【从零开始学习深度学习】14. 防止过拟合方法:Dropout方法介绍及示例演示
除了上一篇文章中介绍的权重衰减以外,深度学习模型常常使用丢弃法(dropout)来应对过拟合问题。丢弃法有一些不同的变体。本节中提到的丢弃法特指
倒置丢弃法(inverted dropout)。
目录
- 1 Dropout丢弃法
-
- 1.1 方法
- 1.2 从零开始实现带dropout的
-
- 1.2.1 定义模型参数
- 1.2.2 定义模型
- 1.2.3 训练和测试模型
- 1.3 Dropout在Pytorch中的简洁实现
- 总结
1 Dropout丢弃法
1.1 方法
现有一个单隐藏层的多层感知机:其中输入个数为4,隐藏单元个数为5,且隐藏单元 h i h_i hi( i = 1 , … , 5 i=1, \ldots, 5 i=1,…,5)的计算表达式为
h i = ϕ ( x 1 w 1 i + x 2 w 2 i + x 3 w 3 i + x 4 w 4 i + b i ) h_i = \phi\left(x_1 w_{1i} + x_2 w_{2i} + x_3 w_{3i} + x_4 w_{4i} + b_i\right) hi=ϕ(x1w1i+x2w2i+x3w3i+x4w4i+bi)
这里 ϕ \phi ϕ是激活函数, x 1 , … , x 4 x_1, \ldots, x_4 x1,…,x4是输入,隐藏单元 i i i的权重参数为 w 1 i , … , w 4 i w_{1i}, \ldots, w_{4i} w1i,…,w4i,偏差参数为 b i b_i bi。当对该隐藏层使用丢弃法时,该层的隐藏单元将有一定概率被丢弃掉。设丢弃概率为 p p p,那么有 p p p的概率 h i h_i hi会被清零,有 1 − p 1-p 1−p的概率 h i h_i hi会除以 1 − p 1-p 1−p做拉伸。丢弃概率是丢弃法的超参数。具体来说,设随机变量 ξ i \xi_i ξi为0和1的概率分别为 p p p和 1 − p 1-p 1−p。使用丢弃法时我们计算新的隐藏单元 h i ′ h_i' hi′
h i ′ = ξ i 1 − p h i h_i' = \frac{\xi_i}{1-p} h_i hi′=1−pξihi
由于 E ( ξ i ) = 1 − p E(\xi_i) = 1-p E(ξi)=1−p,因此
E ( h i ′ ) = E ( ξ i ) 1 − p h i = h i E(h_i') = \frac{E(\xi_i)}{1-p}h_i = h_i E(hi′)=1−pE(ξi)hi=hi
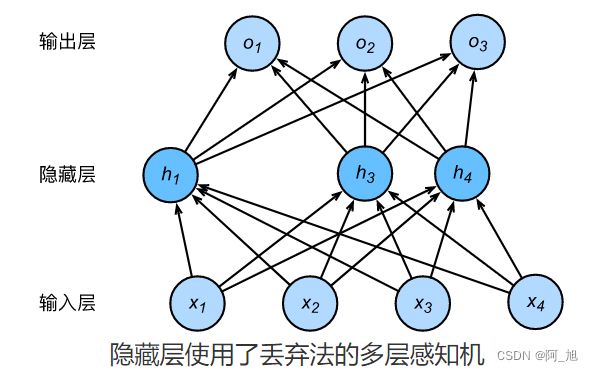
即丢弃法不改变其输入的期望值。让我们对全连接的隐藏层使用丢弃法,一种可能的结果如下图所示,其中 h 2 h_2 h2和 h 5 h_5 h5被清零。这时输出值的计算不再依赖 h 2 h_2 h2和 h 5 h_5 h5,在反向传播时,与这两个隐藏单元相关的权重的梯度均为0。由于在训练中隐藏层神经元的丢弃是随机的,即 h 1 , … , h 5 h_1, \ldots, h_5 h1,…,h5都有可能被清零,输出层的计算无法过度依赖 h 1 , … , h 5 h_1, \ldots, h_5 h1,…,h5中的任一个,从而在训练模型时起到正则化的作用,并可以用来应对过拟合。在测试模型时,我们为了拿到更加确定性的结果,一般不使用丢弃法。
1.2 从零开始实现带dropout的
根据丢弃法的定义,下面我们去实现它。下面的dropout函数将以drop_prob的概率丢弃X中的元素。
%matplotlib inline
import torch
import torch.nn as nn
import numpy as np
import sys
import d2lzh_pytorch as d2l
def dropout(X, drop_prob):
X = X.float()
assert 0 <= drop_prob <= 1
keep_prob = 1 - drop_prob
# 这种情况下把全部元素都丢弃
if keep_prob == 0:
return torch.zeros_like(X)
# torch.rand,【0,1)的均匀分布
mask = (torch.rand(X.shape) < keep_prob).float()
return mask * X / keep_prob
我们运行几个例子来测试一下dropout函数。其中丢弃概率分别为0、0.5和1。

1.2.1 定义模型参数
实验中,我们依然使用Fashion-MNIST数据集。我们将定义一个包含两个隐藏层的多层感知机,其中两个隐藏层的输出个数都是256。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
W1 = torch.tensor(np.random.normal(0, 0.01, size=(num_inputs, num_hiddens1)), dtype=torch.float, requires_grad=True)
b1 = torch.zeros(num_hiddens1, requires_grad=True)
