Kubeflow使用Kubernetes进行机器学习GPU分布式训练
Kubeflow使用Kubernetes进行机器学习
Kubeflow是Google推出的基于kubernetes环境下的机器学习组件,通过Kubeflow可以实现对TFJob等资源类型定义,可以像部署应用一样完成在TFJob分布式训练模型的过程。最初的设计是将Kubernetes和Tensorflow结合实现对Tensorflow分布式训练的支持。但是仅仅实现对Tensorflow的支持还是远远不够的,Kubeflow社区又陆续对各种深度学习框架进行支持,例如:MXNet, Caffee, PyTorch等。使得机器学习算法同学只需关心算法实现,而后续的模型训练和服务上线都交给平台来做,解放算法同学使其专做自己擅长的事儿。
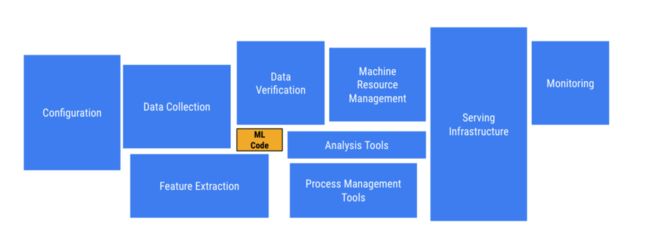
在继续介绍Kubeflow之前, 先简单介绍下真正的机器学习模型服务上线都需要经历哪些阶段,如下图所示:

注意:上图的每种颜色代表对一个阶段的处理
从上图可以看出一个机器学习模型上线对外提供服务要经过:数据清洗验证,数据集切分, 训练,构建验证模型, 大规模训练,模型导出,模型服务上线, 日志监控等阶段。Tensorflow 等计算框架解决了最核心的部分问题,但是距离生产化,产品化,以及企业级机器学习项目开发,还有一段距离。比如: 数据收集, 数据清洗, 特征提取, 计算资源管理, 模型服务, 配置管理, 存储, 监控, 日志等等。
好了机器学习服务上线的基本流程介绍之后,接下来继续介绍Kubeflow.
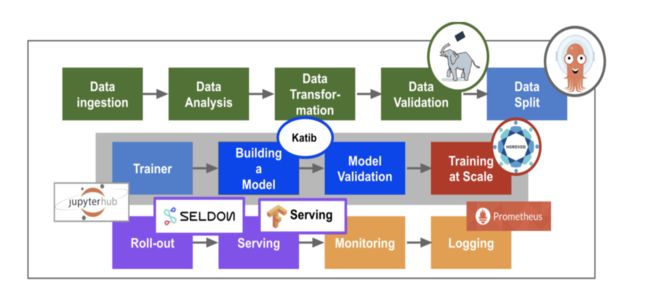
Kubeflow核心组件介绍
- jupyter 多租户NoteBook服务
- Tensorflow PyTorch MPI MXnet Chainer 当前主要支持的机器学习引擎
- Seldon 提供在Kubernetes上对机器学习模型的部署
- TF-Serving 提供对Tensorflow模型的在线部署,支持版本控制及无需停止线上服务,切换模型等功能
- Argo 基于Kubernetes的工作流引擎
- Ambassador 对外提供统一服务的网关(API Gateway)
- Istio 提供微服务的管理,Telemetry收集
- Ksonnet Kubeflow使用ksonnet来向kubernetes集群部署需要的k8s资源
而Kubeflow利用Kubernetes的优势:
- 原生的资源隔离
- 集群化自动化管理
- 计算资源(CPU/GPU)自动调度
- 对多种分布式存储的支持
- 集成较为成熟的监控,告警
将机器学习各个阶段涉及的组件已微服务的方式进行组合并已容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展。
Kubeflow 部署安装
实验环境
硬件环境
服务器配置:
- GPU卡型号: Nvidia-Tesla-K80
- 网卡: 千兆(注意:在进行对大数据集进行训练时,千兆的网卡会是瓶颈)
cephfs服务配置:
- 网卡:万兆(注意:通过ceph对数据存储时,ceph集群需要与Kubernetes同机房,否则延迟会对加载数据集的影响非常高)
注意:服务器的GPU驱动和Nvidia-docker2.0的部署安装之前介绍过,这里就不介绍了。
软件环境:
- kubernetes version: v1.12.2(注意: 需要安装kube-dns)
- kubeflow version: v0.3.2
- jsonnet version: v0.11.2
Kubeflow 安装
- 安装ksonnet
1 2 3 4 5 6 7 8 |
# export KS_VER=0.11.2
# export KS_PKG=ks_${KS_VER}_linux_amd64
# wget -O /tmp/${KS_PKG}.tar.gz https://github.com/ksonnet/ksonnet/releases/download/v${KS_VER}/${KS_PKG}.tar.gz \
--no-check-certificate
# mkdir -p ${HOME}/bin
# tar -xvf /tmp/$KS_PKG.tar.gz -C ${HOME}/bin
# export PATH=$PATH:${HOME}/bin/$KS_PKG
|
关于ksonnet的更多信息请查看官网:https://ksonnet.io/
- 安装Kubeflow
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# export KUBEFLOW_SRC=/home/wangxigang/kubeflow
# mkdir ${KUBEFLOW_SRC}
# cd ${KUBEFLOW_SRC}
# export KUBEFLOW_TAG=v0.3.2
# curl https://raw.githubusercontent.com/kubeflow/kubeflow/${KUBEFLOW_TAG}/scripts/download.sh | bash
# export KUBEFLOW_REPO=/home/wangxigang/kubeflow/scripts
# export KFAPP=/home/wangxigang/kubeflow/kubeflow_ks_app
# ${KUBEFLOW_REPO}/scripts/kfctl.sh init ${KFAPP} --platform none
# cd ${KFAPP}
# ${KUBEFLOW_REPO}/scripts/kfctl.sh generate k8s
# ${KUBEFLOW_REPO}/scripts/kfctl.sh apply k8s
|
关于kubeflow的更多信息请查看官网:https://v0-3.kubeflow.org/docs/started/getting-started/
当上面的所有安装步骤都正常完成之后,先查看kubeflow在kubernetes集群deployment资源对象的启动状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[root@localhost]# kubectl get deployment -n kubeflow NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE ambassador 3 3 3 3 11d argo-ui 1 1 1 1 11d centraldashboard 1 1 1 1 11d modeldb-backend 1 1 1 1 11d modeldb-db 1 1 1 1 11d modeldb-frontend 1 1 1 1 11d mxnet-operator 1 1 1 1 11d spartakus-volunteer 1 1 1 1 11d studyjob-controller 1 1 1 1 11d tf-job-dashboard 1 1 1 1 11d tf-job-operator-v1alpha2 1 1 1 1 11d vizier-core 1 1 1 1 11d vizier-db 1 1 1 1 11d vizier-suggestion-bayesianoptimization 1 1 1 1 11d vizier-suggestion-grid 1 1 1 1 11d vizier-suggestion-hyperband 1 1 1 1 11d vizier-suggestion-random 1 1 1 1 11d workflow-controller 1 1 1 1 11d |
