深度学习中的学习率调整策略(1)
学习率(LearningRate, LR/lr)是深度学习中很重要的一个超参数了。其公式:
也就是说它是在训练过程中更新网络权重的一个调整因子,为什么说其重要呢?简单说:
- 学习率太大,梯度容易爆炸,loss的振幅较大,模型难以收敛;
- 学习率太小,容易过拟合,也容易陷入“局部最优”点;
因此选择一个合适的学习率是非常重要的。 对于新手来说,一般可能是看网上的经验或者开源代码选择一个差不多的lr(比如0.1-0.001之间)。
但是,真正用自己的数据来进行模型调试的时候就会发现,学习率也是一个非常重要的超参数,且不是那么好确定的。。。
理解了太上老君炼丹的不易。

不过还好,有大佬们想到了动态调整学习率的方法,其原理也非常简单:根据某种策略,在模型训练的过程中动态地对学习率进行调整,一般是按照某种策略进行衰减(可以想象当快要到达谷底或者山峰的时候就会放慢步伐)。
学习率调整策略
学习率调整策略在pytorch的torch.optim模块下,称其为scheduler,所以也可以说它仍然是优化器的一部分。 学习率调整一般是在优化器进行更新之后进行调整,其示例代码(来自官网):
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler = ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()
- 注意看上面的代码,其在epoch的循环中,而不是在最内层的batch循环中,因为一般是在训练了几个epoch之后调整学习率,如果是在batch中,lr更新的太快了;
对于学习率的调整,Pytorch中提供了如下14种方法(具体见参考链接【3】):
- lr_scheduler.LambdaLR
- lr_scheduler.MultiplicativeLR
- lr_scheduler.StepLR
- lr_scheduler.MultiStepLR
- lr_scheduler.ConstantLR
- lr_scheduler.LinearLR
- lr_scheduler.ExponentialLR
- lr_scheduler.CosineAnnealingLR
- lr_scheduler.ChainedScheduler
- lr_scheduler.SequentialLR
- lr_scheduler.ReduceLROnPlateau
- lr_scheduler.CyclicLR
- lr_scheduler.OneCycleLR
- lr_scheduler.CosineAnnealingWarmRestarts
具体每种方法的用法后面再讲,我们先看下一个例子的:
model = torchvision.models.AlexNet(num_classes=2)
optimizer = optim.Adam(model.parameters(),lr=0.01)
scheduler = optim.lr_scheduler.LinearLR(optimizer,start_factor=0.1, total_iters=100)
for epoch in range(100):
print(f"当前学习率:{optimizer.param_groups[0]['lr']}")
optimizer.step()
scheduler.step()
- 上面的例子使用了Adam作为优化器,然后用线性的方式在训练的过程中更新学习率;
其学习率的变化如下:
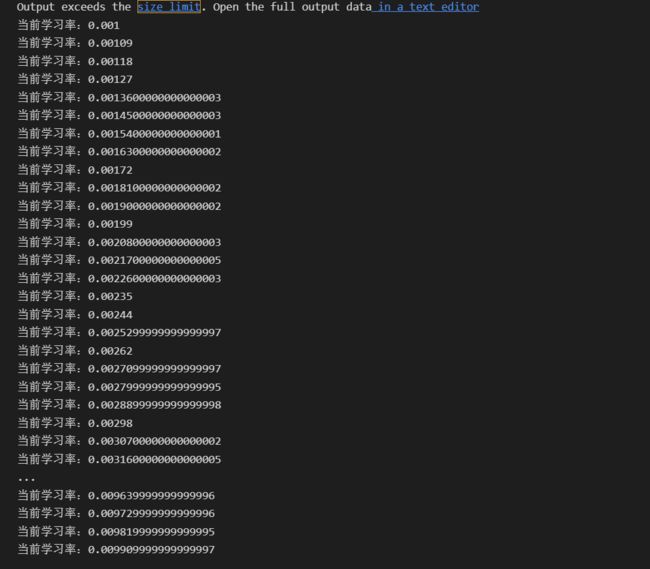
- 可以看到LinearLR的策略就是设定起始的学习率(优化器中的学习率 start_factor)和终止的学习率(默认是优化器中的学习率end_factor,end_factor默认为1.0),然后 按照total_iters把起始学习率和终止学习率确定的区间进行均分,然后每个epoch更新一次。
- 需要注意的是,当达到设定的终止学习率之后,即便还没训练完,学习率也不会再更新了。
那如果我们设置了不合适的参数,导致学习率很快就更新到头了,比如10个epoch就更新完了,但是训练一共是100个epoch怎么办?不要慌,Pytorch中的学习率更新可以进行链式调度,也就是说可以同时使用多个学习率更新策略!示例:
model = [Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer = SGD(model, 0.1)
scheduler1 = ExponentialLR(optimizer, gamma=0.9)
scheduler2 = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler1.step()
scheduler2.step()
也就是说我们可以同时使用多个策略来更新学习率,比如每训练多个epoch更新一次+loss不变化的时候再主动更新,等等。。
下篇文章详解。

参考
【1】https://zhuanlan.zhihu.com/p/41681558
【2】https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.StepLR.html
【3】https://pytorch.org/docs/stable/optim.html
【4】https://hasty.ai/content-hub/mp-wiki/scheduler/cycliclr
本文由 mdnice 多平台发布