Tensorboard可视化-CNN手写数字识别的动态效果分类
目录
1.介绍
2.运行
3.使用简单神经网络
3.1分类之前
3.2分类之后
3.3准确率:
4.使用简单CNN
4.1分类之前:
4.2分类之后:
4.3准确率:
5.总结
代码附录
1.介绍
这两天跟着深度学习框架Tensorflow学习与应用视频,学习了TensorFlow框架和Tensorboard可视化工具,跑了一个手写数字识别的动态效果分类案例。
2.运行
在命令行输入:tensorboard --logdir="C:\Users\Administrator\Desktop\NN\深度学习框架Tensorflow学习与应用" 运行tensorboard面板。
3.使用简单神经网络
3.1分类之前
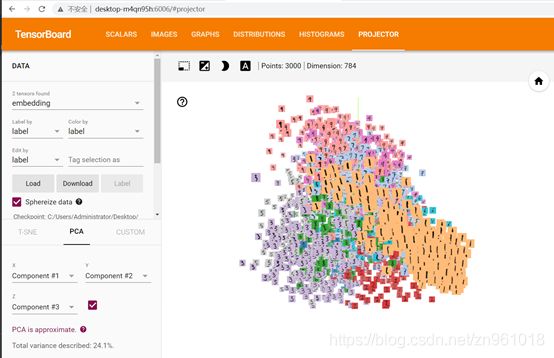
3.2分类之后
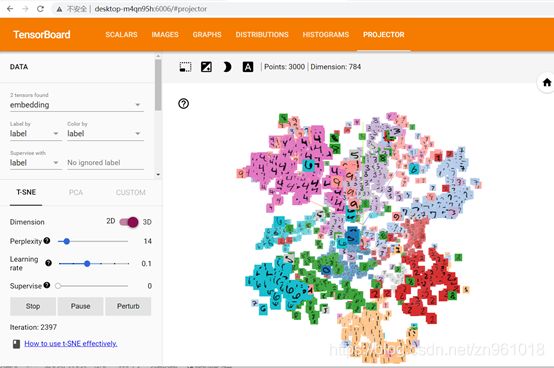
3.3准确率:
第1次迭代,accuracy = 0.280600 第101次迭代,accuracy = 0.806600 第201次迭代,accuracy = 0.842700 第301次迭代,accuracy = 0.879900 第401次迭代,accuracy = 0.893300 第501次迭代,accuracy = 0.896300 第601次迭代,accuracy = 0.900500 第701次迭代,accuracy = 0.902900 第801次迭代,accuracy = 0.902800 第901次迭代,accuracy = 0.906400 第1001次迭代,accuracy = 0.907200
4.使用简单CNN
4.1分类之前:

4.2分类之后:
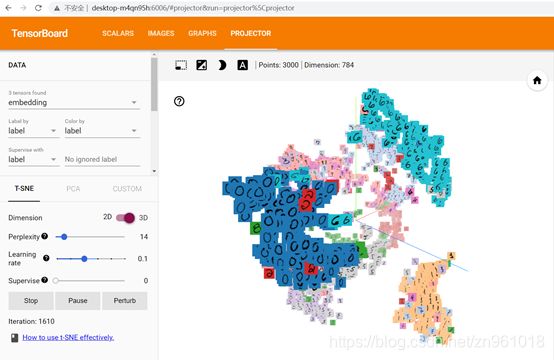
4.3准确率:
""" 第1次迭代,accuracy = 0.118600 第101次迭代,accuracy = 0.632500 第201次迭代,accuracy = 0.830600 第301次迭代,accuracy = 0.914300 第401次迭代,accuracy = 0.924800 第501次迭代,accuracy = 0.911900 第601次迭代,accuracy = 0.946200 第701次迭代,accuracy = 0.944200 第801次迭代,accuracy = 0.951600 第901次迭代,accuracy = 0.943100 第1001次迭代,accuracy = 0.952800 """
5.总结
可以看到使用CNN确实提高了测试集的准确率。而且当增加卷积核的数量,准确率可以进一步提升,有更好的分类效果,在本机电脑跑,我就设置小一点,不然太卡了。之后多加强对理论的理解和代码的实践。
代码附录
普通神经网络代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector
#载入数据集
my_mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
#运行次数
max_steps = 1001
#图片数量
image_num = 3000
#文件路径
DIR = r"C:/Users/Administrator/Desktop/NN/深度学习框架Tensorflow学习与应用/"
#创建会话
sess = tf.Session()
#载入测试集图片
embedding = tf.Variable(tf.stack(my_mnist.test.images[:image_num]),trainable=False,name="embedding")
#参数概要
#保存var的最小值最大值平均值标准差和直方图
def variable_summaries(var):
with tf.name_scope("summaries"):
mean = tf.reduce_mean(var)
tf.summary.scalar("mean",mean)
with tf.name_scope("stddev"):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar("stddev",stddev)
tf.summary.scalar("max",tf.reduce_max(var))
tf.summary.scalar("min",tf.reduce_min(var))
tf.summary.histogram("histogram",var)
#命名空间
with tf.name_scope("input"):
x = tf.placeholder(tf.float32,[None,784],name="x-input")
y = tf.placeholder(tf.float32,[None,10],name="y-input")
#显示图片
with tf.name_scope("input-reshape"):
image_shaped_input = tf.reshape(x,[-1,28,28,1])
tf.summary.image("input",image_shaped_input,10)
#训练层
with tf.name_scope("layer"):
#创建一个神经网络
with tf.name_scope("weights"):
W = tf.Variable(tf.zeros([784,10]),name="W")
variable_summaries(W)
with tf.name_scope("biases"):
b = tf.Variable(tf.zeros([10]),name="b")
with tf.name_scope("wx_plus_b"):
wx_plus_b = tf.matmul(x,W) + b
with tf.name_scope("softmax"):
prediction = tf.nn.softmax(wx_plus_b)
