数字图像处理——第十章 图像分割
数字图像处理——第十章 图像分割
文章目录
- 数字图像处理——第十章 图像分割
-
- 写在前面
- 1 点、线和边缘检测
-
- 1.1 孤立点的检测
- 1.2 线检测
- 1.3 边缘检测
- 2 阈值处理
-
- 2.1 单一全局阈值
- 2.2 自适应阈值
- 3 区域分割
-
- 3.1 区域生长
- 3.2 区域分裂与聚合
- 4 分水岭算法
写在前面
图像分割——以一幅图像作为输入而返回一个或多个区域或亚像素轮廓作为输出。也就是说为得到图像中的物体信息,我们必须进行图像分割,即提取图像中的感兴趣区域。数字图像处理中图像分割的四种方法:
- 边缘检测:检测出边缘,再将边缘像素连接,构成边界形成分割,找出目标物体的轮廓,进行目标的分析、识别、测量等。
- 阈值分割:最常用法。有直方图门限选择,半阈值选择图像分割,迭代阈值
- 边界方法:直接确定区域边界,实现分割;有边界跟踪法,轮廓提取法。
- 区域法:将各像素划归到相应物体或区域的像素聚类方法;有区域增长法等。
1 点、线和边缘检测
1.1 孤立点的检测
孤立点的检测依赖于二阶导数,因此使用拉普拉斯模板。拉普拉斯模板可以将孤立的点检测出来:这个模板的作用就是当模板中心是孤立点时,模板的响应最强,而在非模板中心时,响应为零。也就是如下图所示,孤立点的灰度和周围的像素的灰度很大程度的不同,因此使用这类模板,很容易检测出这个孤立点。对于一个导数模版,系数之和为零表明在恒定灰度区模版响应将是零。

将上述模板写成
kernel = np.array([[-1, -1, -1],[-1, 8, -1],[-1, -1, -1]])
result = cv2.filter2D(img, -1, kernel)

1.2 线检测
线检测同样可使用拉普拉斯模板。但拉普拉斯检测子是各向同性的,因此其响应与方向无关,因此设置四个不同方向的模板。
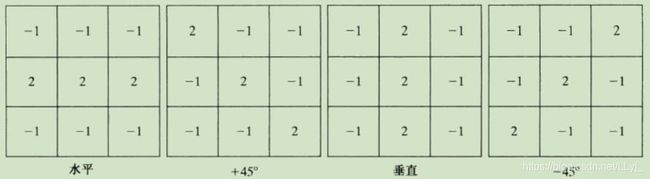
不同的模板对特定方向上的线感兴趣,也就是在不同的情况下使用不同的模板,并对其输出进行阈值处理。如果对检测图像中由给定模板定义的方向上的所有线感兴趣,则只需简单地对该图像运行这个模板,并对结果的绝对值进行阈值处理,留下的点是有最强响应的点,对于1个像素宽度的线来说,相应的点最接近于模板定义的方向。
1.3 边缘检测
边缘检测是基于灰度突变来进行图像分割的最常用的方法。前几章屡次提到的Canny算子就是边缘检测的常用算法。我感觉所有的边缘检测算法本质上就是一种滤波算法,区别在于滤波器的选择,因为滤波的规则是完全一致的。而边缘检测概念离不开梯度。图像梯度即当前所在像素点对于X轴、Y轴的偏导数,所以梯度在图像处理领域我们可以也理解为像素灰度值变化的速度。
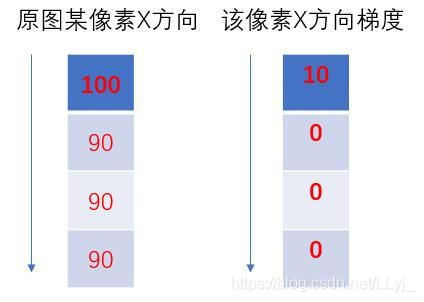
图中我们可以看到,100与90之间相差的灰度值为10,即当前像素点在X轴方向上的梯度为10,而其它点均为90,则求导后发现梯度全为0,因此我们可以发现在数字图像处理,因其像素性质的特殊性,微积分在图像处理表现的形式为计算当前像素点沿偏微分方向的差值,所以实际的应用是不需要用到求导的,只需进行简单的加减运算。
以Sobel算子为例,下图 S x S_{x} Sx、 S y S_{y} Sy分别表示对于X轴、Y轴的边缘检测算子,从 S x S_{x} Sx算子结构可以很清楚发现,这个滤波器是计算当前像素点右边与左边8连通像素灰度值的差值。
s x = [ − 1 0 1 − 2 0 2 − 1 0 1 ] , s y = [ 1 2 1 0 0 0 − 1 − 2 − 1 ] s_{x}=\left[\begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array}\right], s_{y}=\left[\begin{array}{ccc} 1 & 2 & 1 \\ 0 & 0 & 0 \\ -1 & -2 & -1 \end{array}\right] sx=⎣⎡−1−2−1000121⎦⎤,sy=⎣⎡10−120−210−1⎦⎤
举一个很好理解的一维例子:有一个一维数组长度为10:[ 8, 6, 2, 4, 9, 1, 3, 5, 10, 6 ],此时定义一维边缘检测算子为[ -1, 0, 1 ],现在我们把边缘检测算子放在数组上面进行点积(即对应点相乘之后的和),得到结果为:[ 6, -6, -2, 7, -3, -6, 4, 7, 1, -10],出现负数不要紧,取绝对值得[ 6, 6, 2, 7, 3, 6, 4, 7, 1, 10]。其中数字的大小则表示了当前像素点梯度的模大小,即灰度变化的速度有多大,值越大,我们一定程度上就可以确信当前点为我们所要找的边缘点,通过一维的例子我们可以更好理解二维的边缘检测思想,即沿着X轴、Y轴进行两次滤波操作。Sobel算子效果如下:

代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import numba as nb
img = cv2.imread(r' ', 0)
