一文弄懂Spark基本架构和原理
文章目录
- 一、基本介绍
-
- spark是什么?
- 弹性分布式数据集RDD
- 基本概念
- 基本流程
- 二、Hadoop和Spark的区别
- 三、RDD操作
-
- Transformation
- Action
- 四、Block与RDD生成过程
- 五、依赖关系与Stage划分
- 六、Spark流程
-
- 调度流程(粗粒度图解)
- 执行流程(细粒度图解)
- 七、spark在yarn上的两种运行模式(yarn-client和yarn-cluster)
-
- 1、Yarn-Client
- 2、Yarn-Cluster
- 3、两种模式区别
- 八、MapReduce的Shuffle和Spark中的Shuffle区别和联系
-
- MapReduce的Shuffle
- Spark中的Shuffle
-
- 基于Hash的Shuffle实现
- 基于Sort的Shuffle实现
- 九、spark中的持久化(cache()、persist()、checkpoint())
- 十、监控界面
- 十一、PySpark实现WordCount示例
- 十二、PySpark总结
一、基本介绍
spark是什么?
快速,通用,可扩展的分布式计算引擎。
弹性分布式数据集RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。 RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。

官网参考:
RDD Programming Guide:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
基本概念

基本流程
参考:
Spark 2.2.0 中文文档:http://spark.apachecn.org
Apache Spark 的设计与实现:https://spark-internals.books.yourtion.com/index.html
二、Hadoop和Spark的区别
Spark 则是UC Berkeley AMP lab (加州大学伯克利分校AMP实验室)所开源的类Hadoop MapReduce的通用并行框架, 专门用于大数据量下的迭代式计算.是为了跟 Hadoop 配合而开发出来的,不是为了取代 Hadoop, Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁盘中,第二次 Mapredue 运算时在从磁盘中读取数据,所以其瓶颈在2次运算间的多余 IO 消耗. Spark 则是将数据一直缓存在内存中,直到计算得到最后的结果,再将结果写入到磁盘,所以多次运算的情况下, Spark 是比较快的. 其优化了迭代式工作负载。
| Hadoop的局限 | Spark的改进 |
|---|---|
| 抽象层次低,编码难以上手。 | 通过使用RDD的统一抽象,实现数据处理逻辑的代码非常简洁。 |
| 只提供Map和Reduce两个操作,欠缺表达力。 | 通过RDD提供了许多转换和动作,实现了很多基本操作,如sort、join等。 |
| 一个job只有map和reduce两个阶段,复杂的程序需要大量的job来完成。且job之间的依赖关系需要应用开发者自行管理。 | 一个job可以包含多个RDD的转换操作,只需要在调度时生成多个stage。一个stage中也可以包含多个map操作,只需要map操作所使用的RDD分区保持不变。 |
| 处理逻辑隐藏在代码细节中,缺少整体逻辑视图。 | RDD的转换支持流式API,提供处理逻辑的整体视图。 |
| 对迭代式数据的处理性能比较差,reduce与下一步map的中间结果只能存放在HDFS的文件系统中。 | 通过内存缓存数据,可大大提高迭代式计算的性能,内存不足时可溢写到磁盘上。 |
| reduce task需要等所有的map task全部执行完毕才能开始执行。 | 分区相同的转换可以在一个task中以流水线的形式执行。只有分区不同的转换需要shuffle操作。 |
| 时延高,只适合批数据处理,对交互式数据处理和实时数据处理支持不够。 | 将流拆成小的batch,提供discretized stream处理流数据 |
参考:https://blog.csdn.net/databatman/article/details/53023818