#代价函数
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
tf.summary.scalar("loss",loss)
#优化器
with tf.name_scope("train"):
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
#初始化变量
sess.run(tf.global_variables_initializer())
with tf.name_scope("accuracy"):
with tf.name_scope("correct_prediction"):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope("accracy"):
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.summary.scalar("accuracy",accuracy)
#产生metadata文件
if tf.gfile.Exists(DIR + "projector/projector/metadata.tsv"):
tf.gfile.DeleteRecursively(DIR + "projector/projector/metadata.tsv")
with open(DIR + "projector/projector/metadata.tsv","w") as f:
labels = sess.run(tf.argmax(my_mnist.test.labels[:],1))
for i in range(image_num):
f.write(str(labels[i]) + "\n")
#合并所有的summary
merged = tf.summary.merge_all()
projector_writer = tf.summary.FileWriter(DIR + "projector/projector",sess.graph)
saver = tf.train.Saver()
# 通过projector.ProjectorConfig类来帮助生成日志文件。
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果。
embed = config.embeddings.add()
# 指定这个embedding结果对应的TensorFlow变量名称。
embed.tensor_name = embedding.name
# 指定embedding结果所对应的原始数据信息。比如这里指定的就是每一张MNIST测试图片
# 对应的真实类别。在单词向量中可以是单词ID对应的单词。这个文件是可选的,如果没有指定
# 那么向量就没有标签。
embed.metadata_path = DIR + "projector/projector/metadata.tsv"
# 指定sprite图像。这个也是可选的,如果没有提供sprite图像,那么可视化的结果
# 每一个点就是一个小圆点,而不是具体的图片。
embed.sprite.image_path = DIR + "projector/data/mnist_10k_sprite.png"
# 在提供sprite图像时,通过single_image_dim可以指定单张图片的大小。
# 这将用于从sprite图像中截取正确的原始图片。
embed.sprite.single_image_dim.extend([28,28])
# 将PROJECTOR所需要的内容写入日志文件。
projector.visualize_embeddings(projector_writer,config)
for i in range(max_steps):
#每个批次100个样本
batch_xs,batch_ys = my_mnist.train.next_batch(100)
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary,_ = sess.run([merged,train_step],feed_dict={x:batch_xs,y:batch_ys},options=run_options,run_metadata=run_metadata)
# 生成会话,初始化新声明的变量并将需要的日志信息写入文件
projector_writer.add_run_metadata(run_metadata,"step%03d" % i)
projector_writer.add_summary(summary,i)
if i % 100 == 0:
acc = sess.run([accuracy],feed_dict={x:my_mnist.test.images,y:my_mnist.test.labels})
print("第%d次迭代,accuracy = %f" % (i + 1,acc[0]))
saver.save(sess,DIR + "projector/projector/a_model.ckpt",global_step=max_steps)
projector_writer.close()
sess.close()
使用CNN代码如下:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector
#载入数据集
my_mnist = input_data.read_data_sets("MNIST_data",one_hot=True)
#运行次数
max_steps = 1001
#图片数量
image_num = 3000
#文件路径
DIR = r"C:/Users/Administrator/Desktop/NN/CNN/"
#创建会话
sess = tf.Session()
#载入测试集图片
embedding = tf.Variable(tf.stack(my_mnist.test.images[:image_num]),trainable=False,name="embedding")
#初始化权值
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev=0.1)
return tf.Variable(initial)
#初始化偏置值
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#卷积层
def conv2d(x,W):
"""
:param x: batch:多少张图片 in_height:图片的高 in_width:图片的宽 in_channels:通道数 3通道还是单通道
input tensor of shape `[batch, in_height, in_width, in_channels]`
:param W: filter_height:卷积核的高 filter_width:卷积核的宽 in_channels:卷积核的通道数 out_channels:卷积核的个数
[filter_height, filter_width, in_channels, out_channels]
:return:
"""
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding="SAME")
#池化层
def max_pool_2x2(x):
"""
:param x:
需要池化的输入,一般池化层接在卷积层后面,
所以输入通常是feature map,
依然是[batch_size, height, width, channels]这样的shap
:param ksize:
k_size : 池化窗口的大小,取一个四维向量,
一般是[1, height, width, 1],因为我们不想在batch和channels上做池化,
所以这两个维度设为了1
:return:
"""
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
#参数概要
#保存var的最小值最大值平均值标准差和直方图
def variable_summaries(var):
with tf.name_scope("summaries"):
mean = tf.reduce_mean(var)
tf.summary.scalar("mean",mean)
with tf.name_scope("stddev"):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar("stddev",stddev)
tf.summary.scalar("max",tf.reduce_max(var))
tf.summary.scalar("min",tf.reduce_min(var))
tf.summary.histogram("histogram",var)
#命名空间
with tf.name_scope("input"):
x = tf.placeholder(tf.float32,[None,784],name="x-input")
y = tf.placeholder(tf.float32,[None,10],name="y-input")
#显示图片
with tf.name_scope("input-reshape"):
image_shaped_input = tf.reshape(x,[-1,28,28,1])
tf.summary.image("input",image_shaped_input,10)
#训练层
with tf.name_scope("layer"):
# 改变x的格式转为4D的向量
# [batch, in_height, in_width, in_channels]
x_image = tf.reshape(x, [-1, 28, 28, 1])
# 初始化第一个卷积层的权值和偏置值
# W_conv1为高宽为5 channel为1 4个数量的卷积核
W_conv1 = weight_variable([5, 5, 1, 4])
# 每个卷积核接一个偏置
b_conv1 = bias_variable([4])
# 第一层卷积+池化
# 把x_image和权值向量进行卷积,再加上偏置值,然后应用relu激活函数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# 卷积完进行池化
h_pool1 = max_pool_2x2(h_conv1)
# 第一层输出 [14,14,4]
# 第二层卷积+池化
# 第二层的卷积核 高为5 宽为5 通道数为4 数量为16
W_conv2 = weight_variable([5, 5, 4, 16])
b_conv2 = bias_variable([16])
# 把h_pool1和权值向量进行卷积,再加上偏置值,然后应用relu激活函数
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# 卷积完进行池化
h_pool2 = max_pool_2x2(h_conv2)
# 每张图片经过第二层输出[7,7,16]
# 初始化第一个全连接层的权值
W_fc1 = weight_variable([7 * 7 * 16, 16])
b_fc1 = bias_variable([16])
# 把初始化2的输出层扁平化为1维
b_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 16])
# 求第一个全连接层的输出
h_fc1 = tf.nn.relu(tf.matmul(b_pool2_flat, W_fc1) + b_fc1)
# keep_prob用来表示神经元的输出概率
keep_prob = tf.placeholder(tf.float32)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob=keep_prob)