gx = np.array([[-1,0,1],[-2,0,2],[-1,0,1]])
gy = np.array([[1,2,1],[0,0,0],[-1,-2,-1]])
@nb.jit
def sobel(img):
height = img.shape[0]
width = img.shape[1]
tmp_img = img.copy()
for i in range(1,height-1):
for j in range(1, width-1):
tmpx = np.sum(np.sum(gx * img[i-1:i+2,j-1:j+2]))
tmpy = np.sum(np.sum(gy * img[i-1:i+2,j-1:j+2]))
tmp_img[i,j] = np.sqrt(tmpx**2 + tmpy **2)
return tmp_img
sobel_img_my = sobel(img.copy())
x = cv2.Sobel(img,cv2.CV_16S,1,0)
y = cv2.Sobel(img,cv2.CV_16S,0,1)
absX = cv2.convertScaleAbs(x) # 转回uint8
absY = cv2.convertScaleAbs(y)
dst = cv2.addWeighted(absX,0.5,absY,0.5,0)
plt.figure(dpi = 180)
plt.subplot(131)
plt.title('Origin Image')
plt.imshow(img, cmap = 'gray')
plt.subplot(132)
plt.title('Sobel(Ours)')
plt.imshow(sobel_img_my, cmap = 'gray')
plt.subplot(133)
plt.title('Sobel(cv2.Sobel)')
plt.imshow(dst, cmap = 'gray')
plt.tight_layout()
plt.show()
2 阈值处理
所谓阈值处理,就是对事物进行简单的划分。例如60分就算是个阈值,低于60分就是不及格,高于60则是及格。同理可得,一张图片我们也可以设置阈值分为前景和背景。我们感兴趣的一般的是前景部分,所以我们一般使用阈值将前景和背景分割开来,使我们感兴趣的图像的像素值为1,不感兴趣的我0,有时一张图我们会有几个不同的感兴趣区域(不在同一个灰度区域),这时我们可以用多个阈值进行分割,这就是阈值处理。
2.1 单一全局阈值
使用OpenCV库cv2.threshold( ),这个函数有四个参数,第一个是原图像矩阵,第二个是进行分类的阈值,第三个是高于(低于)阈值时赋予的新值,第四个是一个方法选择参数,参数常用的有:
-
cv2.THRESH_BINARY(黑白二值)
-
cv2.THRESH_BINARY_INV(黑白二值翻转)
-
cv2.THRESH_TRUNC(得到额图像为多像素值)
-
cv2.THRESH_TOZERO(当像素高于阈值时像素设置为自己提供的像素值,低于阈值时不作处理)
-
cv2.THRESH_TOZERO_INV(当像素低于阈值时设置为自己提供的像素值,高于阈值时不作处理)

代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import numba as nb
src = cv2.imread(r' ', 0)
# 设置阈值
ThreshValue = 165
# 设置最大像素值
MaxVal = 230
# cv.THRESH_BINARY
returned_thresh_value, dst = cv2.threshold(src, ThreshValue, MaxVal, cv2.THRESH_BINARY)
# cv.THRESH_BINARY_INV
returned_thresh_value1, dst1 = cv2.threshold(src, ThreshValue, MaxVal, cv2.THRESH_BINARY_INV)
# cv.THRESH_TRUNC
returned_thresh_value2, dst2 = cv2.threshold(src, ThreshValue, MaxVal, cv2.THRESH_TRUNC)
# cv.THRESH_TOZERO
returned_thresh_value3, dst3 = cv2.threshold(src, ThreshValue, MaxVal, cv2.THRESH_TOZERO)
# cv.THRESH_TOZERO_INV
returned_thresh_value4, dst4 = cv2.threshold(src, ThreshValue, MaxVal, cv2.THRESH_TOZERO_INV)
plt.figure(dpi = 180)
plt.subplot(231)
plt.title('Origin Image')
plt.imshow(src, cmap = 'gray')
plt.subplot(232)
plt.title('cv2.THRESH_BINARY')