ok,通过状态我们发现现在服务启动正常,在查看下各个deployment下各个服务的pod的状态:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[root@localhost]# kubectl get pods -n kubeflow NAME READY STATUS RESTARTS AGE ambassador-c97f7b448-8qgbg 3/3 Running 1 8d ambassador-c97f7b448-bspqt 3/3 Running 1 8d ambassador-c97f7b448-vq6mn 3/3 Running 1 8d argo-ui-7495b79b59-b2hlg 1/1 Running 0 8d centraldashboard-798f8d68d5-gxx4g 1/1 Running 0 8d modeldb-backend-d69695b66-dxr44 1/1 Running 0 8d modeldb-db-975db58f7-wshd4 1/1 Running 0 8d modeldb-frontend-78ccff78b7-xr7h7 1/1 Running 0 8d mxnet-operator-6c49b767bc-nj995 1/1 Running 19 8d spartakus-volunteer-94bbd5c86-7xmfd 1/1 Running 0 8d studyjob-controller-7df5754ddf-pqqgt 1/1 Running 0 8d tf-hub-0 1/1 Running 0 8d tf-job-dashboard-7499d5cbcf-cct2q 1/1 Running 0 8d tf-job-operator-v1alpha2-644c5f7db7-v5qzc 1/1 Running 0 8d vizier-core-56dfc85cf9-qdrnt 1/1 Running 973 8d vizier-db-6bd6c6fdd5-h549q 1/1 Running 0 11d vizier-suggestion-bayesianoptimization-5d5bc5685c-x89lm 1/1 Running 0 8d vizier-suggestion-grid-5dbfc65587-vv4gs 1/1 Running 0 8d vizier-suggestion-hyperband-5d9997fb99-hr9pj 1/1 Running 0 8d vizier-suggestion-random-7fccb79977-5mggb 1/1 Running 0 8d workflow-controller-d5cb6468d-29kmf 1/1 Running 0 8d |
ok,现在服务都是正常的,接下来让我们通过Ambassador来访问kubeflow部署到k8s集群中的各个组件。
注意: 由于官方默认使用的镜像都是google镜像仓库的,所以在部署时可能出现墙的问题
访问Kubeflow UIs
由于Kubeflow使用Ambassador作为kubeflow统一的对外网关,其它的内部服务都是通过使用它来对外提供服务。具体如下图所示:

接下来我们使用kubectl的port-forwarding来对Ambassador Service进行端口转发,在本地对Kubeflow进行访问:
1 2 3 4 |
# export NAMESPACE=kubeflow
# kubectl --kubeconfig /etc/kubernetes/kubeconfig port-forward -n ${NAMESPACE} `kubectl --kubeconfig /etc/kubernetes/kubeconfig get pods -n ${NAMESPACE} --selector=service=ambassador -o jsonpath='{.items[0].metadata.name}'` 8080:80
Forwarding from 127.0.0.1:8080 -> 80
Forwarding from [::1]:8080 -> 80
|
通过浏览器进行本地localhost:8080访问:
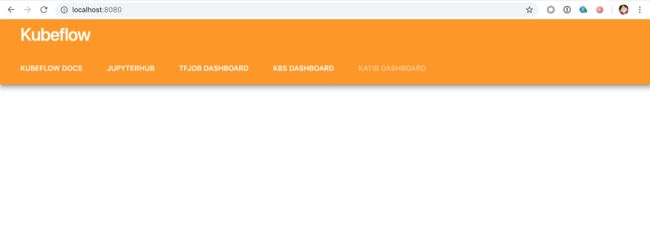
通过Kubeflow UIs可以针对不同的功能进行使用,如使用Jupyter Notebook进行对应用的全过程计算:开发、文档编写、运行代码和展示结果。

通过Kubeflow UIs访问TF-operator来对基于Tensorflow的模型进行多机多卡的分布式训练。