三、RDD操作
两种类型: transformation和action
官网介绍:http://spark.apache.org/docs/latest/rdd-programming-guide.html#transformations
Transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。
Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
常用的Transformation:
| 动作 | 说明 | 示例 |
|---|---|---|
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 (每一个输入元素只能被映射为一个) | var rdd = sc.parallelize(List(“hello world”, “hello spark”, “hello hdfs”)) var rdd2 = rdd.map(x => x + “_1”) rdd2.foreach(println) |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 | var rdd3 = rdd2.filter(x => x.contains(“world”)) rdd3.foreach(println) |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) | var rdd4 = rdd2.flatMap(x => x.split(" ")) rdd4.foreach(println) |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 | |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD | var rdd5 = rdd4.map(x => (x, 1)) var rdd6 = rdd5.groupByKey() rdd6.foreach(println) |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 | var rdd = sc.parallelize(1 to 10)rdd.sample(false,0.4).collect() rdd.sample(false,0.4, 9).collect() |
| combineByKey | 合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) | jake 80.0 jake 90.0 jake 85.0 mike 86.0 mike 90 求分数的平均值 |
Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
常用的Action:
| 动作 | 含义 | 示例 |
|---|---|---|
| reduce(func) | 通过func函数聚集RDD中的所有元素,可以实现,RDD中元素的累加,计数和其他类型的聚集操作 | var rdd = sc.parallelize(1 to 10) rdd.reduce((x, y) => x+y) |
| reduceByKey(func) | 按key进行reduce,让key合并 | wordcount示例: var rdd = sc.parallelize(List(“hello world”, “hello spark”, “hello hdfs”)) rdd.flatMap(x => x.split(" ")).map(x => (x,1)).reduceByKey((x,y) => x+y).collect() |
| collect() | 在驱动程序中,以数组的形式返回数据集的所有元素 | |
| count() | 返回RDD的元素个数 | |
| first() | 返回RDD的第一个元素(类似于take(1)) | |
| take(n) | 返回一个由数据集的前n个元素组成的数组 | |
| saveAsTextFile(path) | 将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 | rdd.saveAsTextFile("/user/jd_ad/ads_platform/outergd/0124/demo2.csv") |
| foreach(func) | 在数据集的每一个元素上,运行函数func进行更新。 | |
| takeSample | 抽样返回一个dateset中的num个元素 | var rdd = sc.parallelize(1 to 10) rdd.takeSample(false,10) |
四、Block与RDD生成过程

输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。
当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。
随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。
随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。
而 Task被执行的并发度 = Executor数目 * 每个Executor核数。
至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
五、依赖关系与Stage划分
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。简单的区分发,可以看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。如下图
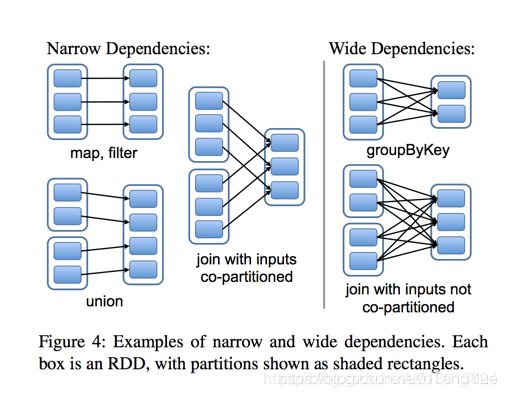
窄依赖( narrow dependencies )
- 子RDD 的每个分区依赖于常数个父分区(即与数据规模无关)
- 输入输出一对一的算子,且结果RDD 的分区结构不变,主要是map 、flatMap
- 输入输出一对一,但结果RDD 的分区结构发生了变化,如union 、coalesce
- 从输入中选择部分元素的算子,如filter 、distinct 、subtract 、sample
宽依赖( wide dependencies )
- 子RDD 的每个分区依赖于所有父RDD 分区
- 对单个RDD 基于key 进行重组和reduce ,如groupByKey 、reduceByKey ;
- 对两个RDD 基于key 进行join 和重组,如join
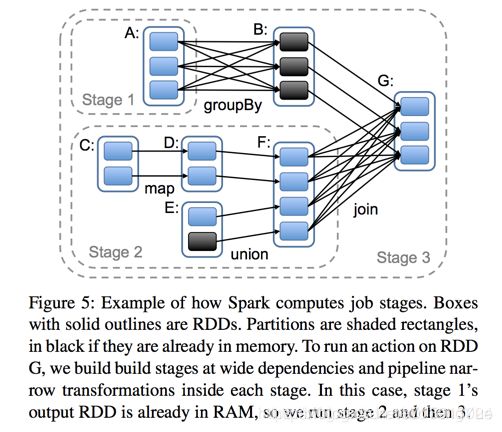
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。 stage是由一组并行的task组成。切割规则:从后往前,遇到宽依赖就切割stage,遇到窄依赖就将这个RDD加入该stage中。 如下图
六、Spark流程
调度流程(粗粒度图解)
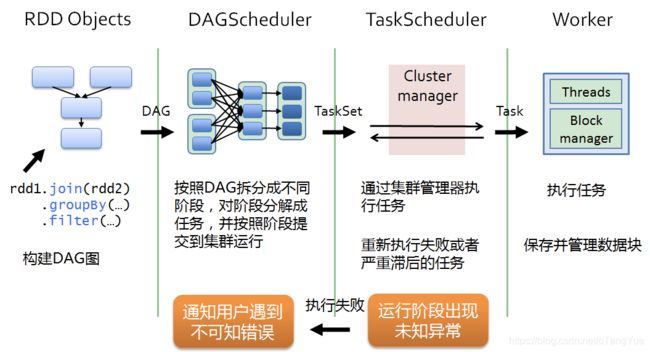
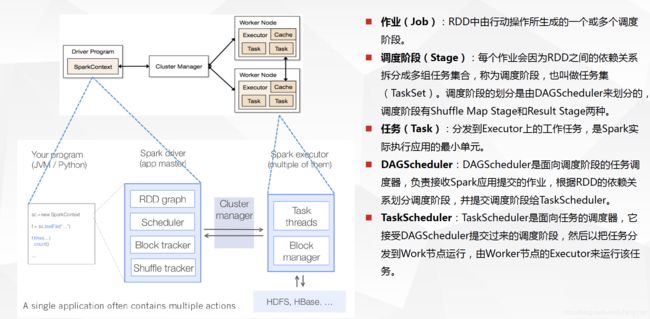
- 1、DriverProgram即用户提交的程序定义并创建了SparkContext的实例,SparkContext会根据RDD对象构建DAG图,然后将作业(job)提交(runJob)给DAGScheduler。
- 2、DAGScheduler对作业的DAG图进行切分成不同的stage[stage是根据shuffle为单位进行划分],每个stage都是任务的集合(taskset)并以taskset为单位提交(submitTasks)给TaskScheduler。
- 3、TaskScheduler通过TaskSetManager管理任务(task)并通过集群中的资源管理器(Cluster Manager)[standalone模式下是Master,yarn模式下是ResourceManager]把任务(task)发给集群中的Worker的Executor, 期间如果某个任务(task)失败, TaskScheduler会重试,TaskScheduler发现某个任务(task)一直未运行完成,有可能在不同机器启动一个推测执行任务(与原任务一样),哪个任务(task)先运行完就用哪个任务(task)的结果。无论任务(task)运行成功或者失败,TaskScheduler都会向DAGScheduler汇报当前状态,如果某个stage运行失败,TaskScheduler会通知DAGScheduler可能会重新提交任务。
- 4、Worker接收到的是任务(task),执行任务(task)的是进程中的线程,一个进程中可以有多个线程工作进而可以处理多个数据分片,执行任务(task)、读取或存储数据。
参考:
https://blog.csdn.net/BigData_Mining/article/details/80743921
执行流程(细粒度图解)

- 1、通过SparkSubmit提交job后,Client就开始构建 spark context,即 application 的运行环境(使用本地的Client类的main函数来创建spark context并初始化它)
- 2、yarn client提交任务,Driver在客户端本地运行;yarn cluster提交任务的时候,Driver是运行在集群上
- 3、SparkContext连接到ClusterManager(Master),向资源管理器注册并申请运行Executor的资源(内核和内存)
- 4、Master根据SparkContext提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动executor
- 5、Worker节点收到请求后会启动executor
- 6、executor向SparkContext注册,这样driver就知道哪些executor运行该应用
- 7、SparkContext将Application代码发送给executor(如果是standalone模式就是StandaloneExecutorBackend)
- 8、同时SparkContext解析Application代码,构建DAG图,提交给DAGScheduler进行分解成stage,stage被发送到TaskScheduler。
- 9、TaskScheduler负责将Task分配到相应的worker上,最后提交给executor执行
- 10、executor会建立Executor线程池,开始执行Task,并向SparkContext汇报,直到所有的task执行完成
- 11、所有Task完成后,SparkContext向Master注销
参考:https://blog.xiaoxiaomo.com/2017/07/05/Spark-%E4%BB%8ESpark%E7%BB%84%E4%BB%B6%E6%9D%A5%E7%9C%8BSpark%E7%9A%84%E6%89%A7%E8%A1%8C%E6%B5%81%E7%A8%8B/
七、spark在yarn上的两种运行模式(yarn-client和yarn-cluster)
1、Yarn-Client
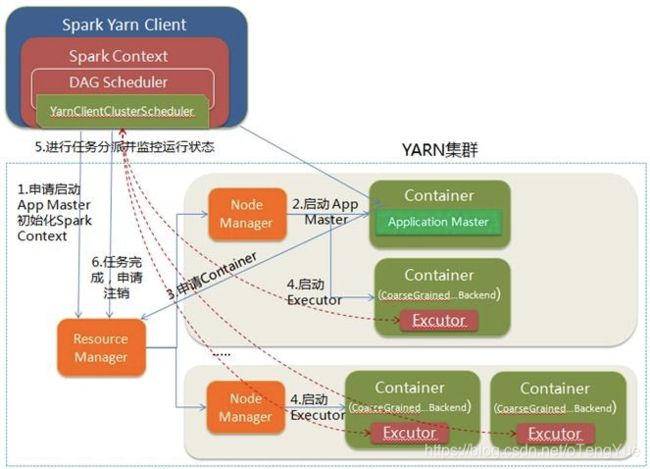
- 1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
- 2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
- 3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
- 4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
- 5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
2、Yarn-Cluster

- 1.Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
- 2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
- 3.ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
- 4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
- 5.ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 6.应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
3、两种模式区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开
