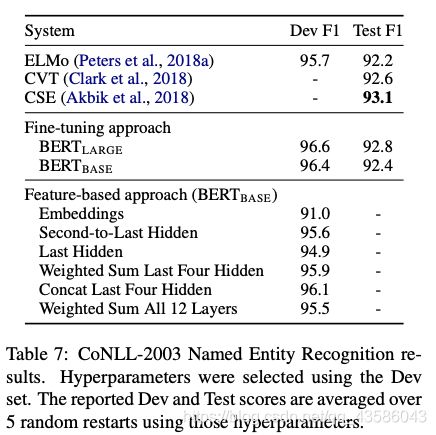
结果说明:无论是否进行微调,Bert 模型都是有效的。
5 总结
个人认为 Bert 的意义在于:
- 成功实践了 pre-training + fine-tuning 的深度学习范式;
- 发掘了在 NLP 中“深度双向架构”在预训练任务中的重要意义;