倒立摆_DQN算法_边做边学深度强化学习:PyTorch程序设计实践(5)
倒立摆_DQN算法_边做边学深度强化学习:PyTorch程序设计实践(5)
- 0、相关系列文章
- 1、Agent.py
- 2、Brain.py
- 3、Environment.py
- 4、Val.py
- 5、ReplayMemory.py
- 6、main.py
- 7、最终结果
- 8、代码下载
- 9、参考资料
0、相关系列文章
迷宫_随机实验_边做边学深度强化学习:PyTorch程序设计实践(1)
迷宫_Sarsa算法_边做边学深度强化学习:PyTorch程序设计实践(2)
迷宫_Q-Learning算法_边做边学深度强化学习:PyTorch程序设计实践(3)
倒立摆_Q-Learning算法_边做边学深度强化学习:PyTorch程序设计实践(4)
1、Agent.py
from select import select
import numpy as np
import Brain
# 倒立摆小推车对象
class Agent:
def __init__(self, num_states, num_actions):
# 为智能体创建大脑以作出决策
self.brain = Brain.Brain(num_states, num_actions)
# 更新Q函数
def update_Q_function(self):
self.brain.replay()
# 确定下一个动作
def get_action(self, state, episode):
action = self.brain.decide_action(state, episode)
return action
# 将state\action\state_next和reward的内容保存在经验池中
def memorize(self, state, action, state_next, reward):
self.brain.memory.push(state, action, state_next, reward)
2、Brain.py

from os import rename
import numpy as np
from ReplayMemory import ReplayMemory, Transition
import Val
import random
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
BATCH_SIZE = 32
CAPACITY = 10000
lr = 0.0001
# 使用Q表来实现Q学习
class Brain:
# 为智能体创建大脑以作出决策
def __init__(self, num_states, num_actions):
# 获取动作
self.num_actions = num_actions
# 创建存储经验的对象
self.memory = ReplayMemory(CAPACITY)
# 构建一个神经网络
self.model = nn.Sequential()
self.model.add_module('fc1',nn.Linear(num_states,32))
self.model.add_module('relu1',nn.ReLU())
self.model.add_module('fc2',nn.Linear(32,32))
self.model.add_module('relu2',nn.ReLU())
self.model.add_module('fc3',nn.Linear(32,num_actions))
# 输出网络的形状
print(self.model)
# 最优化方法的设定
self.optimizer = optim.Adam(self.model.parameters(),lr=0.0001)
# 通过Experience Replay 学习网络的连接参数
def replay(self):
# 1.检查经验池大小
if len(self.memory) < BATCH_SIZE:
return
# 2.创建小批量数据
transitions = self.memory.sample(BATCH_SIZE)
# 2.2 将每个变量转换为与小批量数据对应的形式
batch = Transition(*zip(*transitions))
# 2.3 将每个变量的元素转换为与小批量数据对应的格式
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
non_final_next_states = torch.cat([s for s in batch.next_state if s is not None])
# 3.求取Q(s_t,a_t)值作为监督信号
# 3.1 将网络切换到推理模式
self.model.eval()
# 3.2 求取网络输出的Q(s_t,a_t)
state_action_values = self.model(state_batch).gather(1, action_batch)
# 3.3 求取max{Q(s_t+1,a)}值
non_final_mask = torch.ByteTensor(tuple(map(lambda s:s is not None, batch.next_state)))
next_state_values = torch.zeros(BATCH_SIZE)
next_state_values[non_final_mask] = self.model(non_final_next_states).max(1)[0].detach()
# 3.4 从Q公式中求取Q(s_t,a_t)值作为监督信息
expected_state_action_values = reward_batch + Val.get_value('GAMMA') * next_state_values
# 4. 更新连接参数
# 4.1 将网络切换到训练模式
self.model.train()
# 4.2 计算损失函数
loss = F.smooth_l1_loss(state_action_values,expected_state_action_values.unsqueeze(1))
# 4.3 更新连接参数
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 确定来自Q表的动作,根据 ε- 贪婪法逐渐采用最优动作
def decide_action(self,state,episode):
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
self.model.eval()
with torch.no_grad():
action = self.model(state).max(1)[1].view(1, 1)
else:
action = torch.LongTensor([[random.randrange(self.num_actions)]]) # 随机返回0、1动作
return action
3、Environment.py
import numpy as np
import matplotlib.pyplot as plt
import torch
import datetime
import gym
import Agent
import Val
# 参考URL http://nbviewer.jupyter.org/github/patrickmineault/xcorr-notebooks/blob/master/Render%20OpenAI%20gym%20as%20GIF.ipynb
from JSAnimation.IPython_display import display_animation
from matplotlib import animation
from IPython.display import display
from IPython.display import HTML
# 定义Environment类,如果连续10次站立195步或更多,则说明强化学习成功,然后再运行一次以保持成功后的动画
class Environment:
def __init__(self):
self.env = gym.make(Val.get_value('ENV')) # 设置要执行的任务
num_states = self.env.observation_space.shape[0] # 获取任务状态的个数
num_actions = self.env.action_space.n # 获取CartPole的动作数为2
self.agent = Agent.Agent(num_states,num_actions) # 创建在环境中行动的Agent
# 将运行状态保存为动画
def display_frames_as_gif(self,frames):
"""
Displays a list of frames as a gif, with controls
"""
plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),
dpi=72)
patch = plt.imshow(frames[0])
plt.axis('off')
def animate(i):
patch.set_data(frames[i])
anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),
interval=50)
#anim.save('result/cartpole_QLearning.mp4') # 保存动画
anim.save('result/cartpole_QLearning'+ datetime.datetime.now().strftime('-%m-%d-%H-%M-%S') +'.gif',writer='pillow')
#display(display_animation(anim, default_mode='loop'))
'''
observation, reward, done, info = env.step(action)是将游戏推进一步的指令
observation表示小车和杆的状态,包含小车位置、小车速度、杆的角度、杆的角速度
reward,是即时奖励
done, 在结束状态时为True
info,包含调试信息
'''
def run(self):
episode_10_list = np.zeros(10)
complete_episodes = 0 # 持续超过195步的实验次数
is_episode_final = False # 最终试验的标志
frames = [] # 用于存储视频图像的变量
for episode in range(Val.get_value('NUM_EPISODES')): # 试验的最大重复次数
observation = self.env.reset() # 环境初始化
state = observation
state = torch.from_numpy(state).type(torch.FloatTensor)
state = torch.unsqueeze(state, 0)
for step in range(Val.get_value('MAX_STEPS')): # 每个回合的循环
if is_episode_final is True:
frames.append(self.env.render(mode='rgb_array'))
# 求取动作
action = self.agent.get_action(state,episode)
# 通过执行动作a_t 找到 s_{t+1},r_{t+1}
observation_next,_,done,_ = self.env.step(action.item())
# 给予奖励
if done:
state_next = None
episode_10_list = np.hstack((episode_10_list[1:],step+1))
# 如果步数超过200,或者如果倾斜超过某个角度,则done为True
if step < Val.get_value('NUM_KEEP_TIMES'):
reward = torch.FloatTensor([-1.0]) # 如果半途摔倒,给予奖励 -1 作为惩罚
complete_episodes = 0 # 站立超过195步,重置试验次数
else:
reward = torch.FloatTensor([1.0]) # 一直站立到结束时给予奖励 1
complete_episodes = complete_episodes + 1 # 更新连续记录
else:
reward = torch.FloatTensor([0.0]) # 途中奖励为 0
state_next = observation_next
state_next = torch.from_numpy(state_next).type(torch.FloatTensor)
state_next = torch.unsqueeze(state_next,0)
# 向经验池中添加经验
self.agent.memorize(state,action,state_next,reward)
# 经验回放中更新Q函数
self.agent.update_Q_function()
# 更新观测值
state = state_next
if done:
print('%d Episode: Finished after %d steps : 10次试验的平均step数 = %.1f'%(episode,step +1,episode_10_list.mean()))
break
# 在最后一次试验中保存并绘制动画
if is_episode_final is True:
self.display_frames_as_gif(frames)
break
if complete_episodes >= 10:
print('10回合连续成功')
is_episode_final = True
4、Val.py
# _*_ coding:utf-8 _*_
'''
在main中,
import Val
#使用一下命令初始化
Val._init()
'''
def _init():
global _global_dict
_global_dict = {}
def set_value(key,value):
_global_dict[key] = value
def get_value(key,defValue=None):
try:
return _global_dict[key]
except KeyError:
return -1
5、ReplayMemory.py
from collections import namedtuple
import random
Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward'))
# 定义用于存储经验的内存类
class ReplayMemory:
def __init__(self,CAPACITY):
self.capacity = CAPACITY
self.memory = []
self.index = 0
def push(self,state,action,state_next,reward):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.index] = Transition(state,action,state_next,reward)
self.index = (self.index + 1) % self.capacity
def sample(self,batch_size):
return random.sample(self.memory,batch_size)
def __len__(self):
return len(self.memory)
6、main.py
# 导入所使用的包
import Environment
import Val
if __name__ == '__main__':
Val._init()
# 定义常量
Val.set_value('ENV','CartPole-v0')# 要使用的任务名称
Val.set_value('GAMMA',0.99) # 时间折扣率
Val.set_value('NUM_KEEP_TIMES',195)# 站立保持次数,超过即为成功
Val.set_value('MAX_STEPS',500)# 一次试验的步数 # 200次时,会出现一边倒的现象
Val.set_value('NUM_EPISODES',500)# 最大试验次数
cartpole_env = Environment.Environment()
cartpole_env.run()
7、最终结果
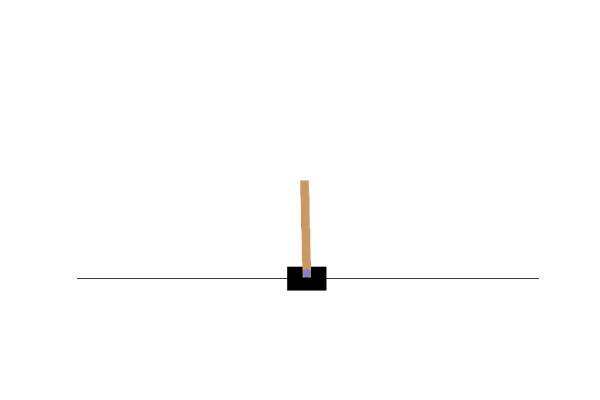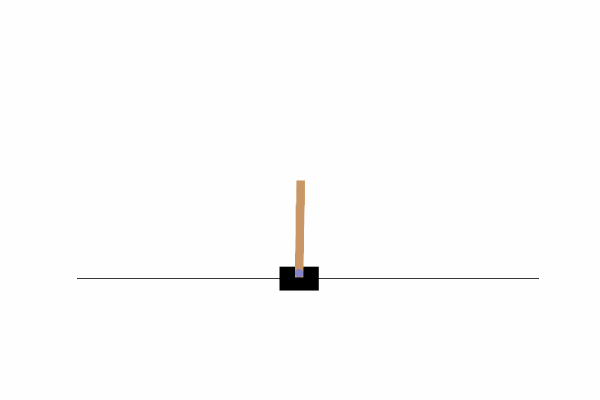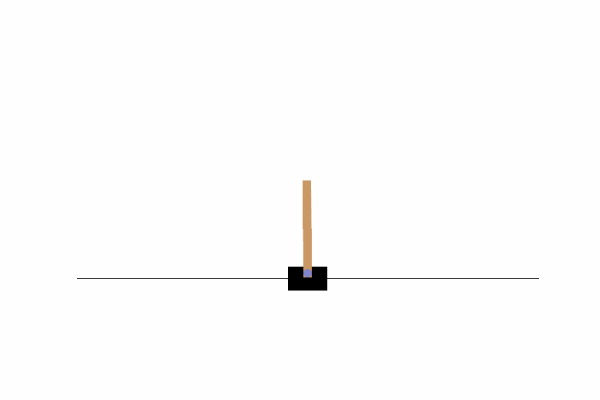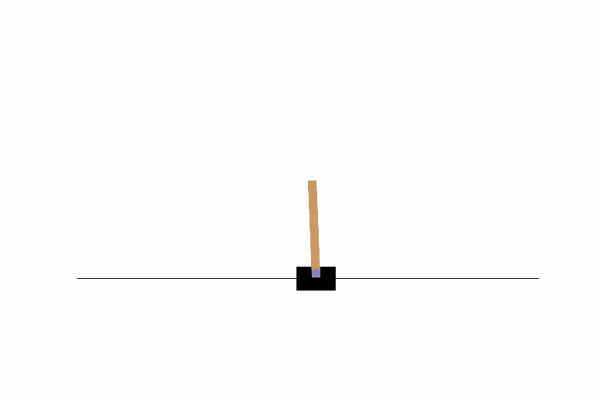
8、代码下载
跳转到下载地址
9、参考资料
[1]边做边学深度强化学习:PyTorch程序设计实践