下图是几种模式下的比较:

参考:
https://blog.csdn.net/pipisorry/article/details/52366288
https://blog.csdn.net/baidu_35901646/article/details/81612164
https://blog.cloudera.com/blog/2014/05/apache-spark-resource-management-and-yarn-app-models/
Spark on YARN客户端模式作业运行全过程分析:https://www.iteblog.com/archives/1191.html
Spark on YARN集群模式作业运行全过程分析:https://www.iteblog.com/archives/1189.html
八、MapReduce的Shuffle和Spark中的Shuffle区别和联系
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,这期间涉及到序列化反序列化、跨节点网络IO以及磁盘读写IO等,所以说Shuffle是整个应用程序运行过程中非常昂贵的一个阶段,理解Spark Shuffle原理有助于优化Spark应用程序。
注:
1.什么是大数据处理的Shuffle?
无论是Hadoop还是Spark,都要实现Shuffle。Shuffle描述数据从map tasks的输出到reduce tasks输入的这段过程。
2.为什么需要进行Shuffle呢?
map tasks的output向着reduce tasks的输入input映射的时候,并非节点一一对应的,在节点A上做map任务的输出结果,可能要分散跑到reduce节点A、B、C、D ,就好像shuffle的字面意思“洗牌”一样,这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。
MapReduce的Shuffle
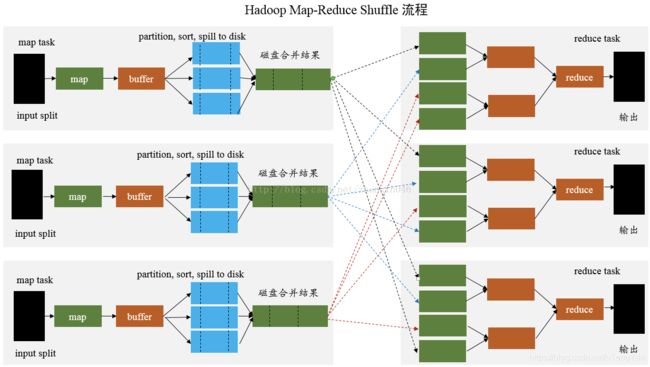
MapReduce 是 sort-based,进入 combine() 和 reduce() 的 records 必须先partition、key对中间结果进行排序合并。这样的好处在于 combine/reduce() 可以处理大规模的数据,因为其输入数据可以通过外排得到(mapper 对每段数据先做排序,reducer 的 shuffle 对排好序的每段数据做归并)。
Spark中的Shuffle
前面已经提到,在DAG调度的过程中,Stage阶段的划分是根据是否有shuffle过程,也就是存在ShuffleDependency宽依赖的时候,需要进行shuffle,这时候会将作业job划分成多个Stage;
Spark的Shuffle实现大致如下图所示,在DAG阶段以shuffle为界,划分stage,上游stage做map task,每个map task将计算结果数据分成多份,每一份对应到下游stage的每个partition中,并将其临时写到磁盘,该过程叫做shuffle write;下游stage做reduce task,每个reduce task通过网络拉取上游stage中所有map task的指定分区结果数据,该过程叫做shuffle read,最后完成reduce的业务逻辑。
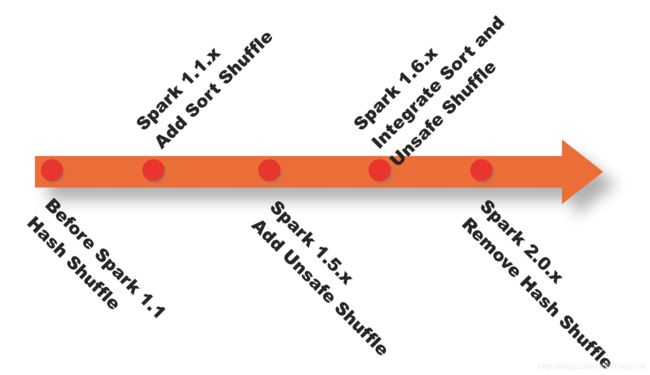
下图是spark shuffle实现的一个版本演进。
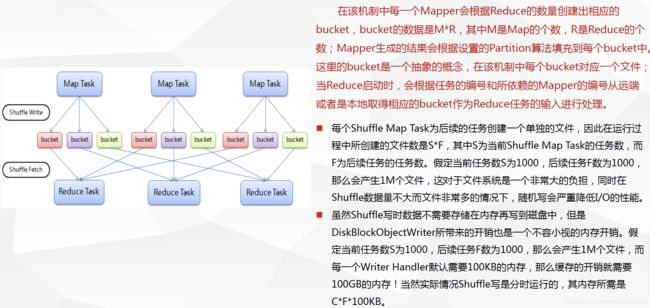
基于Hash的Shuffle实现
基于Sort的Shuffle实现
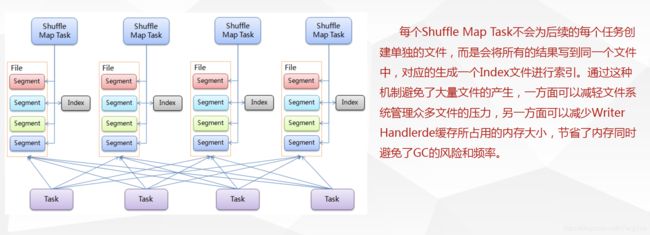
参考:
Spark Shuffle原理及相关调优:http://sharkdtu.com/posts/spark-shuffle.html
Spark专题(二):Hadoop Shuffle VS Spark Shuffle:https://www.cnblogs.com/openAI/p/8512029.html
Spark 性能优化——和 shuffle 搏斗:http://www.raychase.net/3788