W2 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens1, num_hiddens2)), dtype=torch.float, requires_grad=True)
b2 = torch.zeros(num_hiddens2, requires_grad=True)
W3 = torch.tensor(np.random.normal(0, 0.01, size=(num_hiddens2, num_outputs)), dtype=torch.float, requires_grad=True)
b3 = torch.zeros(num_outputs, requires_grad=True)
params = [W1, b1, W2, b2, W3, b3]
1.2.2 定义模型
下面定义的模型将全连接层和激活函数ReLU串起来,并对每个激活函数的输出使用丢弃法。我们可以分别设置各个层的丢弃概率。通常的建议是把靠近输入层的丢弃概率设得小一点。在这个实验中,我们把第一个隐藏层的丢弃概率设为0.2,把第二个隐藏层的丢弃概率设为0.5。我们可以通过参数is_training来判断运行模式为训练还是测试,并只需在训练模式下使用丢弃法。
drop_prob1, drop_prob2 = 0.2, 0.5
def net(X, is_training=True):
X = X.view(-1, num_inputs)
H1 = (torch.matmul(X, W1) + b1).relu()
if is_training: # 只在训练模型时使用丢弃法
H1 = dropout(H1, drop_prob1) # 在第一层全连接后添加丢弃层
H2 = (torch.matmul(H1, W2) + b2).relu()
if is_training:
H2 = dropout(H2, drop_prob2) # 在第二层全连接后添加丢弃层
return torch.matmul(H2, W3) + b3
模型评估的evaluate_accuracy函数:
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else: # 自定义的模型
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
1.2.3 训练和测试模型
这部分与之前多层感知机的训练和测试类似。
num_epochs, lr, batch_size = 5, 100.0, 256
loss = torch.nn.CrossEntropyLoss()
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
输出:
epoch 1, loss 0.0044, train acc 0.574, test acc 0.648
epoch 2, loss 0.0023, train acc 0.786, test acc 0.786
epoch 3, loss 0.0019, train acc 0.826, test acc 0.825
epoch 4, loss 0.0017, train acc 0.839, test acc 0.831
epoch 5, loss 0.0016, train acc 0.849, test acc 0.850
1.3 Dropout在Pytorch中的简洁实现
在PyTorch中,我们只需要在全连接层后添加Dropout层并指定丢弃概率。在训练模型时,Dropout层将以指定的丢弃概率随机丢弃上一层的输出元素;在测试模型时(即model.eval()后),Dropout层并不发挥作用。
net = nn.Sequential(
d2l.FlattenLayer(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(drop_prob1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(drop_prob2),
nn.Linear(num_hiddens2, 10)
)
for param in net.parameters():
nn.init.normal_(param, mean=0, std=0.01)
下面训练并测试模型。
optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, None, None, optimizer)
输出:
epoch 1, loss 0.0045, train acc 0.553, test acc 0.715
epoch 2, loss 0.0023, train acc 0.784, test acc 0.793
epoch 3, loss 0.0019, train acc 0.822, test acc 0.817
epoch 4, loss 0.0018, train acc 0.837, test acc 0.830
epoch 5, loss 0.0016, train acc 0.848, test acc 0.839
总结
- 我们可以通过使用丢弃法应对过拟合。
- 丢弃法只在训练模型时使用,在进行模型评估时不使用。
如果内容对你有帮助,感谢点赞+关注哦!
关注下方GZH:阿旭算法与机器学习,可获取更多干货内容~欢迎共同学习交流