深度学习基础。入门到实战,深度学习到底有多深?
深度学习是机器学习的一个特定分支。我们要想充分理解深度学习,必须对机器学习的基本原理有深刻的理解。
大部分机器学习算法都有超参数(必须在学习算法外手动设定)。机器学习本质上属于应用统计学,其更加强调使用计算机对复杂函数进行统计估计,而较少强调围绕这些函数证明置信区间;因此我们会探讨两种统计学的主要方法: 频率派估计和贝叶斯推断。同时,大部分机器学习算法又可以分成监督学习和无监督学习两类;本文会介绍这两类算法定义,并给出每个类别中一些算法示例。
现在搞AI的公司,不管用什么样的算法,都想让自己跟深度学习扯上点关系,因为这样好像显得逼格够高。目前比较前沿的语音交互、计算机视觉等,就连神坛的Alpha Go的算法都是用深度学习。那究竟深度学习是什么?到底有多强大?要怎么实现?本文就跟大家一起讨论下。
在看接下来的内容之前,如果对机器学习还不了解的同学,可以先看下这篇《想入门AI,机器学习你知多少了?》——介绍了机器学习的整体框架,机器学习的步骤,深度学习与机器学习的关系,还有比较详细的介绍了为什么会需要人工神经网络。看完以上的文章再来讨论今天的内容可能会更容易理解。
好了,我们言归正传。
以下就是我们本次需要谈论的内容:
01 深度学习一些有趣的应用
1. Face 2 Face
Face2Face是斯坦福大学等学生做的一款应用软件,这套系统能够利用人脸捕捉技术,让你说话的声音、表情、动作,投射到视频中的另一个人脸色。

如上图所示,左上角是特兰普演讲的视频,左下角是模仿者在说话,经过系统处理后,特兰普的表情和声音就变成了模仿者的表情和声音。(大家可以搜下网上的视频,挺有意思的)
2. 灵魂画家

这个大家可能也见过,就是在原来的图片上,加上了另外一个图片的风格特点。
如上图所示,一张蒙娜丽莎的画,加上了梵高画的特征,就变成了如右边所示的图片。
3. AlphaGo
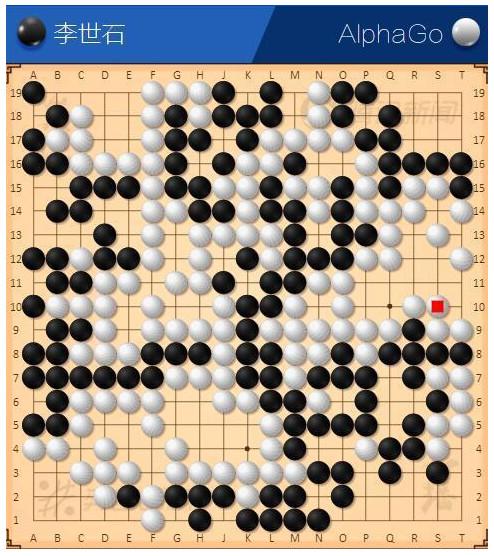
这个大家就更熟悉了,2016年3月,AlphaGo与围棋世界冠军棋手李世石进行围棋人机大战,以4比1的总比分获胜。
通过上面的例子大家可以看到,深度学习的应用非常的广泛,小到很有趣的表情投影,大到围棋人机大战。也就是说深度学习的空间很广,想做一个深度学习的产品也不是我们想象中的那么深奥,但是要想做得特别强大还是会有很多困难的。
那深度学习究竟是什么,接下来就和大家详细讨论下。
02 什么才是深度学习?
在讲深度学习之前,我们先要知道什么是神经网络,而在讲神经网络之前,我们还得先知道什么是神经元。
1. 神经元
假设设置函数:Z(x)=W1X1 + W2X2 + W3X3 +…+WnXn + b,(是不是很眼熟,跟我们之前说到的线性方程很相识,不知道这个由来的话,再次建议先看下前面提到的文章)。
则神经元的表示如下:
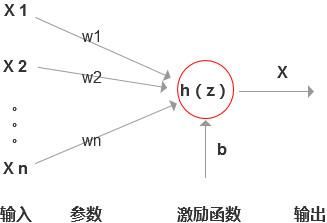
每一个神经元就是一个逻辑回归算法。什么是逻辑回归算法,可以参考这篇文章《机器学习之逻辑回归》,在此就不展开讲了。
2. 神经网络
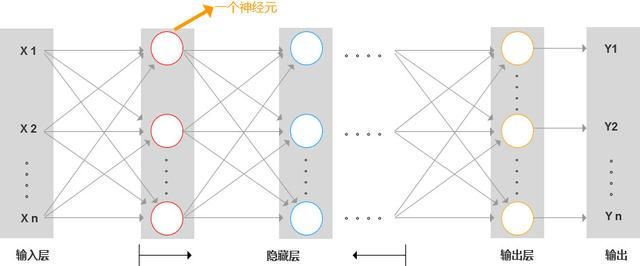
多个神经元相互连接就组成了神经网络,每个神经元都通过接收前一层网络传递来的信息,经过处理后,再传递给下一层。
按结构来分,神经网络由:输入层、隐藏层和输出层组成。
- 输入层:即原始的特征输入。
- 隐藏层:除输入层和输出层外,其他的就是隐藏层。
- 输出层:后面不再接其他神经元。
3. 深度学习和神经网络的关系
定义:有多层网络结构的神经网络,我们就说是深度学习。
那有多少层才算是深度学习呢?
现在也没有一个官方的定义,有的人说3层,有的人说5层才算深度网络,多的高达上百层,反正大家都说自己是在做深度学习,这样看起来会比较高大尚点。
模组化:深度学习有一个非常重要的思想就是模组化。
那什么是模组化思想呢?
就像我们玩搭积木,一堆积木可以搭成各种各样形状的东西,而深度学习的每一层都是一个组件,可以供其他层灵活调用。
下面用一个例子说明:
假设我们要做一个图像识别,区分出4类人群:长头发的女生、短头发的女生、长头发的男生、短头发的男生。
非模组化的思路:

要设计4个基础的分类器:长发女、短发女、长发男、短发男,然后就需要找4类型这样的图片去训练机器。但现实中的问题可能是长头发的男生会比较少,因此训练出来的效果可能就不是很好。
模组化的思路:
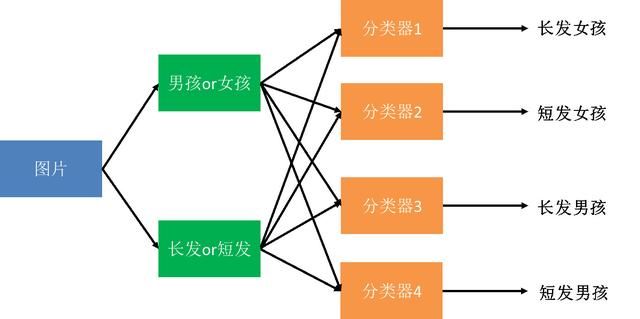
我们可以先训练好两个基础模型:区分男女的分类器、区分长短头发的分类器,这样我们就可以有足够好的数据去训练好这两个分类器。
然后,在下一层区分长发女、短发女、长发男、短发男的分类器中,我们就可以直接调用前面的模块的输出组合了。
模组化的好处:
- 充分利用数据,比较少的数据就可以训练出比较好的模型。
- 训练时间短,拆分一个模组一个模组的训练的效率要比一坨训练高。
- 灵活调用,训练好一个模组的时候,可以供多个地方共有参数。
03 深度学习需要怎么做?
其实这三步跟我们之前讨论的线性回归的差不多,先定义好模型,然后定义出代价函数,最后用数据训练,找出最优的参数。主要的不同点是在第一步,怎么定义网络架构。
1. 定义网络架构
在定义网络架构时,需要考虑几个问题:
- 输入是什么?
- 输出是什么?
- 选择多少层网络?
- 每一层有多少个神经元?
- 层与层之间要怎么连接的?
如何选择输入、输出?
以手写数字辨识为例说明:

假设我们要辨识一张像素是16*16=256的手写数字图片,那每一个像素点就是一个特征变量X,因此输入就是:X1、X2、X3、X4、…、X256。输出就是0-9十个数字的概率,然后根据概率最大是那个数字预测结果。
上图,分别输出了是数字0-9的概率,而是2的概率最大是0.9,因此机器觉得,这个数字就是2。
如何选择网络架构?
最常见的就是全连接,通过训练再逐步把参数为0的剔除掉。再厉害点的话就是,让机器自己去学习然后决定用多少层,怎么去连接。
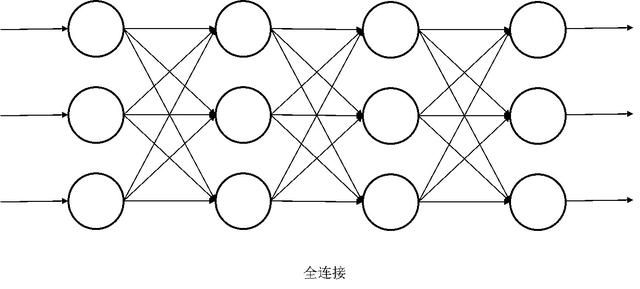
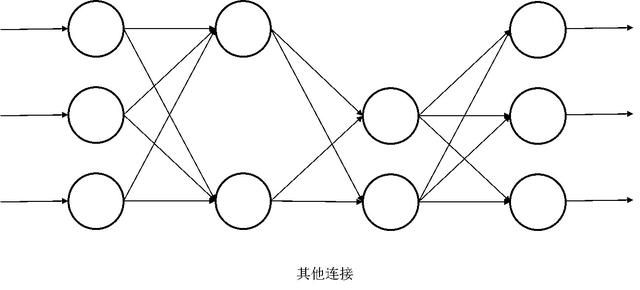
实现同一个功能,可能网络架构的选择可以是不一样,没有一个唯一的标准。
2. 定义什么是最好的(定义代价函数)
在第一步搭建好神经网络架构之后,接下来要做的事情就是确定最优的参数。
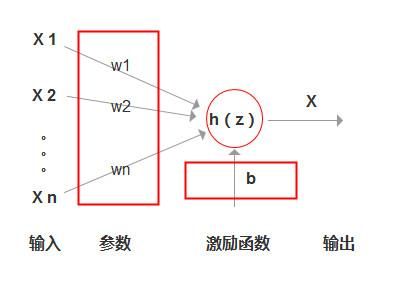
如上图所示,我们要确定一个模型,就是确定每个神经元红框内这些参数的值。
我们在模型输入一个数据,就会得到一个预测值,假设预测值与真实值的误差为L,那输入所有训练数据的误差就是:总L=L1 + L2 + L3 + L4 + … + Ln。