spark基础之shuffle机制和原理分析:https://blog.csdn.net/zhanglh046/article/details/78360762
hadoop中shuffle过程详解:https://www.jianshu.com/p/998e0ff60ede
MapReduce之Shuffle过程详述:http://matt33.com/2016/03/02/hadoop-shuffle
九、spark中的持久化(cache()、persist()、checkpoint())
RDD持久化级别
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_ONLY_2 DISK_ONLY_2 MEMORY_ONLY_SER_2 MEMORY_AND_DISK_2 MEMORY_AND_DISK_SER_2 |
对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。 |
- cache和persist都是用于将一个RDD进行缓存,这样在之后使用的过程中就不需要重新计算,可以大大节省程序运行时间。
- cache和persist的区别:cache只有一个默认的缓存级别
MEMORY_ONLY,而persist可以根据情况设置其它的缓存级别。 - checkpoint接口是将RDD持久化到HDFS中,与persist的区别是checkpoint会切断此RDD之前的依赖关系,而persist会保留依赖关系。
checkpoint的两大作用:
一是spark程序长期驻留,过长的依赖会占用很多的系统资源,定期checkpoint可以有效的节省资源;
二是维护过长的依赖关系可能会出现问题,一旦spark程序运行失败,RDD的容错成本会很高。
(注:checkpoint执行前要先进行cache,避免两次计算。)
参考:
RDD持久化:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-persistence
Spark core中的cache、persist区别,以及缓存级别详解:https://blog.csdn.net/yu0_zhang0/article/details/80424609
spark中cache()、persist()、checkpoint()解析:https://www.jianshu.com/p/515dbcd0859d
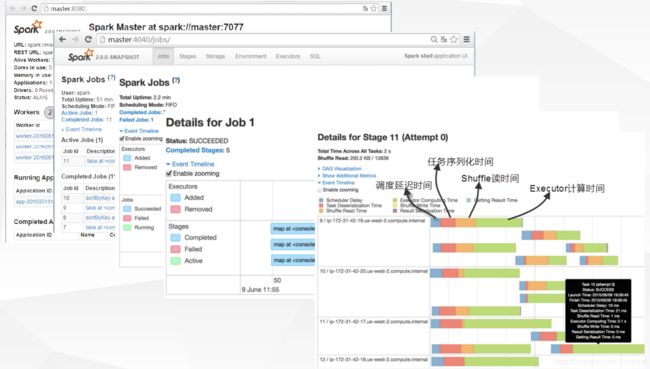
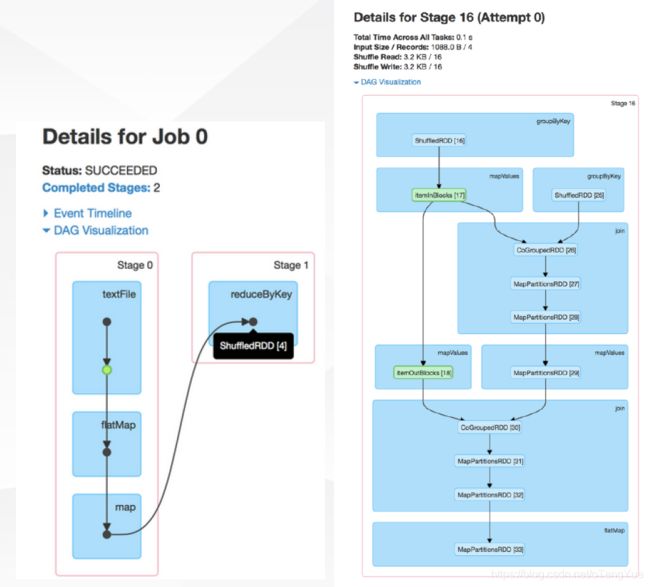
十、监控界面
十一、PySpark实现WordCount示例
wordcount.py
# -*- coding: utf-8 -*-
import sys
import os
import datetime
from pyspark import SparkConf,SparkContext
sc = SparkConf().setAppName("wordcount")
spark = SparkContext(conf=sc)
text_file = spark.textFile("hdfs://shw/pyspark")
word_cnt_rdd = text_file.flatMap(lambda line : line.split(' ')).map(lambda word : (word, 1)).reduceByKey(lambda x, y: x + y)
word_cnt_rdd.saveAsTextFile('hdfs://shw/wc')
提交任务
spark-submit --master yarn --deploy-mode client --num-executors 10 --executor-memory 10g --executor-cores 8 --driver-memory 10g --conf spark.pyspark.python=python2.7 wordcount.py
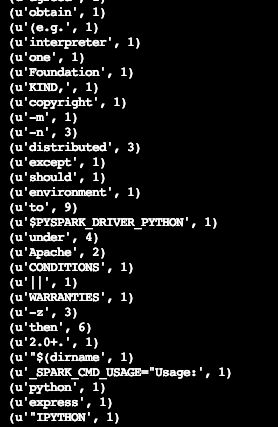
结果
hadoop fs -cat hdfs://shw/wc/part-00000
十二、PySpark总结
见另一篇博文:https://blog.csdn.net/oTengYue/article/details/88417186