plt.imshow(dst, cmap = 'gray')
plt.subplot(233)
plt.title('cv2.THRESH_BINARY_INV')
plt.imshow(dst1, cmap = 'gray')
plt.subplot(234)
plt.title('cv2.THRESH_TRUNC')
plt.imshow(dst2, cmap = 'gray')
plt.subplot(235)
plt.title('cv2.THRESH_TOZERO')
plt.imshow(dst3, cmap = 'gray')
plt.subplot(236)
plt.title('cv2.THRESH_TOZERO_INV')
plt.imshow(dst4, cmap = 'gray')
plt.tight_layout()
plt.show()
实验结果分析:单一阈值采用全局阈值,只需要设定一个阈值,整个图像都和这个阈值比较,方法过于粗暴。当一张图片存在明显明暗不同的区域,将会导致二值化后丢失所有细节,因此需要对图片进行不同区域的二值化才能得到更好的结果。
2.2 自适应阈值
自适应阈值可以看成一种局部性的阈值,通过设定一个区域大小,比较这个点与区域大小里面像素点 的平均值(或者其他特征)的大小关系确定这个像素点的情况。这种方法理论上得到的效果更好,相当于在动态自适应的调整属于自己像素点的阈值,而不是整幅图都用一个阈值。
自适应阈值算法的核心是将图像分割位不同的区域,每个区域都计算阈值。这样可以更好的处理复杂的图像。自适应阈值函数定义如下:
cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C, dst=None),参数含义如下:
- src:灰度化的图片
- maxValue:满足条件的像素点需要设置的灰度值
- adaptiveMethod:自适应方法。有2种:ADAPTIVE_THRESH_MEAN_C 或 ADAPTIVE_THRESH_GAUSSIAN_C
- thresholdType:二值化方法,可以设置为THRESH_BINARY或者THRESH_BINARY_INV
- blockSize:分割计算的区域大小,取奇数
- C:常数,每个区域计算出的阈值的基础上在减去这个常数作为这个区域的最终阈值,可以为负数
- dst:输出图像,可选
其中,adaptiveMethod的选择非常关键。一种是使用均值的方法,而另外一种是使用高斯加权和的方法。效果如下:

代码如下:
import cv2
import numpy as np
import matplotlib.pyplot as plt
import numba as nb
src = cv2.imread(r' ', 0)
blocksize = 25
C=10
ADAPTIVE_THRESH_MEAN_C = cv2.adaptiveThreshold(src, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, blocksize, C)
ADAPTIVE_THRESH_GAUSSIAN_C = cv2.adaptiveThreshold(src, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, blocksize, C)
plt.figure(dpi = 180)
plt.subplot(131)
plt.title('Origin Image')
plt.imshow(src, cmap = 'gray')
plt.subplot(132)
plt.title('MEAN_C')
plt.imshow(ADAPTIVE_THRESH_MEAN_C, cmap = 'gray')
plt.subplot(133)
plt.title('GAUSSIAN_C')
plt.imshow(ADAPTIVE_THRESH_GAUSSIAN_C, cmap = 'gray')
plt.tight_layout()
plt.show()
实验结果:所谓均值的方法就是以计算区域像素点灰度值的平均值作为该区域所有像素的灰度值,这其实就是一种平滑或滤波作用。而高斯加权和算法是将区域中点(x,y)周围的像素根据高斯函数加权计算他们离中心点的距离。
3 区域分割
区域分割法弥补阈值分割法的不足,利用空间性质,认为属于同一区域的像素应具有相似性。基于区域的分割:区域生长算法和区域分裂与聚合都是属于基于区域的分割算法。
3.1 区域生长
区域生长算法是根据预先定义的生长准则将像素或子区域组合为更大的区域的过程。基本方法是从一组“种子”点开始,将与种子预先定义的性质相似的那些邻域像素添加到每个种子上来形成这些生长区域(如特定范围的灰度或颜色)。
区域生长实现的步骤如下:
-
对图像顺序扫描!找到第1个还没有归属的像素, 设该像素为(x0, y0);
-
以(x0, y0)为中心, 考虑(x0, y0)的4邻域像素(x, y)如果(x0, y0)满足生长准则, 将(x, y)与(x0, y0)合并(在同一区域内), 同时将(x, y)压入堆栈;
-
从堆栈中取出一个像素, 把它当作(x0, y0)返回到步骤2;
-
当堆栈为空时!返回到步骤1;
-
重复步骤1 - 4直到图像中的每个点都有归属时。生长结束。
3.2 区域分裂与聚合
区域分裂合并算法的基本思想是先确定一个分裂合并的准则,即区域特征一致性的测度,当图像中某个区域的特征不一致时就将该区域分裂成4 个相等的子区域,当相邻的子区域满足一致性特征时则将它们合成一个大区域,直至所有区域不再满足分裂合并的条件为止。当分裂到不能再分的情况时,分裂结束,然后它将查找相邻区域有没有相似的特征,如果有就将相似区域进行合并,最后达到分割的作。
4 分水岭算法
在地理学中,分水岭是一个山脊,该山脊通过不同的水系来区分排水区域。集水盆地是把水排入河流或水库的地理区域。分水岭变换把这些概念应用到灰度图像处理中,从而解决许多图像分割问题。
分水岭分割方法,是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明。在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸入水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在两个集水盆汇合处构筑大坝,即形成分水岭。
分水岭函数cv2.watershed(img, markers)
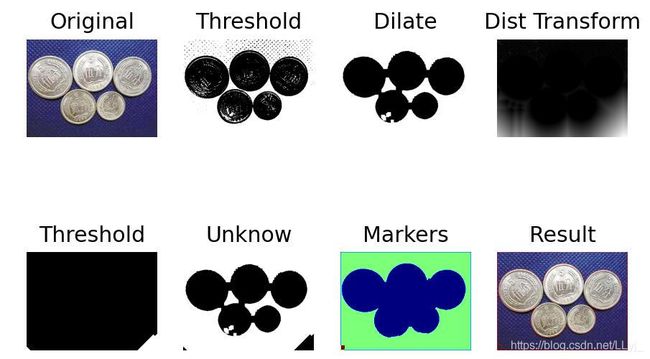
代码如下:
import numpy as np
import cv2
from matplotlib import pyplot as plt
src = cv2.imread(r' ')
img = src.copy()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(
gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# 消除噪声
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 膨胀
sure_bg = cv2.dilate(opening, kernel, iterations=3)
# 距离变换
dist_transform = cv2.distanceTransform(opening, 1, 5)
ret, sure_fg = cv2.threshold(dist_transform, 0.7*dist_transform.max(), 255, 0)
# 获得未知区域
sure_fg = np.uint8(sure_fg)
unknown = cv2.subtract(sure_bg, sure_fg)
# 标记
ret, markers1 = cv2.connectedComponents(sure_fg)
# 确保背景是1不是0
markers = markers1 + 1
# 未知区域标记为0
markers[unknown == 255] = 0
markers3 = cv2.watershed(img, markers)
img[markers3 == -1] = [0, 0, 255]
plt.figure(dpi = 180)
plt.subplot(241), plt.imshow(cv2.cvtColor(src, cv2.COLOR_BGR2RGB)),
plt.title('Original'), plt.axis('off')
plt.subplot(242), plt.imshow(thresh, cmap='gray'),
plt.title('Threshold'), plt.axis('off')
plt.subplot(243), plt.imshow(sure_bg, cmap='gray'),
plt.title('Dilate'), plt.axis('off')
plt.subplot(244), plt.imshow(dist_transform, cmap='gray'),
plt.title('Dist Transform'), plt.axis('off')
plt.subplot(245), plt.imshow(sure_fg, cmap='gray'),
plt.title('Threshold'), plt.axis('off')
plt.subplot(246), plt.imshow(unknown, cmap='gray'),
plt.title('Unknow'), plt.axis('off')
plt.subplot(247), plt.imshow(np.abs(markers), cmap='jet'),
plt.title('Markers'), plt.axis('off')
plt.subplot(248), plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)),
plt.title('Result'), plt.axis('off')
plt.show()