# 初始化第二个全连接层
W_fc2 = weight_variable([16, 10])
b_fc2 = bias_variable([10])
# 计算输出
prediction_without_softmax = tf.matmul(h_fc1_drop, W_fc2) + b_fc2
prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
#代价函数
with tf.name_scope("loss"):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
tf.summary.scalar("loss",loss)
#优化器
with tf.name_scope("train"):
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
#初始化变量
sess.run(tf.global_variables_initializer())
with tf.name_scope("accuracy"):
with tf.name_scope("correct_prediction"):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope("accracy"):
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
tf.summary.scalar("accuracy",accuracy)
#产生metadata文件
if tf.gfile.Exists(DIR + "projector/projector/metadata.tsv"):
tf.gfile.DeleteRecursively(DIR + "projector/projector/metadata.tsv")
with open(DIR + "projector/projector/metadata.tsv","w") as f:
labels = sess.run(tf.argmax(my_mnist.test.labels[:],1))
for i in range(image_num):
f.write(str(labels[i]) + "\n")
#合并所有的summary
merged = tf.summary.merge_all()
projector_writer = tf.summary.FileWriter(DIR + "projector/projector",sess.graph)
saver = tf.train.Saver()
# 通过projector.ProjectorConfig类来帮助生成日志文件。
config = projector.ProjectorConfig()
# 增加一个需要可视化的embedding结果。
embed = config.embeddings.add()
# 指定这个embedding结果对应的TensorFlow变量名称。
embed.tensor_name = embedding.name
# 指定embedding结果所对应的原始数据信息。比如这里指定的就是每一张MNIST测试图片
# 对应的真实类别。在单词向量中可以是单词ID对应的单词。这个文件是可选的,如果没有指定
# 那么向量就没有标签。
embed.metadata_path = DIR + "projector/projector/metadata.tsv"
# 指定sprite图像。这个也是可选的,如果没有提供sprite图像,那么可视化的结果
# 每一个点就是一个小圆点,而不是具体的图片。
embed.sprite.image_path = DIR + "projector/data/mnist_10k_sprite.png"
# 在提供sprite图像时,通过single_image_dim可以指定单张图片的大小。
# 这将用于从sprite图像中截取正确的原始图片。
embed.sprite.single_image_dim.extend([28,28])
# 将PROJECTOR所需要的内容写入日志文件。
projector.visualize_embeddings(projector_writer,config)
for i in range(max_steps):
#每个批次100个样本
batch_xs,batch_ys = my_mnist.train.next_batch(100)
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary,_ = sess.run([merged,train_step],feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7},options=run_options,run_metadata=run_metadata)
# 生成会话,初始化新声明的变量并将需要的日志信息写入文件
projector_writer.add_run_metadata(run_metadata,"step%03d" % i)
projector_writer.add_summary(summary,i)
if i % 100 == 0:
acc = sess.run([accuracy],feed_dict={x:my_mnist.test.images,y:my_mnist.test.labels,keep_prob:1.0})
print("第%d次迭代,accuracy = %f" % (i + 1,acc[0]))
saver.save(sess,DIR + "projector/projector/a_model.ckpt",global_step=max_steps)
projector_writer.close()
sess.close()