深度学习(五):MobileNet
MobileNet经历了V1、V2、V3三个版本,俗话说得好,物竞天择,适者生存,MobileNetV3凭借其优质的性能,取代了V1和V2,本文就来详细讲讲MobileNetV3网络模型。
在了解MobileNetV3之前,还是要简单了解一下前两者为其诞生所做出的贡献。
MobileNet网络是由google团队在2017年提出的,专注于移动端或者嵌入式设备中的轻量级CNN网络。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少模型参数与运算量。(相比VGG16准确率减少了0.9%,但模型参数只有VGG的1/32)。
一、MobileNetV1的深度可分离卷积(Depthwise separable convolution)
深度可分离卷积主要分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
标准卷积如下图:卷积核的shape为(3,3,3,4) 输入三通道,对应卷积核的深度也是3。
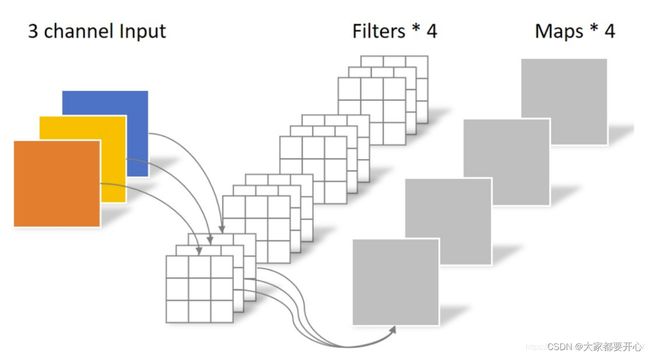
Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积,卷积操作示意如下:
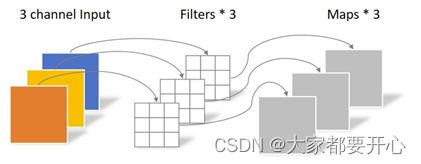
卷积核的shape为 (3,3,3)。Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。因此需要Pointwise Convolution来将这些Feature map进行组合生成新的Feature map。逐点卷积操作和常规卷积操作基本相同。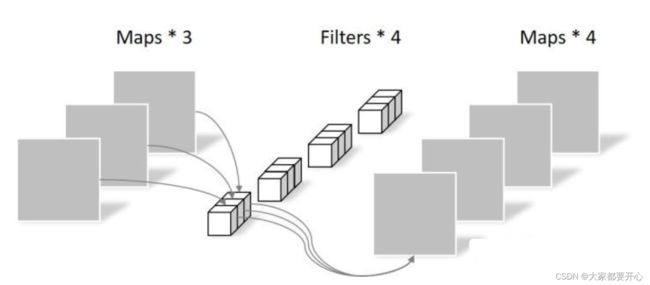
二、MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
具体步骤:先升维、卷积、再降维
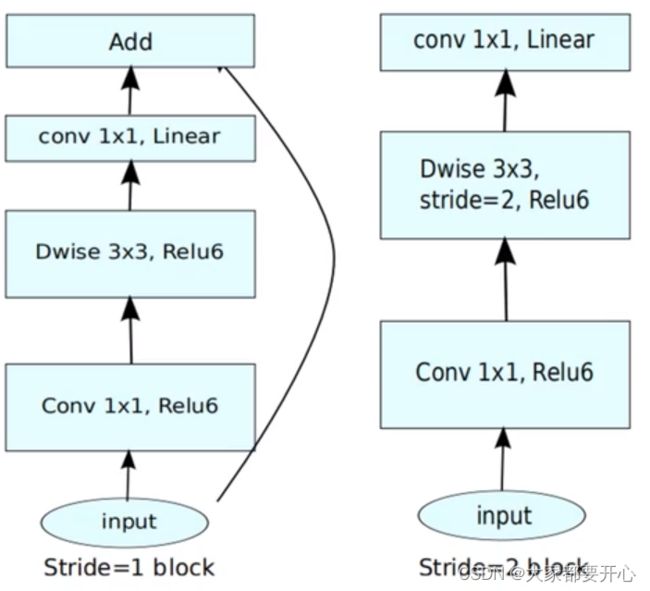
解释一下1×1卷积的作用:减少参数,增强非线性表达能力。
三、 MobileNetV3的轻量级的注意力模型、激活函数更新优化
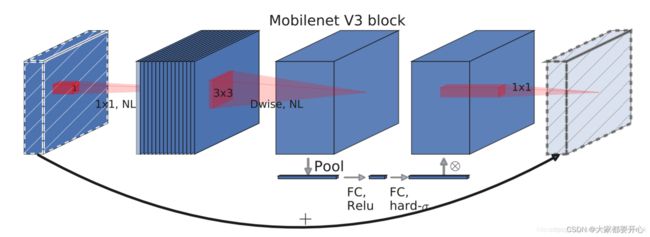
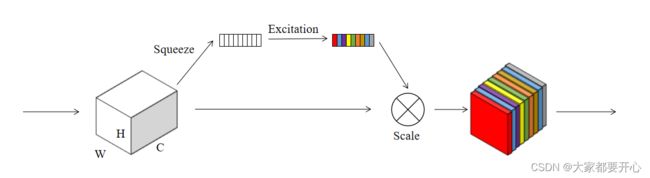
其中加入了SE注意力模块,示意图如下:
 在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。
在结构中使用了h-swishj激活函数,代替swish函数,减少运算量,提高性能。
MobileNetV3主要有MobileNetV3-Large和MobileNetV3-Small两种不同大小的网络结构。
接下来介绍一下如何用keras实现mobilenetV3
from keras.layers import Conv2D, DepthwiseConv2D, Dense, GlobalAveragePooling2D,UpSampling2D, Concatenate
from keras.layers import Activation, BatchNormalization, Add, Multiply, Reshape
from keras import backend as K
from keras.models import Model
import tensorflow as tf
# 定义relu6激活函数
def relu6(x):
return K.relu(x, max_value=6.0)
# 定义h-swish激活函数
def hard_swish(x):
return x * K.relu(x + 3.0, max_value=6.0) / 6.0
# 定义返回的激活函数是relu6还是h-swish
def return_activation(x, nl):
if nl == 'HS':
x = Activation(hard_swish)(x)
if nl == 'RE':
x = Activation(relu6)(x)
return x
# 定义卷积块(卷积+标准化+激活函数)
def conv_block(inputs, filters, kernel, strides, nl):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
x = Conv2D(filters, kernel, padding='same', strides=strides)(inputs)
x = BatchNormalization(axis=channel_axis)(x)
return return_activation(x, nl)
# 定义注意力机制模块
def SE(inputs):
input_channels = int(inputs.shape[-1])
x = GlobalAveragePooling2D()(inputs)
x = Dense(input_channels, activation='relu')(x)
x = Dense(input_channels, activation='hard_sigmoid')(x)
x = Reshape((1, 1, input_channels))(x)
x = Multiply()([inputs, x])
return x
def bottleneck(inputs, filters, kernel, e, s, squeeze, nl,alpha=1.0):
channel_axis = 1 if K.image_data_format() == 'channels_first' else -1
input_shape = K.int_shape(inputs)
tchannel = int(e)
cchannel = int(alpha * filters)
r = s == 1 and input_shape[3] == filters
x = conv_block(inputs, tchannel, (1,1), (1,1), nl)
x = DepthwiseConv2D(kernel, strides=(s,s), depth_multiplier=1, padding='same')(x)
x = BatchNormalization(axis=channel_axis)(x)
x = return_activation(x,nl)
if squeeze:
x = SE(x)
x = Conv2D(cchannel, (1,1), strides=(1,1), padding='same')(x)
x = BatchNormalization(axis=channel_axis)(x)
if r:
x = Add()([x, inputs])
return x
def MobileNetV3_Large(inputs, alpha=1.0):
# conv2d_1 (Conv2D) - activation_1 (Activation)
x = conv_block(inputs, 16, (3,3), strides=(2,2), nl='HS')
# conv2d_2 (Conv2D) - add_1 (Add)
x = bottleneck(x, 16, (3, 3), e=16, s=1, squeeze=False, nl='RE', alpha=alpha)
# conv2d_4 (Conv2D) - batch_normalization_7
x = bottleneck(x, 24, (3, 3), e=64, s=2, squeeze=False, nl='RE', alpha=alpha)
# conv2d_6 (Conv2D) - add_2 (Add)
x = bottleneck(x, 24, (3, 3), e=72, s=1, squeeze=False, nl='RE', alpha=alpha)
# conv2d_8 (Conv2D) - batch_normalization_13
x = bottleneck(x, 40, (5, 5), e=72, s=2, squeeze=True, nl='RE', alpha=alpha)
# conv2d_10 (Conv2D) - add_3 (Add)
x = bottleneck(x, 40, (5, 5), e=120, s=1, squeeze=True, nl='RE', alpha=alpha)
# conv2d_12 (Conv2D) - add_4 (Add) (None, 52, 52, 40) 70层
x = bottleneck(x, 40, (5, 5), e=120, s=1, squeeze=True, nl='RE', alpha=alpha)
# conv2d_14 (Conv2D) - batch_normalization_22 (None, 26, 26, 80)
x = bottleneck(x, 80, (3, 3), e=240, s=2, squeeze=False, nl='HS', alpha=alpha)
# conv2d_16 (Conv2D) - add_5 (Add) (None, 26, 26, 80)
x = bottleneck(x, 80, (3, 3), e=200, s=1, squeeze=False, nl='HS', alpha=alpha)
# conv2d_18 (Conv2D) - add_6 (Add)
x = bottleneck(x, 80, (3, 3), e=184, s=1, squeeze=False, nl='HS', alpha=alpha)
# conv2d_20 (Conv2D) - add_7 (Add) (None, 26, 26, 80)
x = bottleneck(x, 80, (3, 3), e=184, s=1, squeeze=False, nl='HS', alpha=alpha)
# conv2d_22 (Conv2D) - batch_normalization_34 (None, 26, 26, 112)
# inputs=(26,26,80) filtters=112 所以没有Add
x = bottleneck(x, 112, (3, 3), e=480, s=1, squeeze=True, nl='HS', alpha=alpha)
# conv2d_24 (Conv2D) - add_8 (Add) (None, 26, 26, 112) 132层
x = bottleneck(x, 112, (3, 3), e=672, s=1, squeeze=True, nl='HS', alpha=alpha)
# conv2d_26 (Conv2D) - batch_normalization_40 (None, 13, 13, 160)
x = bottleneck(x, 160, (5, 5), e=672, s=2, squeeze=True, nl='HS', alpha=alpha)
# conv2d_28 (Conv2D) - add_9 (Add) (None, 13, 13, 160)
x = bottleneck(x, 160, (5, 5), e=960, s=1, squeeze=True, nl='HS', alpha=alpha)
# conv2d_30 (Conv2D) - add_10 (Add) (None, 13, 13, 160)
x = bottleneck(x, 160, (5, 5), e=960, s=1, squeeze=True, nl='HS', alpha=alpha)
model = Model(inputs, x)
return model
def MobileNetV3_Small(inputs, alpha=1.0):
x = conv_block(inputs, 16, (3, 3), strides=(2, 2), nl='HS')
x = bottleneck(x, 16, (3, 3), e=16, s=2, squeeze=True, nl='RE', alpha=alpha)
x = bottleneck(x, 24, (3, 3), e=72, s=2, squeeze=False, nl='RE', alpha=alpha)
x = bottleneck(x, 24, (3, 3), e=88, s=1, squeeze=False, nl='RE', alpha=alpha)
x = bottleneck(x, 40, (5, 5), e=96, s=2, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 40, (5, 5), e=240, s=1, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 40, (5, 5), e=240, s=1, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 48, (5, 5), e=120, s=1, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 48, (5, 5), e=144, s=1, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 96, (5, 5), e=288, s=2, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 96, (5, 5), e=576, s=1, squeeze=True, nl='HS', alpha=alpha)
x = bottleneck(x, 96, (5, 5), e=576, s=1, squeeze=True, nl='HS', alpha=alpha)
model = Model(inputs, x)
return model