备注:上图的X1不是指单个特征详细,而是指输入的第一张图片,每张图片都有256个特征向量值。
当总误差最小时(总L最小时),得到的参数就是我们认为最好的参数,因此这就是我们定义什么是最好的。
3. 找出最优模型(求出最优解)
假设我们的总误差是一条如上图的曲线,那我们要怎么找到她的最小值呢?

求最小值,常见的方法是梯度下降。什么是梯度下降呢?
类比例子:
假设你现在在大山的某处,你的目标是要到达山的最低谷处,那你需要做事情有两步:
- 根据当前位置,选择一个向低处的方向。
- 根据选择的方向,走一段距离,再停下来选择方向。
不断的重复以上的两步,最终你可能走到山的最底处。
这里有两个需要注意的点:
- 你根据什么来选择方向?
- 你走多长距离再停下来选择方向?如果你选择的距离很小的话,那可能不知道走到猴年马月你才能走到最低,但是如果你选择的距离很长的话,有可能你走了最低点还不知道。
那梯度下降也是用同样的思想来找到最小值的,分两步:
- 选方向:在误差函数曲线上,随机取一个点,然后求导,根据导数的正负,决定移动的方向。
- 选择步长:学习率的参数决定步长。
具体梯度下降是怎么实现的,可以参考这篇文章《机器学习之线性回归》,有讲到梯度下降的方法,在此就不展开讲了。
当然梯度下降只是求解最小值最常用的方法而已,还有其他求最小值的方法,比如:标准函数法等,感兴趣的同学可以去了解下。
4. 深度学习的典型代表
在深度学习领域有两个典型的代表:卷积神经网络、循环神经网络。
- 卷积神经网络被广泛的应用在计算机视觉领域,比如说强大的AlphaGo就有用到卷积神经网络实现。
- 循环神经网络则被广泛的应用在语音识别处理领域,比如说百度翻译、网络音乐生产等。
具体卷积神经网络和循环神经网络是什么?具体的结构是怎样的?又是怎么运行的?都应用在哪些产品上?我会写两篇文章分别单独介绍,感兴趣的同学可以持续关注。
04 深度学习的优缺点和面临的困境
优点
深度学习能让计算机自动学习出模式特征,并将特征学习的特征融入到建模的过程中,从而减少了人为设计特征造成的不完备性。而目前有些深度学习,已经达到了超越现有算法的识别或分类性能。
缺点
- 需要大数据支撑,才能达到高精度。
- 由于深度学习中图模型比较复杂,导致算法的时间复杂度急剧提升,需要更好的硬件支持。因此,只有一些经济实力比较强大的科研机构或企业,才能够用深度学习来做一些前沿而实用的应用。
面临挑战
Marcus 在 2018 年对深度学习 的作用、局限性和本质进行了重要的回顾。他强烈指出了 DL 方法的局限性——即需要更多的数据,容量有限,不能处理层次结构,无法进行开放式推理,不能充分透明,不能与先验知识集成,不能区分因果关系。
他还提到,DL 假设了一个稳定的世界,以近似方法实现,工程化很困难,并且存在着过度炒作的潜在风险。
Marcus 认为:DL 需要重新概念化,并在非监督学习、符号操作和混合模型中寻找可能性,从认知科学和心理学中获得见解,并迎接更大胆的挑战。
好了,关于深度学习的介绍就到此结束了,如有错漏欢迎批评指正。