好了,这篇文章简单的介绍了Kubeflow及其安装流程,关于文章介绍的服务组件太多,需要自行去深入了解了,就不详细介绍了。在接下来的文章会介绍基于kubeflow对Tensorflow和MXNet模型进行多机多卡的分布式训练。
总结
现在国外的Google,微软,亚马逊,Intel以及国内的阿里云,华为云,小米云,京东云, 才云等等公司都在发力Kubeflow,并结合kubernetes对多种机器学习引擎进行多机多卡的大规模训练,这样可以做到对GPU资源的整合,并高效的提高GPU资源利用率,及模型训练的效率。并实现一站式服务,将机器学习服务上线的整个workflow都在Kubernetes平台实现。减轻机器学习算法同学的其它学习成本,专心搞算法。这势必给Devops的同学带来更高的跳挑战。相信未来Kubeflow会发展的更好。
基于 kubeflow 测试 MXNet 分布式训练
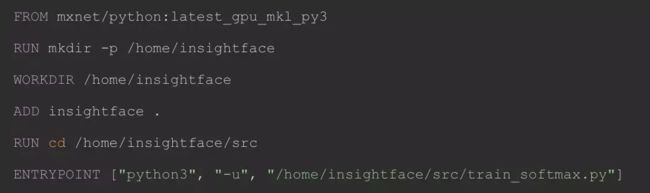
1 准备测试的训练镜像
示例代码: https://github.com/deepinsight/insightface
Dockerfile 文件内容:
2 创建分布式网络文件系统数据卷(cephfs)
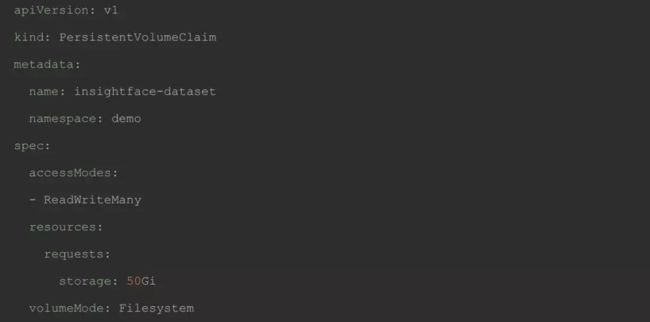
由于我们是基于 kubernetes 的 pv 和 pvc 的方式使用数据卷,所有集群中需要事先安装好 storage-class install,这样当用户创建 pvc 时,会通过 storage-class 自动的创建 pv。
当创建好 pv 之后,用户可以将该数据卷 mount 到自己的开发机上,并将需要训练的数据集移到该数据卷。用于之后创建训练 worker pod 的时候,挂载到 worker 容器中,供训练模型使用。
3 创建 mxnet 分布式训练任务
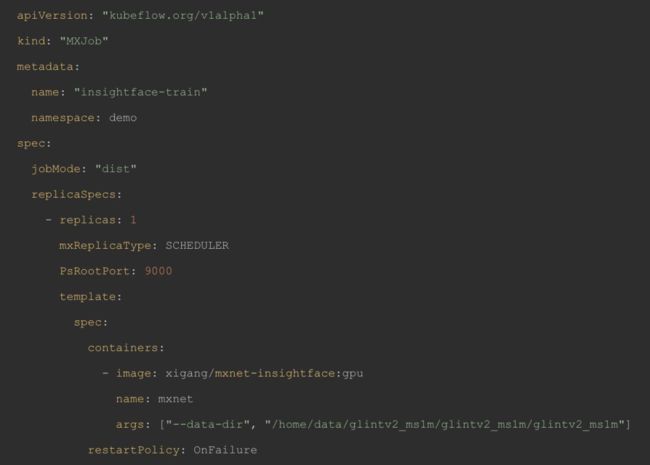
4 创建训练任务
kubectl create -f insightface-train.yaml
复制代码
5 查看任务运行情况

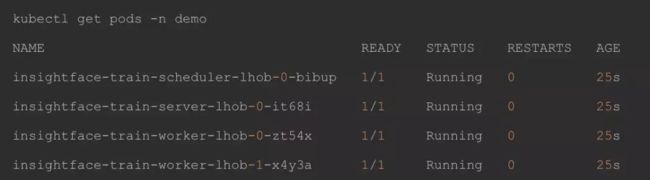
6 查看训练日志的信息
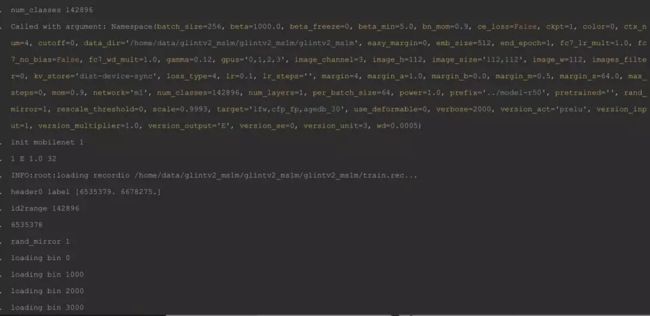
登录到具体的 node 计算节点通过 docker logs 命令查看训练的日志:
docker logs -f fc3d73161b27
复制代码
总结
虽然已经完成了 mxnet 结合 kubeflow 实现大规模的分布式训练,但是除了功能上的基本跑通,还存在很多因素影响分布式训练的性能,如: GPU 服务器的网络带宽,普通的我们使用的以太网因为通信延迟的原因,会大大影响多机扩展性。InfiniBand(IB)网络和 RoCE 网络因为支持 RDMA,大大降低了通信延迟,相比之下,20G 的以太网格延迟会大大提升。当然,对于现有的普通以太网络,也可以通过别的方法优化通信带宽的减少,比方说梯度压缩。通过梯度压缩,减少通信带宽消耗的同时,保证收敛速度和精度不会有明显下降。MXNet 官方提供了梯度压缩算法,按照官方数据,最佳的时候可以达到两倍的训练速度提升,同时收敛速度和精度的下降不会超过百分之一。还有如果使用分布式网络文件系统进行数据集的存储,如果解决吞吐量和网络延迟的问题。以及本地磁盘是否是 SSD,还是在训练时是否需要对大文件的数据集进行 record.io 文件格式的处理及训练前数据集的切分等等问题,都需要更进一步的处理。
参考
- http://stevenwhang.com/tfx_paper.pdf
- https://www.kubeflow.org/
- https://opensource.com/article/18/6/kubeflow
- https://www.oliverwyman.com/content/dam/oliver-wyman/v2/events/2018/March/Google_London_Event/Public%20Introduction%20to%20Kubeflow.pdf