MATLAB实现冒泡排序算法和快速排序算法
- 冒泡算法(Bubble Sort)——一种计算机科学领域的较简单的排序算法。
它重复地走访过要排序的元素列,依次比较两个相邻的元素,如果顺序(如从大到小、首字母从Z到A)错误就把他们交换过来。走访元素的工作是重复地进行,直到没有相邻元素需要交换,也就是说该元素列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。(实质:把小(后)的元素往前(后)调)
冒泡排序算法原理:
比较相邻的元素,如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡排序m函数(引用大佬):
function y=bubble_sort(x)
x_len=length(x);
for i=1:x_len-1
for j=1:x_len-i
if(x(j)>x(j+1))
[x(j),x(j+1)]=swap(x(j),x(j+1));
end
end
disp([num2str(i),'.Sort:x=',num2str(x)]);
end
y=x;
end
function [a,b]=swap(x,y)
a=y;
b=x;
end测试代码:
clc;
clear;
X=[2,6,8,9,17,3,4,5,-3];
disp(['Before Sort:X=',num2str(X)]);
disp('--------------------');
y=bubble_sort2(X);
disp(['Bubble Sort:x=',num2str(y)]);结果如图:

二、快速排序(Quicksort)——将无序序列排成有序(非递减)序列。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
(1)首先设定一个分界值,通过该分界值将数组分成左右两部分。
(2)将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于分界值,而右边部分中各元素都大于或等于分界值。
(3)然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
(4)重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
快速排序m函数程序(含注释):
function data =QuickSort(data,start,endadd) %定义函数名,与函数返回值
if start >= endadd %退出递归的条件
return
end
if start < endadd %当递归条件符合时
key = data(start); %第一个数据作为键值
i = start; %将起始位置作为i。从i位置开始向右遍历
j = endadd; %将结束位置作为j。从j位置开始向左遍历
while i ~= j %当i与j未重合时,即分别在key值的左右两半时
while (i= key) %当i值小于j值,且此时j位置大于key值时
j = j-1; %则此j位置值置于key值右边为正确的,遍历下一个
end
data(i) = data(j); %当找到data[j]比key值小时,退出上述while循环,将找到的比key值小的j位置值赋值给i位置
while (i 测试代码:
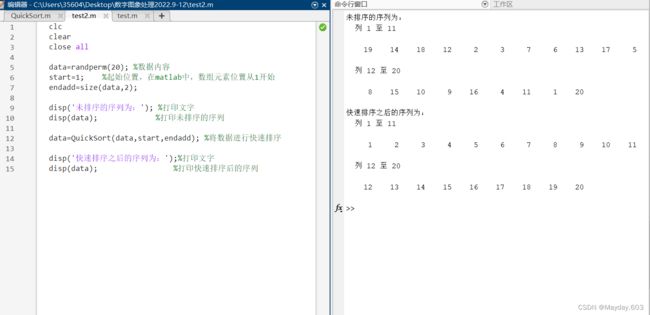
clc
clear
close all
data=randperm(20); %数据内容 (这里我们取随机20的数,也可固定值,例:(data=[-33,23,1,3,8,9]))
start=1; %起始位置,在matlab中,数组元素位置从1开始
endadd=size(data,2);
disp('未排序的序列为:'); %打印文字
disp(data); %打印未排序的序列
data=QuickSort(data,start,endadd); %将数据进行快速排序
disp('快速排序之后的序列为:');%打印文字
disp(data); %打印快速排序后的序列结果如图: